XML is just a document format. Documents by themselves don’t do anything. They simply are. They contain information, but they neither read nor write that information. They tend to stay in one place, and do not move unless somebody or something moves them.
If two systems want to exchange messages in XML format, it is not hard for them to do so. Each message can be encoded as a complete XML document. The sender can transmit the document to the receiver using FTP, HTTP, NFS, named pipes, RPC, floppy disks, a null-modem cable running between two machines’ serial ports, modems communicating over telephone lines, or any other means of moving data between systems. It’s even acceptable for the sender to print out the XML document on paper, seal it in a stamped envelope, and drop it in the mail. After the Post Office delivers the mail, the recipient can scan it in. XML is completely transport-protocol neutral. As long as the document gets where it’s going without being corrupted along the way, XML neither knows nor cares how it got there.
Since XML doesn’t care how documents are moved from point A to point B, it’s sensible to pick the simplest broadly supported protocol you can; and that is HTTP, the Hypertext Transport Protocol used by all web browsers and servers. Using HTTP to transport XML has a number of advantages, among them:
HTTP is well supported by libraries in Java, Perl, C, and many other languages for both client and server programs. This takes a large burden off the shoulders of the programmer.
HTTP is platform independent. Windows PCs, Macs, Unix boxes, mainframes, and more are all happy speaking HTTP.
HTTP connections are normally allowed to pass through firewalls.
Since the HTTP protocol is text-based, you can use telnet to test out servers.
The HTTP header provides a convenient place to store out-of-band information such as the document size and encoding.
HTTP is very well understood in the developer community.
Thus it should be no surprise that one of the most popular ways to move XML documents between systems is by using HTTP. A server can send an XML document to a client just as easily as it can send an HTML document or a JPEG image. A little less well-known is that a client can easily send an XML document (or anything else) to a server using HTTP POST.
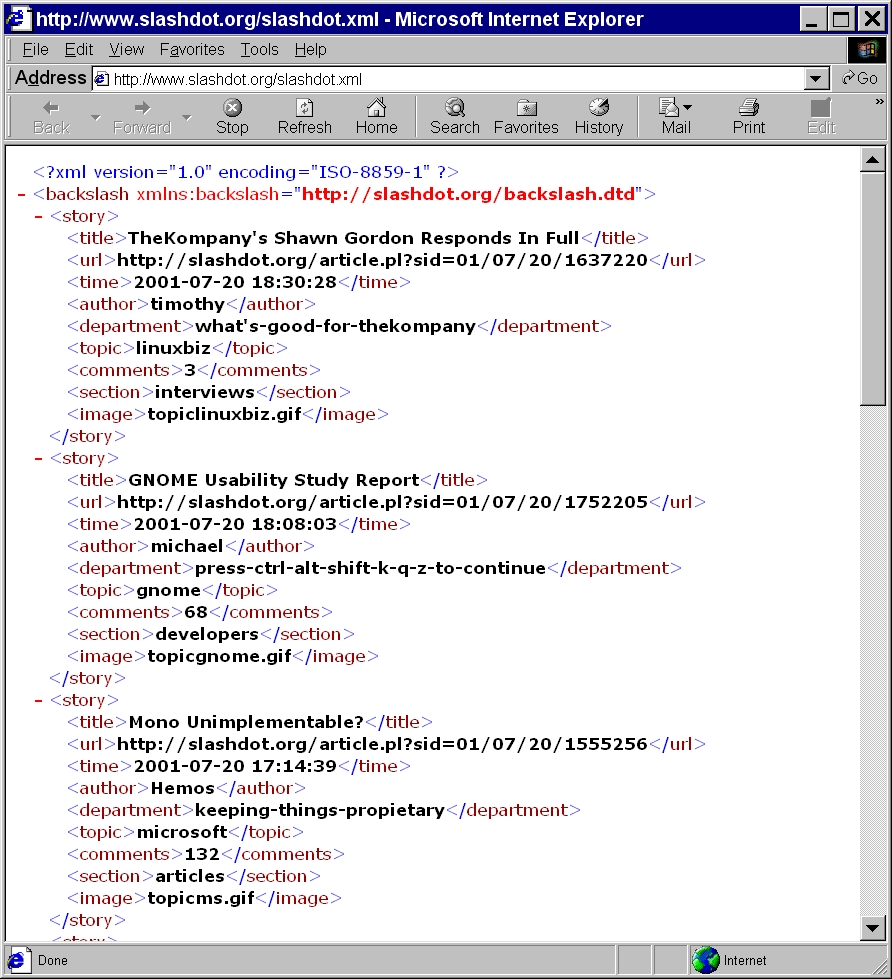
The simplest possible XML protocol merely pulls down an XML document from a known URL on a server. You don’t need to send anything more to the server than a request for a page. For instance, today’s Slashdot headlines are available in XML from http://www.slashdot.org/slashdot.xml. All you have to do to get the headlines is load that URL into a browser as shown in Figure 2.1.
