An XPath query operates on a namespace well-formed XML document after it has been parsed into a tree structure. The particular tree model XPath uses divides each XML document into seven kinds of nodes:
- root node
The document itself. The root node’s children are the comments and processing instructions in the prolog and epilog and the root element of the document.
- element node
An element. Its children are all the child elements, text nodes, comments, and processing instructions the element contains. An element also has namespaces and attributes. However, these are not child nodes.
- attribute node
An attribute other than one that declares a namespace
- text node
The maximum uninterrupted run of text between tags, comments, and processing instructions. White space is included.
- comment node
A comment
- processing instruction node
A processing instruction
- namespace node
A namespace mapping in scope on an element
The XPath data model does not include entity references, CDATA sections, or the document type declaration. Entity references are resolved into their component text and elements. CDATA sections are treated like any other text, and will be merged with any adjacent text before a text node is formed. Default attributes are applied, but otherwise the document type declaration is not considered.
In the XPath data model each node has a string-value Furthermore, attributes, elements, processing instructions, and namespace nodes have expanded names, which are divided into a local part and a namespace URI. Table 16.1 summarizes XPath’s rules for calculating names and values for its seven node types.
Table 16.1. XPath Expanded Names and String-values
| Node type | Local name | Namespace name | String-value |
|---|---|---|---|
| root | None | None | the complete, ordered content of all text nodes in the document; same as the value of the root element of the document |
| element | The name of the element, not including any prefix or colon | The namespace URI of the element | The complete, ordered content of all text node descendants of this element (i.e. the text that’s left after all references are resolved and all other markup is stripped out.) |
| attribute | The name of the attribute, not including any prefix or colon | The namespace URI of the attribute | The normalized attribute value |
| text | None | None | The complete content of the text node |
| processing instruction | The target of the processing instruction | None | The processing instruction data |
| comment | None | None | The text of the comment |
| namespace | The prefix for the namespace | None | The absolute URI for the namespace |
If an XPath function such as local-name() or namespace-uri() attempts to retrieve the value of one of these properties for a node that doesn’t have that property, it returns the empty string.
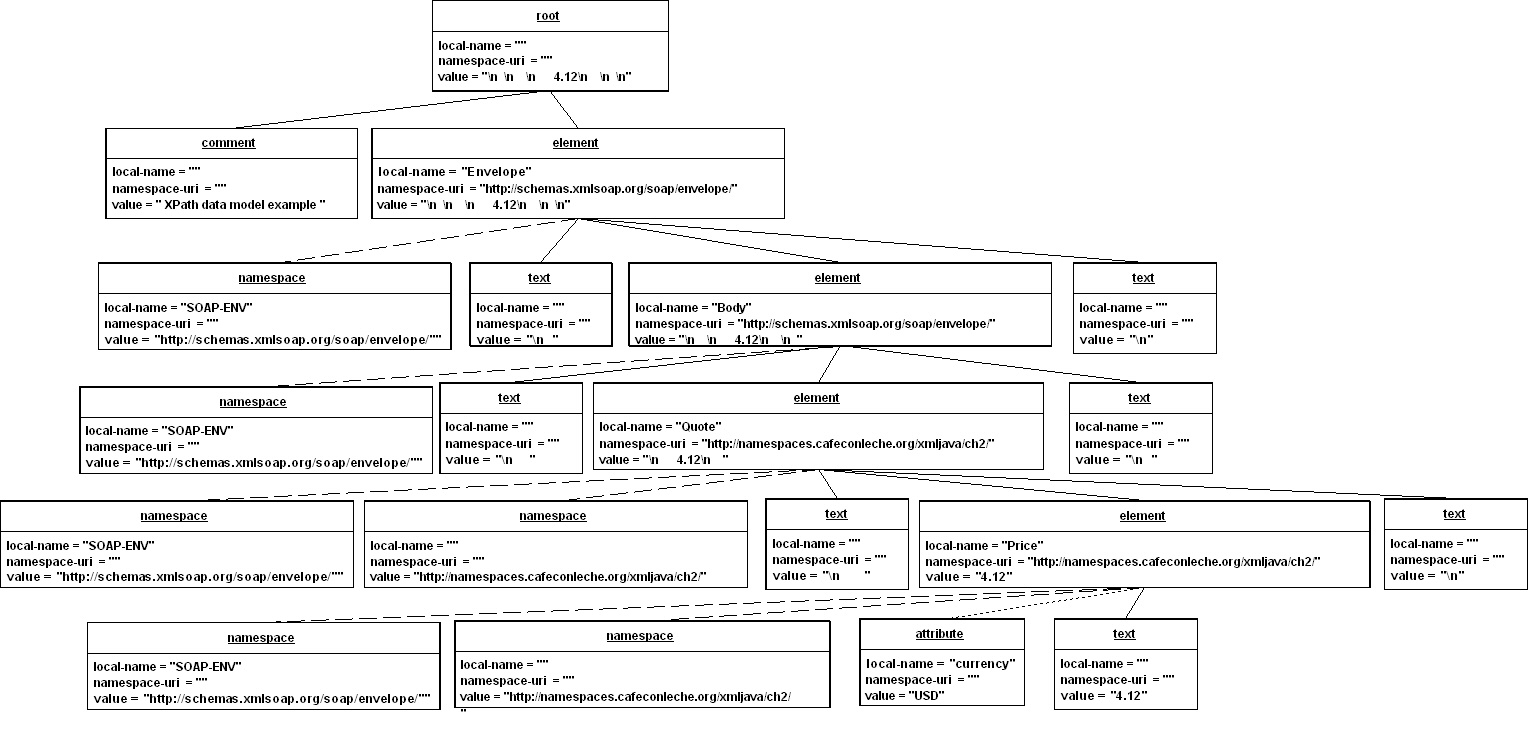
An diagram and example should help explain this. Consider the simple SOAP response document in Example 16.2.
Example 16.2. A SOAP response document
<?xml version="1.0"?>
<!-- XPath data model example -->
<SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" />
<SOAP-ENV:Body>
<Quote
xmlns="http://namespaces.cafeconleche.org/xmljava/ch2/">
<Price currency="USD">4.12</Price>
</Quote>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
Figure 16.2 is a UML object diagram that identifies the connections between and properties of the different XPath nodes in this document. Solid lines indicate a child relationship. Dashed and dotted lines indicate namespace and attribute connections respectively. Document order runs from top to bottom and left-to-right (although the exact order of namespace nodes and attribute nodes attached to the same element is implementation dependent). One thing to note is that white space is significant in the XPath data model. Line breaks are indicated by \n in this figure.
The differences between the XPath and DOM data models The XPath data model is similar to, but not quite the same as the DOM data model. The most important differences relate to the names and values of` nodes. In XPath, only attributes, elements, processing instructions, and namespace nodes have names, which are divided into a local part and a namespace URI. XPath does not use pseudo-names like #document and #comment. The other big difference is that in XPath the value of an element or root node is the concatenation of the values of all its text node descendants, not null as it is in DOM. For example, the XPath value of <p>Hello</p> is the string Hello and the XPath value of <p>Hello<em>Goodbye</em></p> is the string HelloGoodbye. Other differences between the DOM and XPath data models include:
|