
Persistence/Storage
Search/Retrieval
Combinations/Restructuring
Transactions
Access Control
Storage Independence
Replication
Network
Hierarchical
Relational
Object
Entity-attribute-value
Key-value
Hybrid
Ad Hoc (Filemaker, dBase, etc)
Payroll
Accounting
Billing
Census
Shipping
Stock trades
Scientific measurements
And much more
Relational models work very well for problems that can be decomposed into predictable sets of small atomic pieces of information that can be managed independently.
Order doesn't matter
Limited substructure (no hierarchies)
Fully bidirectional connections
Repeating structures
Few nulls
Predictable, reliable schema
Poetry
Legal briefs
Technical Manuals
Magazines
Books
Encyclopedias
Web Sites
The Library of Congress
Tax Forms
Course Notes
Medical charts and doctor's notes
Case histories
etc.
I'll make it fit
Unary encoding
Infinity is the key
Relational databases can encode anything
We need databases that provide services like transactions but without pounding everything into rectangular holes.
Different databases for different data.
Many relational databases implicitly recognize this by providing non-relational extensions such as full-text search.
Many database designs implicitly recognize this by deliberately storing non-normalized data.
And of course SQL isn't truly relational anyway.
From fully normalized structure to no structure at all
"Database" only stores the index, not the data. Data is usually stored in a possibly distributed file system.
Markup is what gets in the way of the content.
Great for full text search
The only technology proven to work at the size of the Web (not just a web site but the entire Web)
Examples:
Lucene
Fast
Is there anything in between all structure (relational) and no structure (index engines)?
Do not replace SQL databases for data that does fit into rectangular holes.
Handle some non-rectangular data.
In particular, work very well with hierarchical data.
We're reinventing hierarchical databases with XML. Are network databases next?
Did they really fail?
Relational databases did replace them for many tasks
Primarily because they required you to define your queries at database design time.
And because, like SQL, they required a fixed schema. Fixed table schemas are more flexible than fixed hierarchy schemas.
You didn't have to have a fixed schema?
And you didn't have to specify all your queries up front?
We know a lot more about database design and optimization now than we did in the 1970s.
And we have much more powerful hardware.
Maybe it's time to revisit some of the assumptions that led us to relational databases.
Order and position matter
Deeply nested and even recursive data
Mixed content
Duplicate content and redundant data
Grouping at multiple levels (hierarchies)
Unpredictable schema or no schema at all
Multiple structures per document (e.g. Xanadu)
Overlap
Pointers that jump around in the document, not just parent to child
eXist
Berkeley dbXML
Sedna
MXQuery
XIndice (formerly dbXML)
Mark Logic
iPedo
X-Hive/DB
TigerLogic
DB2 9
Oracle 10g
Microsoft SQL Server
Can a DB handle very large single documents?
Can the DB handle very many small-to-medium documents?
Maximum database size
Granularity of locks: per-document or smaller?
XQuery 1.0 support
XQuery Full-text search support
Update support
Schemas: required, optional, or unsupported?
Import formats
And of course cost, freedom, and support
XQuery
XQuery Update Facility
XQuery Fulltext Search
Proprietary extensions to fill in the holes
And of course bindings for your favorite language
Open Source
Storage engine is well-proven Berkeley DB, a non-networked, embeddable key-value database
Now owned by Oracle
XQuery Fulltext Search
Compile from source
$ dbxml dbxml> createContainer website.dbxml Creating node storage container with nodes indexed
dbxml> putDocument pages '/home/elharo/initialdata.xml' f Document added, name = pages
dbxml> query 'collection("website.dbxml")//*'
220 objects returned for eager expression ' collection("website.dbxml")//*'
dbxml> print
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:thr="http://purl.org/syndication/thread/1.0"
xml:lang="en">
<id>http://www.elharo.com/blog/feed/atom/</id>
<updated>2007-10-07T15:43:26Z</updated>
<title type="text">Mokka mit Schlag</title>
...