{kind=link}
Behind the scenes, here’s what’s going over the wire for that request. First the browser opens a socket to www.slashdot.org on port 80. Then it sends a request that looks something like this:
GET /slashdot.xml HTTP/1.1 Host: www.slashdot.org User-Agent: Mozilla/5.0 (Windows; U; WinNT4.0; en-US; rv:0.9.2) Accept: text/xml, text/html;q=0.9, image/jpeg, */*;q=0.1 Accept-Language: en, fr;q=0.50 Accept-Encoding: gzip,deflate,compress,identity Accept-Charset: ISO-8859-1, utf-8;q=0.66, *;q=0.66 Keep-Alive: 300 Connection: keep-alive
The server responds with its own HTTP header, a blank line, and the body of the requested document. The result looks like this:
HTTP/1.1 200 OK
Date: Fri, 20 Jul 2001 19:31:10 GMT
Server: Apache/1.3.12 (Unix) mod_perl/1.24
Last-Modified: Fri, 20 Jul 2001 18:34:06 GMT
ETag: "de47c-e5e-3b58799e"
Accept-Ranges: bytes
Content-Length: 3678
Connection: close
Content-Type: text/xml
<?xml version="1.0" encoding="ISO-8859-1"?><backslash
xmlns:backslash="http://slashdot.org/backslash.dtd">
<story>
<title>TheKompany's Shawn Gordon Responds In Full</title>
<url>http://slashdot.org/article.pl?sid=01/07/20/1637220</url>
<time>2001-07-20 18:30:28</time>
<author>timothy</author>
<department>what's-good-for-thekompany</department>
<topic>linuxbiz</topic>
<comments>3</comments>
<section>interviews</section>
<image>topiclinuxbiz.gif</image>
</story>
<story>
<title>GNOME Usability Study Report</title>
<url>http://slashdot.org/article.pl?sid=01/07/20/1752205</url>
<time>2001-07-20 18:08:03</time>
<author>michael</author>
<department>press-ctrl-alt-shift-k-q-z-to-continue</department>
<topic>gnome</topic>
<comments>68</comments>
<section>developers</section>
<image>topicgnome.gif</image>
</story>
<story>
<title>Mono Unimplementable?</title>
<url>http://slashdot.org/article.pl?sid=01/07/20/1555256</url>
<time>2001-07-20 17:14:39</time>
<author>Hemos</author>
<department>keeping-things-propietary</department>
<topic>microsoft</topic>
<comments>132</comments>
<section>articles</section>
<image>topicms.gif</image>
</story>
</backslash>In both directions the HTTP header is pure text. Lines in the header are delimited by carriage-return linefeed pairs; that is, \r\n. The body of the document is separated from the HTTP header by a blank line. The document may or may not be text. For instance, it could be a JPEG image or a gzipped HTML file.
Servers can also respond with a variety of error codes. For example, here’s the common 404 Not Found error:
HTTP/1.0 404 Not found Server: Netscape-Enterprise/2.01 Date: Wed, 04 Jul 2001 20:35:17 GMT Content-length: 207 Content-type: text/html <TITLE>Not Found</TITLE><H1>Not Found</H1> The requested object does not exist on this server. The link you followed is either outdated, inaccurate, or the server has been instructed not to let you have it.
Of course, you don’t have to load these documents into a browser. Java lets you write programs that connect to and retrieve information from web sites with hardly any effort. Once you have a document in memory you can do whatever you want with it: search it, sort it, transform it, forward it to somebody else, clean up after the family dog with it, whatever you want. Future chapters are going to cover the details of all these operations (except cleaning up after the family dog; you’re on your own for that :-) ). But first I want to show you how to use Java to retrieve such information and dump it to the console. Later we’ll move from merely retrieving and printing a document to reading and understanding it.
Example 2.2 is a Java class that uses the java.net.URL class to load documents via HTTP (or any other supported protocol) from a server. It has four methods. getDocumentAsInputStream() connects to a server and returns the unread stream after stripping off the HTTP header. getDocumentAsString() actually reads the entire document, stores it in a string buffer, and then returns a string containing the document at the URL. Overloaded variants of each method allow you to pass in either the string form of the URL or a java.net.URL object, whichever is more convenient. The method that retrieves the document as an input stream would be used if you want to process the document as it arrives. The string version would be used if the document wasn’t too big and you wanted to make sure the entire document was available before working with it.
