By this point, you may have noticed a problem with the XMLFilter interface. It filters calls from the client application to the parser. However, most events are passed in the other direction from the parser to the client application through the various callback interfaces, especially ContentHandler. XMLFilter is set up exactly backwards for filtering these events. It filters calls from the client application to the parser, but not the much more important calls from the parser to the client application!
However, it’s possible to work around this. First intercept the handlers passed to methods like setContentHandler() and setDTDHandler(). Then replace them with handlers of your own so that your handlers receive the callback events from the parent parser. They can either pass them along to the client application’s handler methods or pass something different instead.
For example, let’s suppose you want to convert a RDDL document to pure XHTML. RDDL, the Resource Directory Description Language, is used for human and machine readable documents placed at the end of namespace URLs. RDDL is actually quite close to XHTML to begin with. It’s just an XHTML Basic document in which there’s one extra element, rddl:resource, which can appear anywhere a p element can appear, and can contain anything a div element can contain. The customary rddl prefix is mapped to the http://www.rddl.org/ namespace URL, and as usual the prefix can change as long as the URL remains the same. For example, this is a rddl:resource from the RDDL specification itself:
<rddl:resource id="rec-xhtml"
xlink:title="W3C REC XHTML"
xlink:role="http://www.w3.org/1999/xhtml"
xlink:arcrole="http://www.rddl.org/purposes#reference"
xlink:href="http://www.w3.org/tr/xhtml1"
>
<li><a href="http://www.w3.org/tr/xhtml1">W3C XHTML 1.0</a></li>
</rddl:resource>The filter needs to throw away the <rddl:resource> start-tag and </rddl:resource> end-tag while leaving everything else intact. Example 8.6 does this. The startElement() and endElement() methods pass everything except rddl:resource tags to the parent’s ContentHandler. However, rddl:resource tags are just dropped on the floor.
Example 8.6. A ContentHandler filter
import org.xml.sax.*;
public class RDDLStripper implements ContentHandler {
public final static String RDDL_NAMESPACE
= "http://www.rddl.org/";
public final static String XHTML_NAMESPACE
= "http://www.w3.org/1999/xhtml";
private ContentHandler parent;
public RDDLStripper(ContentHandler parent) {
this.parent = parent;
}
// Filter out <rddl:resource> start-tags
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
if (localName.equals("resource")
&& namespaceURI.equals(RDDL_NAMESPACE)) {
return; // having done nothing
}
else { // pass the element along
parent.startElement(namespaceURI, localName, qualifiedName,
atts);
}
}
// Filter out </rddl:resource> end-tags
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
if (localName.equals("resource")
&& namespaceURI.equals(RDDL_NAMESPACE)) {
return; // having done nothing
}
else {
parent.endElement(namespaceURI, localName, qualifiedName);
}
}
// Methods that pass data along unchanged:
public void startDocument() throws SAXException {
parent.startDocument();
}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
parent.startPrefixMapping(prefix, uri);
}
public void endPrefixMapping(String prefix)
throws SAXException {
parent.endPrefixMapping(prefix);
}
public void setDocumentLocator(Locator locator) {
parent.setDocumentLocator(locator);
}
public void endDocument() throws SAXException {
parent.endDocument();
}
public void characters(char[] text, int start, int length)
throws SAXException {
parent.characters(text, start, length);
}
public void ignorableWhitespace(char[] text, int start,
int length) throws SAXException {
parent.ignorableWhitespace(text, start, length);
}
public void processingInstruction(String target, String data)
throws SAXException {
parent.processingInstruction(target, data);
}
public void skippedEntity(String name)
throws SAXException {
parent.skippedEntity(name);
}
}
The next step is to install a RDDLStripper as an XMLFilter’s ContentHandler. Example 8.7 does this. It’s just a slight variation on the earlier TransparentFilter. Here, however, the setContentHandler() method installs a RDDLStripper. [1]
Example 8.7. A filter that substitutes its own ContentHandler
import org.xml.sax.*;
import java.io.IOException;
public class RDDLFilter implements XMLFilter {
private XMLReader parent;
public void setParent(XMLReader parent) {
this.parent = parent;
}
public XMLReader getParent() {
return this.parent;
}
public void setContentHandler(ContentHandler handler) {