dbxml> setNamespace atom http://www.w3.org/2005/Atom
Binding atom -> http://www.w3.org/2005/Atom
dbxml> query 'collection("website.dbxml")//atom:id'
11 objects returned for eager expression 'collection("website.dbxml")//atom:id'
dbxml> print
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/feed/atom/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/birding/2007/10/07/brown-lipped-snail/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/birding/2007/10/06/common-house-spider/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/networks/2007/10/05/were-back/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/networks/2007/10/01/shopping-for-isps/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/birding/2007/09/29/autumn-meadowhawks/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/new-york/2007/09/28/new-york-skyline/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/birding/2007/09/28/connecticut-warbler/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/science/astronomy/2007/09/28/adaptive-optics-on-the-cheap/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/birding/2007/09/28/390-connecticut-warbler-at-metrotech/</id>
<id xmlns="http://www.w3.org/2005/Atom">http://www.elharo.com/blog/software-development/web-development/2007/09/26/amazon-breaks-their-site/</id>
dbxml> query 'doc("website.dbxml/pages")//*'
220 objects returned for eager expression ' collection("website.dbxml")//*'
dbxml> print
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:thr="http://purl.org/syndication/thread/1.0"
xml:lang="en">
<id>http://www.elharo.com/blog/feed/atom/</id>
<updated>2007-10-07T15:43:26Z</updated>
<title type="text">Mokka mit Schlag</title>
...
Three parts:
A data model for XML documents based on the XML Infoset and the W3C XML Schema Language Post Schema Validation Infoset (PSVI)
A mathematically precise query algebra; that is, a set of query operators on that data model
A query language based on these query operators and this algebra
A fourth generation declarative language like SQL; not a procedural language like Java or a functional language like XSLT
Queries operate on single documents or fixed collections of documents.
Queries select whole documents or subtrees of documents that match conditions defined on document content and structure
Can construct new documents based on what is selected
No updates, inserts, or deletes!
Narrative documents and collections of such documents; e.g. generate a table of contents for a book
Record-like documents; e.g. SQL-like queries of an XML dump of a database
Filtering streams to process logs of email messages, network packets, stock market data, newswire feeds, EDI, or weather data to filter and route messages represented in XML, to extract data from XML streams, or to transform data in XML streams.
XML views of non-XML data
Files on a disk
Native-XML databases like Mark Logic Content Server
Fields in hybrid databases like IBM DB2 9
DOM trees in memory
Streaming data
Other representations of the infoset
Command line query tools
GUI query tools
JSP, ASP, PHP, and other such server side technologies
Programs written in Java, C++, and other languages that need to extract data from XML documents
Others are possible
Anywhere SQL is used to extract data from a database, XQuery is used to extract data from an XML document.
SQL is a non-compiled language that must be processed by some other tool to extract data from a database. So is XQuery.
| A relational database contains tables | An XML database contains collections |
| A relational table contains records with the same schema | A collection contains XML documents with the same DTD |
| A relational record is an unordered list of named values | An XML document is a tree of nodes |
| A SQL query returns an unordered set of records | An XQuery returns an ordered sequence of nodes |
XML 1.0 #PCDATA
Schema primitive types: positiveInteger, String, float, double, unsignedLong, gYear, date, time, boolean, etc.
