In a very real sense, SAX reports tags, not elements. When the parser encounters a start-tag, it calls the startElement() method. When the parser encounters an end-tag, it calls the endElement() method. When the parser encounters an empty-element tag, it calls the startElement() method and then the endElement() method.
If an end-tag does not match its corresponding start-tag, then the parser throws a SAXParseException. Beyond that, however, you are responsible for tracking the hierarchy. For example, if you want to treat a params element inside a methodCall element differently from a params element inside a fault element, then you’ll need to store some form of state in-between calls to the startElement() and endElement() methods. This is actually quite common. Many SAX content handlers simply build up a data structure as the document is parsed, and then operate on that data structure once the document has been completely read. Provided the data structure is simpler than the XML document itself, this is a reasonable approach. However in the most general case you can find yourself inventing a complete object hierarchy to represent arbitrary XML documents. In this case, you’re better off using DOM or JDOM instead of SAX, since they’ll do the hard work of defining and building this object hierarchy for you.
The arguments to the startElement() and endElement() methods are similar:
public void startElement(String namespaceURI, String localName, String qualifiedName, Attributes atts)
throws SAXException;public void endElement(String namespaceURI, String localName, String qualifiedName)
throws SAXException;First the namespace URI is passed as a String. If the element is unqualified (i.e. it is not in a namespace), then this argument is the empty string, not null.
Next the local name is passed as a String. This is the part of the name after the prefix and the colon, if any. For instance, if an element is named SOAP-ENV:Body, then its local name is Body. However, if an element is named Body with no prefix, then its local name is still Body.
The third argument contains the qualified name as a String. This is the entire element name including the prefix and the colon, if any. For instance, if an element is named SOAP-ENV:Body, then its qualified name is SOAP-ENV:Body. However, if an element is named Body with no prefix, then its qualified name is just Body.
Finally in the startElement() method only, the set of attributes for that element is passed as a SAX-specific Attributes object. I’ll discuss this in the next section.
As an example I’m going to build a GUI representation of the tree structure of an XML document that allows you to collapse and expand the individual elements. The GUI parts will be provided by a javax.swing.JTree. The tree will be filled in startElement() and displayed in a window in endDocument(). Example 6.7 shows how.
Example 6.7. A ContentHandler class that builds a GUI representation of an XML document
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.swing.*;
import javax.swing.tree.*;
import java.util.*;
public class TreeViewer extends DefaultHandler {
private Stack nodes;
// Initialize the per-document data structures
public void startDocument() throws SAXException {
// The stack needs to be reinitialized for each document
// because an exception might have interrupted parsing of a
// previous document, leaving an unempty stack.
nodes = new Stack();
}
// Make sure we always have the root element
private TreeNode root;
// Initialize the per-element data structures
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) {
String data;
if (namespaceURI.equals("")) data = localName;
else {
data = '{' + namespaceURI + "} " + qualifiedName;
}
MutableTreeNode node = new DefaultMutableTreeNode(data);
try {
MutableTreeNode parent = (MutableTreeNode) nodes.peek();
parent.insert(node, parent.getChildCount());
}
catch (EmptyStackException e) {
root = node;
}
nodes.push(node);
}
public void endElement(String namespaceURI, String localName,
String qualifiedName) {
nodes.pop();
}
// Flush and commit the per-document data structures
public void endDocument() {
JTree tree = new JTree(root);
JScrollPane treeView = new JScrollPane(tree);
JFrame f = new JFrame("XML Tree");
f.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
f.getContentPane().add(treeView);
f.pack();
f.show();
}
public static void main(String[] args) {
try {
XMLReader parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
ContentHandler handler = new TreeViewer();
parser.setContentHandler(handler);
for (int i = 0; i < args.length; i++) {
parser.parse(args[i]);
}
}
catch (Exception e) {
System.err.println(e);
}
} // end main()
} // end TreeViewer
The JTree class provides a ready-made data structure for this program. All we have to do is fill it. However, it’s also necessary to track where we are in the XML hierarchy at all times so that the parent to which the current node will be added is accessible. For this purpose a stack is very helpful. The parent element can be pushed onto the stack in startElement() and popped off the stack in endElement(). Since SAX’s beginning-to-end parsing of an XML document equates to a depth-first tree traversal, the top element in the stack always contains the most recently visited element.
I find stacks like this to be very useful in many SAX programs. More complex programs may need to build more complicated tree or object structures. If your purpose is not simply to display a GUI for the tree, then you should probably roll your own tree structure rather than using JTree as I’ve done here.
Note
TreeViewer runs with the default distribution of Java 1.2 or later. It can run with Java 1.1, but you’ll need to make sure the swingall.jar archive is somewhere in your class path. The javax.swing classes used here are not bundled with the JDK 1.1.
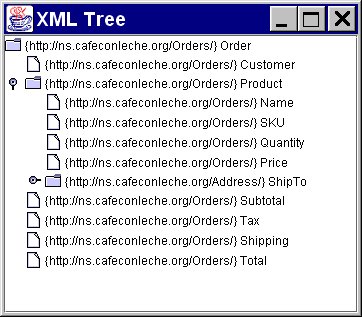
Figure 6.1 shows this program displaying Example 1.7 from Chapter 1. Swing allows individual parts of the tree to be collapsed or expanded; but the entire element tree is always present even if it’s hidden. JTree also allows you to customize the icons used, and even enable the user to edit the tree. However, since that’s purely Swing programming and says little to nothing about XML, I leave that as an exercise for the reader.
{kind=link}
Caution
This makes a nice little example, but please don’t treat it as more than that. The tantalizing easiness of representing XML documents with widgets like java.swing.JTree and similar things in Windows, Motif, and other GUIs has spawned a lot of editors and browsers that use these tree models as user interfaces. However, not a lot of thought went into whether users actually thought of XML documents this way or could be quickly trained to do so.
In actual practice, user interfaces of this sort have failed spectacularly. A good user interface for XML editors and viewers looks a lot more like the user interfaces people are accustomed to from traditional programs such as Microsoft Word, Netscape Navigator, and Adobe Illustrator. The whole point of a GUI is that it can decouple the user interface from the underlying data model. Just because an XML document is a tree is no excuse for making users edit trees when they don’t want to.