parent.setContentHandler(new RDDLStripper(handler));
}
// Transparent pass-along methods
public ContentHandler getContentHandler() {
return parent.getContentHandler();
}
public boolean getFeature(String name)
throws SAXNotRecognizedException, SAXNotSupportedException {
return parent.getFeature(name);
}
public void setFeature(String name, boolean value)
throws SAXNotRecognizedException, SAXNotSupportedException {
parent.setFeature(name, value);
}
public Object getProperty(String name)
throws SAXNotRecognizedException, SAXNotSupportedException {
return parent.getProperty(name);
}
public void setProperty(String name, Object value)
throws SAXNotRecognizedException, SAXNotSupportedException {
parent.setProperty(name, value);
}
public void setEntityResolver(EntityResolver resolver) {
parent.setEntityResolver(resolver);
}
public EntityResolver getEntityResolver() {
return parent.getEntityResolver();
}
public void setDTDHandler(DTDHandler handler) {
parent.setDTDHandler(handler);
}
public DTDHandler getDTDHandler() {
return parent.getDTDHandler();
}
public void setErrorHandler(ErrorHandler handler) {
parent.setErrorHandler(handler);
}
public ErrorHandler getErrorHandler() {
return parent.getErrorHandler();
}
public void parse(InputSource input)
throws SAXException, IOException {
parent.parse(input);
}
public void parse(String systemId)
throws SAXException, IOException {
parent.parse(systemId);
}
}
The final step is to write a client application which uses this filter to read XHTML and/or RDDL documents. Whichever kind you feed it, the client app should only see XHTML. For this client application, I’m going to use a ContentHandler that just prints the result on System.out. More specifically, I’m going to use David Megginson’s public domain com.megginson.sax.XMLWriter class. This class not only implements ContentHandler. It’s also an XMLFilter. However, since it uses a few features we haven’t discussed yet, detailed analysis of this class will have to wait a bit. In the meantime, all you really need to know is that XMLWriter logs all events the parser fires to a specified java.io.Writer in a well-formed way.
Example 8.8 demonstrates with a driver program that parses a document named by the first command line argument using the XMLFilter class named by the second command line argument. This test program will allow us to inspect the output of various filters in this chapter.
Example 8.8. A program that filters documents
import org.xml.sax.*;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.*;
import com.megginson.sax.XMLWriter;
public class FilterTester {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println(
"Usage: java FilterTester URL FilterClass");
return;
}
String document = args[0];
String filterClass = args[1];
try {
XMLFilter filter
= (XMLFilter) Class.forName(filterClass).newInstance();
filter.setParent(XMLReaderFactory.createXMLReader());
filter.setContentHandler(
new XMLWriter(new OutputStreamWriter(System.out))
);
filter.parse(document);
}
catch (SAXException e) {
e.printStackTrace();
System.out.println(e);
}
catch (IOException e) {
e.printStackTrace();
System.out.println(
"Due to an IOException, the parser could not read "
+ args[0]
);
}
catch (ClassCastException e) {
System.out.println(filterClass
+ " does not implement org.xml.sax.XMLFilter");
}
catch (ClassNotFoundException e) {
System.out.println(filterClass
+ " cannot be found in the CLASSPATH");
}
catch (InstantiationException e) {
System.out.println(filterClass
+ " does not have a no-args constructor");
}
catch (Exception e) {
System.err.println(e);
}
}
}
For example, here’s the actual last few lines of the RDDL specification (modulo the usual white space adjustments):
<rddl:resource
id="note-xlink2rdf"
xlink:title="W3C NOTE XLink2RDF"
xlink:role="http://www.w3.org/TR/html4/"
xlink:arcrole="http://www.rddl.org/purposes#reference"
xlink:href="http://www.w3.org/TR/xlink2rdf/"
>
<li><a href="http://www.w3.org/TR/xlink2rdf/">W3C Note Harvesting
RDF Statements from XLinks</a></li>
</rddl:resource>
<rddl:resource
id="rec-modxhtml"
xlink:title="W3C REC Modularization for XHTML"
xlink:role="http://www.w3.org/1999/xhtml"
xlink:arcrole="http://www.rddl.org/purposes#reference"
xlink:href="http://www.w3.org/TR/xhtml-modularization/"
>
<li><a href="http://www.w3.org/TR/xhtml-modularization/">W3C
Modularization of XHTML</a></li>
</rddl:resource>
</ol>
</div>
</body>
</html>Now here’s some of the output when the RDDL specification was passed through this program. The rddl:resource tags have been removed:
% java -Dorg.xml.sax.driver=org.apache.xerces.parsers.SAXParser
FilterTester http://www.rddl.org/ RDDLFilter
...