Schema complex types
Collections of these types
References to these types
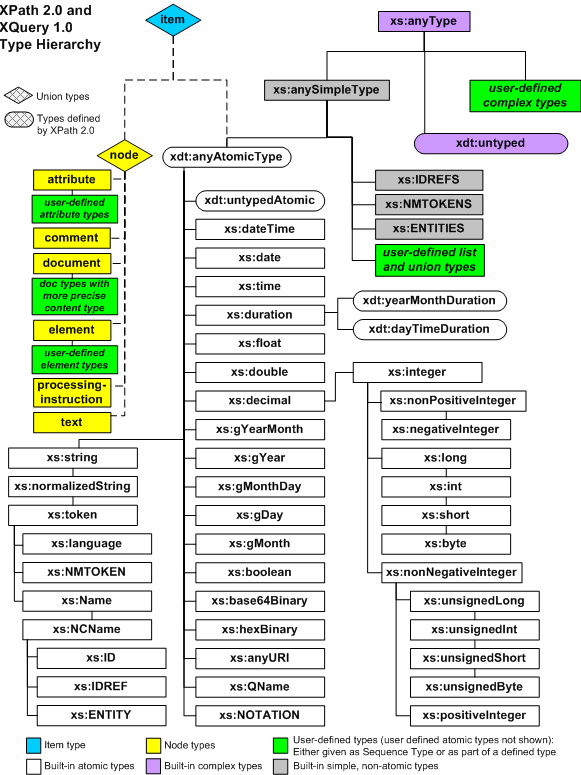
Picture taken from XQuery 1.0 and XPath 2.0 Functions and Operators W3C Working Draft 3 November 2005
Most of the examples in this talk query this bibliography document at the (relative) URL bib.xml:
<?xml version="1.0"?>
<bib>
<book year="1994">
<title>TCP/IP Illustrated</title>
<author><last>Stevens</last><first>W.</first></author>
<publisher>Addison-Wesley</publisher>
<price>65.95</price>
</book>
<book year="1992">
<title>Advanced Programming in the Unix Environment</title>
<author><last>Stevens</last><first>W.</first></author>
<publisher>Addison-Wesley</publisher>
<price>65.95</price>
</book>
<book year="2000">
<title>Data on the Web</title>
<author><last>Abiteboul</last><first>Serge</first></author>
<author><last>Buneman</last><first>Peter</first></author>
<author><last>Suciu</last><first>Dan</first></author>
<publisher>Morgan Kaufmann Publishers</publisher>
<price>39.95</price>
</book>
<book year="1999">
<title>The Economics of Technology and Content for Digital TV</title>
<editor>
<last>Gerbarg</last><first>Darcy</first>
<affiliation>CITI</affiliation>
</editor>
<publisher>Kluwer Academic Publishers</publisher>
<price>129.95</price>
</book>
</bib>
Adapted from Mary Fernandez, Jerome Simeon, and Phil Wadler: XML Query Languages: Experiences and Exemplars, 1999, as adapted in XML Query Use Cases

for: each item in an XPath 2.0 sequence
let: a new variable have a specified value
where: a condition expressed in XPath is true
order by: the value of an XPath expression
return: a sequence of items
for $t in doc("bib.xml")/bib/book/title
return
$t
Adapted from XML Query Use Cases
% java -classpath saxon8.jar net.sf.saxon.Query query1 <?xml version="1.0" encoding="UTF-8"?> <title>TCP/IP Illustrated</title> <title>Advanced Programming in the Unix Environment</title> <title>Data on the Web</title> <title>The Economics of Technology and Content for Digital TV</title>
<?xml version="1.0"?> <title>TCP/IP Illustrated</title><title>Advanced Programming in the Unix Environment</title><title>Data on the Web</title><title>The Economics of Technology and Content for Digital TV</title>
Algorithm for converting sequence to a document fragment:
Convert each atomic value to a string.
Concatenate adjacent strings after separating them with a single space.
Change the strings to text nodes
Replace any document node in the sequence with its children.
It is a serialization error if the sequence contains an attribute node or a namespace node at this point.
Output methods:
xml
html
xhtml
Serialization options:
version
encoding
indent
cdata-section-elements
omit-xml-declaration
standalone
doctype-system
doctype-public
undeclare-prefixes
media-type
byte-order-mark
escape-uri
normalization-form
include-content-type
escape-uri-attributes
use-character-maps
(Adapted from Jeni Tennison)
The first class objects are strings, numbers, booleans, and node-sets (plus result tree fragments for XSLT)
Node-sets contain nodes (which are not first-class objects)
Nodes have various properties, including children - a node-set (the order of the children can be worked out from the nodes' document order)
Seven node types: document, element, attribute, text, namespace, processing instruction, and comment
There are conceptually two kinds of node-sets:
Node-sets containing new nodes (result tree fragments) can only be generated using XSLT
Node-sets containing existing nodes can only be generated using XPath
No list data types, only node-sets but no number sets
Not Infoset compatible
(Adapted from Jeni Tennison)
The first class object type is a sequence; that is, an ordered list
Sequences contain items of two types: simple typed values or nodes. (They may not contain other sequences.)