Example 2.2. URLGrabber
package com.macfaq.net;
import java.net.URL;
import java.io.IOException;
import java.net.MalformedURLException;
import java.io.InputStream;
public class URLGrabber {
public static InputStream getDocumentAsInputStream(URL url)
throws IOException {
InputStream in = url.openStream();
return in;
}
public static InputStream getDocumentAsInputStream(String url)
throws MalformedURLException, IOException {
URL u = new URL(url);
return getDocumentAsInputStream(u);
}
public static String getDocumentAsString(URL url)
throws IOException {
StringBuffer result = new StringBuffer();
InputStream in = url.openStream();
int c;
while ((c = in.read()) != -1) result.append((char) c);
return result.toString();
}
public static String getDocumentAsString(String url)
throws MalformedURLException, IOException {
URL u = new URL(url);
return getDocumentAsString(u);
}
}
One method you might expect to see here I’ve deliberately left out. There is no getReaderFromURL(). Before you can convert the input stream into a reader, you need to figure out which encoding to use. Because XML documents normally carry their own information about encoding, this requires you to parse the first line or two of the XML document. URLGrabber could do that, but the details are rather complicated and doing this would make this class less generic than it currently is. (Right now it can handle any kind of document, not just XML documents.) It’s better to leave all the XML-specific details such as determining the character encoding to the XML parser.
Since URLGrabber is a generally useful class, I’ve placed it in the com.macfaq.net package. I will use this class again later in this book without further comment. To do so I will have to import com.macfaq.net.*, and I will have to make sure my source files are properly organized in my file system. The Java examples in this book are not all trivial, and cannot all fit in a single class. In general, I will divide programs into different classes offering small pieces of functionality like this one so that I can debug and explain them separately, as well as mix and match them in different programs.
Warning
Nothing in Java is as pointlessly confusing as the proper organization of .class and .java files in different packages on a file system. Learning how to use packages correctly is one of the major hurdles for novice Java programmers. It is also one of the obstacles a good IDE can really help you with. If you are having problems making these programs compile and work as described here because of the package structure, especially if you’re seeing error messages that involve “java.lang.NoClassDefFoundError”, please consult a good introductory reference on Java. For these details, I recommend [How the virtual machine locates classes, in Core Java 2, Volume 1, by Cay S. Horstmann and Gary Cornell, Sun Microsystems Press 2001, ISBN 0-13-089468-0, pp. 168-171] and [Managing Source and Class Files, in The Java Tutorial, 3rd Edition, by Mary Campione, Kathy Walrath, and Alison Hunt, Addison-Wesley, 2001, ISBN 0-201-70393-9, pp. 238-241]. (Neither of these is complete. In particular neither covers the crucial sourcepath option to the javac compiler, or shows you how to compile and run a program divided across multiple packages. I’m still looking for a better introductory reference on these topics. If you know of one, please drop an email to elharo@metalab.unc.edu. Thanks!) However, in this book I will assume that you have learned how to navigate the obstacles Java places in your CLASSPATH with a reasonable degree of facility.
Isolating the code to communicate with the network in the URLGrabber class will allow us to ignore it in the future. For the most part, the details of network transport are not relevant when processing XML. Many of the programs in this book that process XML will expect to receive an XML document as a stream or a string. They really don’t care where that stream or string comes from as long as it contains a well-formed XML document. In the remainder of this book when I need to load an XML document from a URL via GET, I will refer to this class without duplicating the code.
Another aspect of this program that I find sometimes confuses people: it does not have a main() method. It is not intended to be used directly by typing java URLGrabber at the command line. Rather this is a library class meant for other programs to use. Example 2.3 is a simple program designed just to test URLGrabber with a very basic command line user interface. Since it is not a generally useful class, I have not placed it anywhere in the com.macfaq packages. Instead it is simply a quick, one-off program so I can make sure that URLGrabber actually works and does what I want it to do.
Example 2.3. URLGrabberTest
import com.macfaq.net.URLGrabber;
import java.io.IOException;
import java.net.MalformedURLException;
public class URLGrabberTest {
public static void main(String[] args) {
for (int i = 0; i < args.length; i++) {
try {
String doc = URLGrabber.getDocumentAsString(args[i]);
System.out.println(doc);
}
catch (MalformedURLException e) {
System.err.println(args[i]
+ " cannot be interpreted as a URL.");
}
catch (IOException e) {
System.err.println("Unexpected IOException: "
+ e.getMessage());
}
}
}
}
Here’s a simple example of using URLGrabberTest to download the XML document from http://www.slashdot.org/slashdot.xml:
D:\books\XMLJAVA>java URLGrabberTest http://www.slashdot.org/slashdot.xml
<?xml version="1.0" encoding="ISO-8859-1"?><backslash
xmlns:backslash="http://slashdot.org/backslash.dtd">
<story>
<title>TheKompany's Shawn Gordon Responds In Full</title>
...However, URLGrabberTest is really nothing more than toy example that fits nicely and neatly in the space available on a printed page. In 2002, serious programs either use GUIs or they don’t have an explicit user interface at all. Example 2.2 is a useful program. Example 2.3 is not.
There are many services that can use this simple approach to transmitting XML data across HTTP. For example, besides headlines this is a straightforward way to distribute the titles and show times of the movies playing at a particular theater, the viewing conditions at an observatory, the operational state of a machine in a factory, the daily sales at a retail store, the surf conditions at Ehukai Beach, and more. What makes this possible is that all users want pretty much the same document. The response does not need to be customized for each requestor.