<li><a href="http://www.w3.org/TR/xlink2rdf/">W3C Note
Harvesting RDF Statements from XLinks</a></li>
<li><a href="http://www.w3.org/TR/xhtml-modularization/">
W3C Modularization of XHTML</a></li>
</ol>
</div>
</body>
</html>The pattern followed here is pretty much exactly what was shown in Figure 8.2. If we revise that figure to include the specific class names used here, what you have is shown in Figure 8.4.
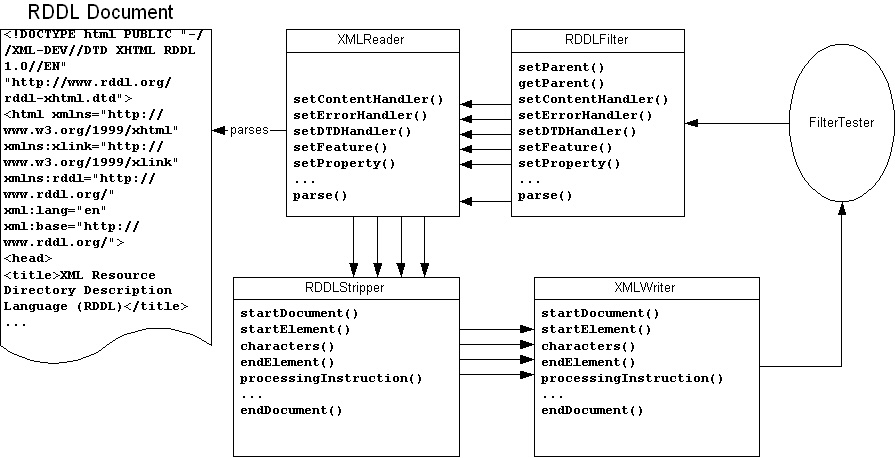
Because SAX operates in a linear rather than hierarchical fashion, filtering the start-tag and end-tag of each rddl:resource element does not filter the contents of the rddl:resource element. In this case, that’s exactly what we want. RDDL is a little unusual in that it both contains and is contained in XHTML. Most applications that get mixed with XHTML such as SVG and MathML are contained in XHTML but do not themselves contain XHTML.
It’s easy enough to drop out any elements and that are not in the XHTML namespace. However, in the case of SVG, MathML and most other applications you’ll want to remove the content of these elements as well. I’ll assume that the namespace for text is the same as the namespace of the parent element. (This is not at all clear from the namespaces specification, but it makes sense in many cases.) To track the nearest namespace for non-elements, startElement() will push the element’s namespace onto a stack and endElement() will pop it off. Peeking at the top of the stack will tell you what namespace the nearest element uses. You can’t use NamespaceSupport() or startPrefixMapping() and endPrefixMapping() here because those track namespace declarations rather than the actual namespaces used. Example 8.9 is the ContentHandler that accomplishes this.
Example 8.9. A ContentHandler filter that throws away non-XHTML elements
import org.xml.sax.*;
import java.util.*;
public class PureXHTMLHandler implements ContentHandler {
public final static String XHTML_NAMESPACE
= "http://www.w3.org/1999/xhtml";
private ContentHandler parent;
private Stack namespaces; // initialized in startDocument()
public PureXHTMLHandler(ContentHandler parent) {
this.parent = parent;
}
// Filter out anything that's not in the XHTML namespace
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
namespaces.push(namespaceURI);
if (namespaceURI.equals(XHTML_NAMESPACE)) {
parent.startElement(namespaceURI, localName, qualifiedName,
atts);
}
// else do nothing
}
// Filter out anything that's not in the XHTML namespace
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
namespaces.pop();
if (namespaceURI.equals(XHTML_NAMESPACE)) {
parent.endElement(namespaceURI, localName, qualifiedName);
}
// else do-nothing
}
// simple utility method to determine whether or not the parent
// element is an XHTML element
private boolean inXHTML() {
try {
String namespace = (String) namespaces.peek();
if (namespace.equals(XHTML_NAMESPACE)) return true;
return false;
}
catch (EmptyStackException e) {
// This means we're outside the root element in a
// processing instruction. Such processing instructions are
// legal in XHTML so I keep it.
return true;
}
}
public void characters(char[] text, int start, int length)
throws SAXException {
if (inXHTML()) parent.characters(text, start, length);
}
public void ignorableWhitespace(char[] text, int start,
int length) throws SAXException {
if (inXHTML()) parent.ignorableWhitespace(text, start, length);
}
public void processingInstruction(String target, String data)
throws SAXException {
if (inXHTML()) parent.processingInstruction(target, data);
}
public void skippedEntity(String name)
throws SAXException {
if (inXHTML()) parent.skippedEntity(name);
}
// I could track namespace declarations with these next two
// methods and only pass along those for XHTML. However,
// that is quite tricky because the endPrefixMapping()
// method only reports the prefix, not the URI.