Simple typed values have W3C XML Schema Language simple types: xs:gYear, xs:int, xs:decimal, xs:date, etc.
Seven node types: document, element, attribute, text, namespace, processing instruction, and comment
Nodes have these properties:
node-kind: either "document", "element", "attribute", "text", "namespace", "processing-instruction", or "comment".
node-name: a sequence containing one expanded QName if the node has a name (elements, attributes, etc.) or an empty sequence if the node doesn't have a name (comments, text nodes, etc.)
parent: a sequence containing the unique parent node; the empty sequence is returned for parentless nodes, particularly document and namespace nodes
base-uri: URI from which this particular node came (possibly adjusted by
an xml:base attribute)
document-uri: URI from which this node's document came
string-value: same as XPath 1.0
typed-value: a sequence of simple typed values corresponding to the node (always the empty sequence for anything other than elements and attributes)
children: A sequence of nodes (empty except for element and document nodes)
attributes: a sequence of attribute nodes; empty except for element nodes
namespaces: a sequence of namespace nodes in-scope on the node
nilled: true if this is a nil element (xsi:nil="true"),
false otherwise
type: a sequence containing 0 or 1 schema component
Infoset compatible
Parentheses enclose sequences.
In literal sequence, the item literals are separated by a commas:
(1, 3, 2, 34, 76, -87)
The to operator
generates a range sequence without explicit listing:
(1 to 12)
Using constructors:
(xs:date("2003-03-11"), xs:date("2003-03-12"), xs:date("2003-03-13"), xs:date("2003-03-14"), xs:date("2003-03-15"))
Sequences can have mixed types: (xs:date("2002-03-11"), "Hello", 15)
Sequences do not nest; that is, a sequence cannot be a member of a sequence
Sequences are not sets: they are ordered and can contain duplicates
Sequences do not nest; that is, a sequence cannot be a member of a sequence
Sequences are not sets: they are ordered and can contain duplicates
A sequence containing one item is the same as the item, and vice versa
for $a in (1 to 10)
return $aOutput:
1
2
3
4
5
6
7
8
9
10
All data is typed according to XML Schema Part 2: Datatypes.
A schema specifies the types
If no schema is available, the default complex type is xs:anyType
and the default simple type is
xdt:untypedAtomic
Operators and functions are type-aware; e.g. can't add a string to a double or compare an integer to a year.
Constructors and casts are are available to convert data to appropriate types
Automatic casting is sometimes performed on untyped data, but can fail
Tags are given as literals
XQuery expression which is evaluated to become the contents of the element is enclosed in curly braces
The contents can also contain literal text outside the braces
List titles of all books in a bib element.
Put each title in a book element.
<bib>
{
for $title in doc("bib.xml")/bib/book/title
return
<book>
{ $title }
</book>
}
</bib>
Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<book>
<title>TCP/IP Illustrated</title>
</book>
<book>
<title>Advanced Programming in the Unix Environment</title>
</book>
<book>
<title>Data on the Web</title>
</book>
<book>
<title>The Economics of Technology and Content for Digital TV</title>
</book>
</bib>
List books including their year and title:
<bib>
{
for $book in doc("bib.xml")/bib/book
return
<book year ="{ $book/@year }">
{ $book/title }
</book>
}
</bib>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<book year="1994">
<title>TCP/IP Illustrated</title>
</book>
<book year="1992">
<title>Advanced Programming in the Unix Environment</title>
</book>
<book year="2000">
<title>Data on the Web</title>
</book>
<book year="1999">
<title>The Economics of Technology and Content for Digital TV</title>
</book>
</bib>
Literal text is allowed outside the XQuery expressions, just like literal tags:
<bib>
<h1>Bibliography</h1>
{
for $book in doc("bib.xml")/bib/book
return
$book/title
}
</bib>
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<h1>Bibliography</h1>
<title>TCP/IP Illustrated</title>
<title>Advanced Programming in the Unix Environment</title>
<title>Data on the Web</title>
<title>The Economics of Technology and Content for Digital TV</title>
</bib>
Literal comments and processing instructions are also allowed:
<?xml-stylesheet type="text/css" href="bibliography.css"?>,
<bib>
<h1>Bibliography</h1>
{
for $b in doc("bib.xml")/bib/book
return
$b/title
}
</bib>,
<!-- An example from Elliotte Rusty Harold's
Native XML Databases presentation -->