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
parent.startPrefixMapping(prefix, uri);
}
public void endPrefixMapping(String prefix)
throws SAXException {
parent.endPrefixMapping(prefix);
}
// Methods that pass data along unchanged:
public void startDocument() throws SAXException {
namespaces = new Stack();
parent.startDocument();
}
public void endDocument() throws SAXException {
parent.endDocument();
}
public void setDocumentLocator(Locator locator) {
parent.setDocumentLocator(locator);
}
}
One thing to consider: what happens when a non-XHTML document such as a pure SVG or MathML document is passed through this filter? In other words, what if the root element is not an XHTML element? In this case, the entire document, except perhaps for a few comments and processing instructions that precede or follow the root element, is filtered out. The resulting document does not have a root element. It is thus not well-formed!
Believe it or not, there is no prohibition against this. XML documents must be well-formed, but the only normative definition of an XML document is as a sequence of characters. Here we no longer have a sequence of characters. Instead we have a sequence of method invocations. If those method invocations are coming straight from a parsed XML document, then there are certain guarantees of well-formedness such as there being a single root element. However, if you’re a little further removed from the actual XML document, these guarantees no longer hold. Indeed filters can do considerably weirder things like passing along startElement() calls but blocking the corresponding endElement() calls or passing non-whitespace characters to the ignorableWhiteSpace() method. If your applications have reason to do things like this, go ahead; but document the filter’s behavior exhaustively and be very careful about the client applications that receive data from your filter. Filters can very easily violate a handler’s implicit preconditions with predictably disastrous results.
Attributes can be filtered very straightforwardly in the startElement() method. Unlike element content, the complete set of attributes for any element is completely available a single method call as an Attributes object. Thus it’s easy to read through the list and respond appropriately without building complicated data structures to maintain state between method invocations.
The only mildly tricky part is that the Attributes interface is read-only. It provides numerous getter methods but no corresponding setter methods. Thus if you want to do anything other than forward the original Attributes object along unchanged, you’ll need to create your own object that implements the Attributes interface and is mutable. While doing so would be a simple matter of programming, most of the time it’s easier to use the class SAX provides for this purpose, org.xml.sax.helpers.AttributesImpl, summarized in Example 8.10. This class implements the Attributes interface and adds methods for copying existing Attributes objects and adding attributes to and deleting attributes from the list. This class is quite useful when writing filters that process attributes.
Example 8.10. The AttributesImpl helper class
package org.xml.sax.helpers;
public class AttributesImpl implements Attributes {
public AttributesImpl();
public AttributesImpl(Attributes atts);
public int getLength();
public String getURI(int index);
public String getLocalName(int index);
public String getQualifiedName(int index);
public String getType(int index);
public String getValue(int index);
public int getIndex(String uri, String localName);
public int getIndex(String qualifiedName);
public String getType(String uri, String localName);
public String getType(String qualifiedName);
public String getValue(String uri, String localName);
public String getValue(String qualifiedName);
public void clear();
public void setAttributes(Attributes atts);
public void addAttribute(String uri, String localName,
String qualifiedName, String type, String value);
public void setAttribute(int index, String uri,
String localName, String qualifiedName, String type,
String value);
public void removeAttribute(int index);
public void setURI(int index, String uri);
public void setLocalName(int index, String localName);
public void setQualifiedName(int index, String qualifiedName);
public void setType(int index, String type);
public void setValue(int index, String value);
}
As an example, let’s extend the pure XHTML filter of Example 8.9 to remove non-XHTML attributes such as xlink:href from XHTML elements. XHTML attributes are always in no namespace, so we can just drop out any attributes that are in a namespace. The only exception to this are the three xml: attributes: xml:lang, xml:space, and xml:base. These are in the http://www.w3.org/XML/1998/namespace namespace, conveniently represented in SAX by the named constant NamespaceSupport.XMLNS. The revised startElement() method would be as follows:
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
namespaces.push(namespaceURI);
if (namespaceURI.equals(XHTML_NAMESPACE)) {
AttributesImpl newAttributes = new AttributesImpl();
// copy only those attributes that are not in a namespace
// and do not declare a non-XHTML namespace
for (int i = 0; i < atts.getLength(); i++) {
if (atts.getURI(i).equals("")
|| atts.getURI(i).equals(NamespaceSupport.XMLNS)) {
if (!atts.getQName(i).startsWith("xmlns:")) {
if (!atts.getQName(i).equals("xmlns")
|| atts.getValue(i).equals(XHTML_NAMESPACE)) {
newAttributes.addAttribute(atts.getURI(i),
atts.getLocalName(i),
atts.getQName(i),
atts.getType(i),
atts.getValue(i));
}
}
}
}
parent.startElement(namespaceURI, localName, qualifiedName,
newAttributes);
}
// else do nothing
}The rest of the methods are the same as in Example 8.9, so I won’t repeat them here.