Notice the commas
Remember, an XQuery is not an XML document.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="application/xml" href="bibliography.css"?>
<bib>
<h1>Bibliography</h1>
<title>TCP/IP Illustrated</title>
<title>Advanced Programming in the Unix Environment</title>
<title>Data on the Web</title>
<title>The Economics of Technology and Content for Digital TV</title>
</bib>
<!-- An example from Elliotte Rusty Harold's
Native XML Databases presentation -->
List titles of books published by Addison-Wesley
<bib>
{
for $book in doc("bib.xml")/bib/book
where $book/publisher = "Addison-Wesley"
return
$book/title
}
</bib>
This where clause could be replaced by an XPath predicate:
<bib>
{
for $book in doc("bib.xml")/bib/book[publisher="Addison-Wesley"]
return
$book/title
}
</bib>But where clauses can combine
multiple variables from multiple documents
Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<title>TCP/IP Illustrated</title>
<title>Advanced Programming in the Unix Environment</title>
</bib>
Adapted from XML Query Use Cases
XQuery booleans include:
and
or
not()
List books published by Addison-Wesley before 1993:
<bib>
{
for $book in doc("bib.xml")/bib/book
where $book/publisher = "Addison-Wesley" and $book/@year < 1993
return
$book/title
}
</bib>
Do you notice anything funny about this query?
Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<title>Advanced Programming in the Unix Environment</title>
</bib>
Adapted from XML Query Use Cases
Create a list of all the title-author pairs, with each pair enclosed in
a result element.
<results>
{
for $book in doc("bib.xml")/bib/book,
$title in $book/title,
$author in $book/author
return
<result>
{ $title }
{ $author }
</result>
}
</results>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<results>
<result>
<title>TCP/IP Illustrated</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
</result>
<result>
<title>Advanced Programming in the Unix Environment</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
</result>
<result>
<title>Data on the Web</title>
<author>
<last>Abiteboul</last>
<first>Serge</first>
</author>
</result>
<result>
<title>Data on the Web</title>
<author>
<last>Buneman</last>
<first>Peter</first>
</author>
</result>
<result>
<title>Data on the Web</title>
<author>
<last>Suciu</last>
<first>Dan</first>
</author>
</result>
</results>
Adapted from XML Query Use Cases
For each book in the bibliography, list the title and authors, grouped inside
a result element.
<results>
{
for $b in doc("bib.xml")/bib/book
return
<result>
{ $b/title }
{
for $a in $b/author
return $a
}
</result>
}
</results>
Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<results>
<result>
<title>TCP/IP Illustrated</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
</result>
<result>
<title>Advanced Programming in the Unix Environment</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
</result>
<result>
<title>Data on the Web</title>
<author>
<last>Abiteboul</last>
<first>Serge</first>
</author>
<author>
<last>Buneman</last>
<first>Peter</first>
</author>
<author>
<last>Suciu</last>
<first>Dan</first>
</author>
</result>
<result>
<title>The Economics of Technology and Content for Digital TV</title>
</result>
</results>
Adapted from XML Query Use Cases
let assigns a variable for reuse.
For each book in the bibliography, list the difference between the book's price and the average price:
<results>
{
let $doc := doc("bib.xml")
let $average := avg($doc//price)
for $b in $doc/bib/book
let $difference := $b/price - $average
return
<data>{ $b/title } is {$difference} more expensive than the average. </data>
}
</results>:= like Pascal, not = like C and Java
<?xml version="1.0" encoding="UTF-8"?>
<results>
<data>
<title>TCP/IP Illustrated</title> is -9.5 more expensive than the average. </data>
<data>
<title>Advanced Programming in the Unix Environment</title> is -9.5 more expensive than the average. </data>
<data>
<title>Data on the Web</title> is -35.5 more expensive than the average. </data>
<data>
<title>The Economics of Technology and Content for Digital TV</title> is 54.499999999999986 more expensive than the average. </data>
</results>For each book in the bibliography, list the difference between the book's price and the average price, but this time indicate whether the book is more or less expensive than the average
<results>
{
let $doc := doc("bib.xml")
let $average := avg($doc//price)
for $b in $doc/bib/book
return
if ($b/price > $average) then
<data>
{ $b/title } is ${$b/price - $average}
more expensive than the average.