So far I’ve demonstrated filters that simply removed particular tags, elements, and attributes from the parsed document. However, it’s equally easy to develop filters that insert new content or replace existing content. For example, it’s easy to imagine a filter that converts transitional XHTML to strict XHTML. Such a filter would have to replace deprecated elements like <font size="-1"> with their strict equivalents like <span style="font-size: small">. The details of listing all the tags that need to be fixed are a little tedious, but the algorithm for doing this is not particularly difficult.
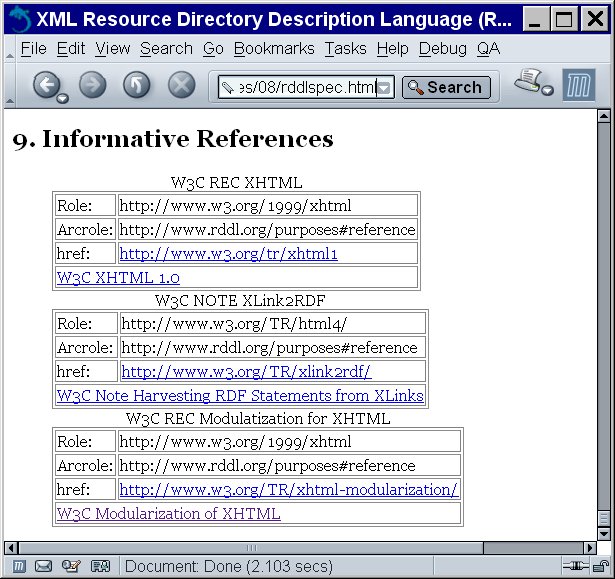
More simply, we can write a filter that modifies just one element. Example 8.11 is such a filter. It replaces rddl:resource elements with a simple table. The various attributes of the resource are mapped to different parts of the table. In particular, a rddl:resource like this:
<rddl:resource
id="note-xlink2rdf"
xlink:title="W3C NOTE XLink2RDF"
xlink:role="http://www.w3.org/TR/html4/"
xlink:arcrole="http://www.rddl.org/purposes#reference"
xlink:href="http://www.w3.org/TR/xlink2rdf/"
>
<li>
<a href="http://www.w3.org/TR/xlink2rdf/">
W3C Note Harvesting RDF Statements from XLinks
</a>
</li>
</rddl:resource>will turn into an XHTML table that looks like this:
<table id="note-xlink2rdf">
<caption>W3C NOTE XLink2RDF</caption>
<tr><td>Role: </td><td>http://www.w3.org/TR/html4/</td></tr>
<tr><td>Arcrole: </td><td>http://www.rddl.org/purposes#reference</td></tr>
<tr><td>Href: </td><td><a href="http://www.w3.org/TR/xlink2rdf/">
http://www.w3.org/TR/xlink2rdf/</a></td></tr>
<tr>
<td colspan="2">
<li>
<a href="http://www.w3.org/TR/xlink2rdf/">
W3C Note Harvesting RDF Statements from XLinks
</a>
</li>
</td>
</tr>
</table>This means that a single <rddl:resource> start-tag must create several elements and tags in the output document. There’s no guarantee of a one-to-one mapping between elements in the original and filtered content.
Example 8.11. Changing one element into another
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class ResourceToTable implements ContentHandler {
public final static String RDDL_NAMESPACE
= "http://www.rddl.org/";
public final static String XHTML_NAMESPACE
= "http://www.w3.org/1999/xhtml";
public final static String XLINK_NAMESPACE
= "http://www.w3.org/1999/xlink";
private ContentHandler parent;
public ResourceToTable(ContentHandler parent) {
this.parent = parent;
}
// Replace <rddl:resource> start-tags with the beginning of
// a table. Move the attributes into table cells.
// Make the content of the element the last table row.
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
if (localName.equals("resource")
&& RDDL_NAMESPACE.equals(namespaceURI)) {
String hrefAtt = atts.getValue(XLINK_NAMESPACE, "href");
String roleAtt = atts.getValue(XLINK_NAMESPACE, "role");
String arcroleAtt
= atts.getValue(XLINK_NAMESPACE, "arcrole");
String titleAtt = atts.getValue(XLINK_NAMESPACE, "title");
// We need to copy the id, xml:lang, and xml:base
// attributes, if any, from the rddl:resource element to
// the XHTML table element
AttributesImpl tableAttributes = new AttributesImpl();
String id = atts.getValue("id");
if (id != null) {
tableAttributes.addAttribute("", "id", "id", "ID", id);
}
String lang = atts.getValue("xml:lang");
if (lang != null) {
tableAttributes.addAttribute(NamespaceSupport.XMLNS,
"lang", "xml:lang", "NMTOKEN", lang);
}
String base = atts.getValue("xml:base");
// xml:base is not legal in XHTML. Here I just drop it, but
// it would be preferable to use it to resolve URLs in the
// XHTML document before passing them along
tableAttributes.addAttribute("", "border", "border",
"NMTOKEN", "1");
parent.startElement(
XHTML_NAMESPACE, "table", "table", tableAttributes);
Attributes noAtts = new AttributesImpl();
if (titleAtt != null) {
parent.startElement(
XHTML_NAMESPACE, "caption", "caption", noAtts);
characters(titleAtt.toCharArray(), 0, titleAtt.length());
endElement(XHTML_NAMESPACE, "caption", "caption");
}
if (roleAtt != null) {
parent.startElement(XHTML_NAMESPACE, "tr", "tr", noAtts);
parent.startElement(XHTML_NAMESPACE, "td", "td", noAtts);
String role = "Role: ";
characters(role.toCharArray(), 0, role.length());
endElement(XHTML_NAMESPACE, "td", "td");
parent.startElement(XHTML_NAMESPACE, "td", "td", noAtts);
characters(roleAtt.toCharArray(), 0, roleAtt.length());
endElement(XHTML_NAMESPACE, "td", "td");
endElement(XHTML_NAMESPACE, "tr", "tr");
}
if (arcroleAtt != null) {
String arcrole = "Arcrole: ";
parent.startElement(XHTML_NAMESPACE, "tr", "tr", noAtts);
parent.startElement(XHTML_NAMESPACE, "td", "td", noAtts);
characters(arcrole.toCharArray(), 0, arcrole.length());
endElement(XHTML_NAMESPACE, "td", "td");
parent.startElement(XHTML_NAMESPACE, "td", "td", noAtts);
characters(
arcroleAtt.toCharArray(), 0, arcroleAtt.length());
endElement(XHTML_NAMESPACE, "td", "td");
endElement(XHTML_NAMESPACE, "tr", "tr");
}
if (hrefAtt != null) {
String href = "href: ";
AttributesImpl hrefAtts = new AttributesImpl();
hrefAtts.addAttribute("", "href", "href", "CDATA", href);
parent.startElement(XHTML_NAMESPACE, "tr", "tr", noAtts);
parent.startElement(XHTML_NAMESPACE, "td", "td", noAtts);
characters(href.toCharArray(), 0, href.length());
endElement(XHTML_NAMESPACE, "td", "td");
parent.startElement(XHTML_NAMESPACE, "td", "td", noAtts);
parent.startElement(XHTML_NAMESPACE, "a", "a", hrefAtts);
characters(hrefAtt.toCharArray(), 0, hrefAtt.length());
endElement(XHTML_NAMESPACE, "a", "a");
endElement(XHTML_NAMESPACE, "td", "td");
endElement(XHTML_NAMESPACE, "tr", "tr");
}
// Now open the contents of the element
parent.startElement(XHTML_NAMESPACE, "tr", "tr", noAtts);
AttributesImpl colspanAtts = new AttributesImpl();
colspanAtts.addAttribute(
"", "colspan", "colspan", "CDATA", "2");
parent.startElement(
XHTML_NAMESPACE, "td", "td", colspanAtts);
}
else { // pass the element along
parent.startElement(namespaceURI, localName, qualifiedName,
atts);
}
}
// Replace </rddl:resource> end-tags with the end of a table.
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
if (localName.equals("resource")
&& RDDL_NAMESPACE.equals(namespaceURI)) {
parent.endElement(XHTML_NAMESPACE, "td", "td");
parent.endElement(XHTML_NAMESPACE, "tr", "tr");
parent.endElement(XHTML_NAMESPACE, "table", "table");
}
else {
parent.endElement(namespaceURI, localName, qualifiedName);
}
}
// Methods that pass data along unchanged:
public void startDocument() throws SAXException {
parent.startDocument();
}
public void setDocumentLocator(Locator locator) {
parent.setDocumentLocator(locator);
}
public void endDocument() throws SAXException {
parent.endDocument();
}
public void characters(char[] text, int start, int length)
throws SAXException {
parent.characters(text, start, length);
}
public void ignorableWhitespace(char[] text, int start,
int length) throws SAXException {
parent.ignorableWhitespace(text, start, length);
}
public void processingInstruction(String target, String data)
throws SAXException {
parent.processingInstruction(target, data);
}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
parent.startPrefixMapping(prefix, uri);
}
public void endPrefixMapping(String prefix)
throws SAXException {
parent.endPrefixMapping(prefix);
}
public void skippedEntity(String name)
throws SAXException {
parent.skippedEntity(name);
}
}
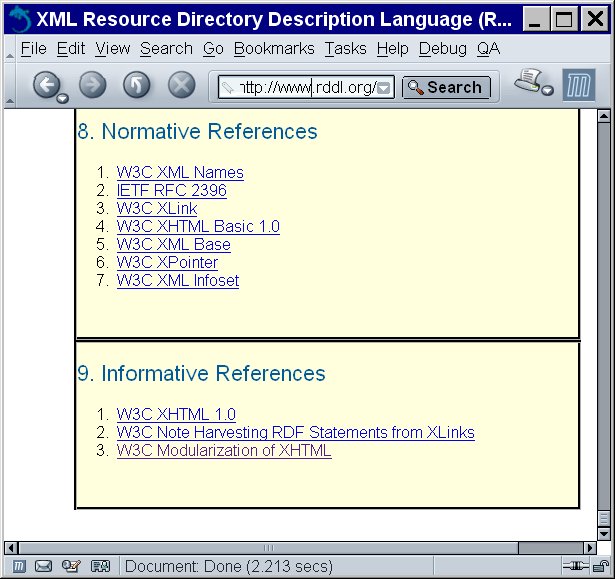
Figure 8.5 shows the end of the RDDL specification before this filter is applied. Figure 8.6 shows the end of the RDDL specification after this filter is applied (by passing the filtered source through an XMLWriter and saving the result in a text file.) You can see that the tables have been added as specified.
{kind=link}
{kind=link}
{kind=link}
By this point, some readers will have noticed that all these operations could perhaps have been more easily implemented in XSLT. Since XSLT is Turing complete, there really isn’t a lot you can do with a SAX filter that you can’t do with XSLT. The reason you choose one vs. the other is mostly a matter of convenience for the problem at hand. One factor in SAX’s favor is that it is much more efficient when the input or output can be streamed. Unlike XSLT, SAX does not need to read the entire document into memory before the transformation can be performed. The flip side of this is that filters only work well for localized transformations where the output in one part of the document doesn’t depend heavily on the input in another part of the document, especially a part of the document that comes later. For these cases, XSLT is preferable.
The second big advantage to using SAX filters instead of XSLT is that SAX gives you easy access to the full power of Java. For instance a SAX filter can read a book ISBN number and look up the current price of that book at amazon.com to insert as the value of a price attribute it adds to the element. Pure XSLT can’t do this. Of course, you could write an extension function in Java to add this feature to XSLT, so it really is mostly a question of which approach feels more natural to the developers within their particular system and for their particular problem.
[1] In fact, it probably should have been written as a subclass of TransparentFilter that overrode this one method, except that I’ve discovered that whenever I use inheritance to extend one example from an earlier one I get daily e-mail from readers asking me where the missing methods are. The next section will introduce a standard class you can extend to avoid repeating all these methods.