</data>
else
<data>
{ $b/title } is ${$average - $b/price}
less expensive than the average.
</data>
}
</results><?xml version="1.0" encoding="UTF-8"?>
<results>
<data>
<title>TCP/IP Illustrated</title> is $9.5 less expensive than the average.</data>
<data>
<title>Advanced Programming in the Unix Environment</title> is $9.5 less expensive than the average.</data>
<data>
<title>Data on the Web</title> is $35.5 less expensive than the average.</data>
<data>
<title>The Economics of Technology and Content for Digital TV</title> is $54.499999999999986 more expensive than the average.</data>
</results>List the titles and years of all books published by Addison-Wesley after 1991, in alphabetic order.
<bib>
{
for $b in doc("bib.xml")//book[publisher = "Addison-Wesley"]
order by ($b/title)
return
<book>
{ $b/@year } { $b/title }
</book>
}
</bib>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<book year="1992">
<title>Advanced Programming in the Unix Environment</title>
</book>
<book year="1994">
<title>TCP/IP Illustrated</title>
</book>
</bib>
Adapted from XML Query Use Cases
ascending
descending
empty greatest
empty least
collation "name"
<bib>
{
for $b in doc("bib.xml")//book[publisher = "Addison-Wesley"]
order by ($b/title) descending
return
<book>
{ $b/@year } { $b/title }
</book>
}
</bib>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<book year="1994">
<title>TCP/IP Illustrated</title>
</book>
<book year="1992">
<title>Advanced Programming in the Unix Environment</title>
</book>
</bib>Adapted from XML Query Use Cases
Sample data at "reviews.xml":
<?xml version="1.0"?>
<reviews>
<entry>
<title>Data on the Web</title>
<price>34.95</price>
<review>
A very good discussion of semi-structured database
systems and XML.
</review>
</entry>
<entry>
<title>Advanced Programming in the Unix Environment</title>
<price>65.95</price>
<review>
A clear and detailed discussion of UNIX programming.
</review>
</entry>
<entry>
<title>TCP/IP Illustrated</title>
<price>65.95</price>
<review>
One of the best books on TCP/IP.
</review>
</entry>
</reviews>
Adapted from XML Query Use Cases
<!ELEMENT reviews (entry*)>
<!ELEMENT entry (title, price, review)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ELEMENT review (#PCDATA)>
For each book found in both bib.xml and reviews.xml, list the title of the book and its price from each source.
<books-with-prices>
{
for $b in doc("bib.xml")//book,
$a in doc("reviews.xml")//entry
where $b/title = $a/title
return
<book-with-prices>
{ $b/title },
<price-amazon> { $a/price/text() } </price-amazon>
<price-bn> { $b/price/text() } </price-bn>
</book-with-prices>
}
</books-with-prices>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<books-with-prices>
<book-with-prices>
<title>TCP/IP Illustrated</title>,
<price-amazon>65.95</price-amazon>
<price-bn>65.95</price-bn>
</book-with-prices>
<book-with-prices>
<title>Advanced Programming in the Unix Environment</title>,
<price-amazon>65.95</price-amazon>
<price-bn>65.95</price-bn>
</book-with-prices>
<book-with-prices>
<title>Data on the Web</title>,
<price-amazon>34.95</price-amazon>
<price-bn>39.95</price-bn>
</book-with-prices>
</books-with-prices>
Adapted from XML Query Use Cases
The next query also uses an input document named "prices.xml":
<?xml version="1.0"?>
<prices>
<book>
<title>Advanced Programming in the Unix Environment</title>
<source>www.amazon.com</source>
<price>65.95</price>
</book>
<book>
<title>Advanced Programming in the Unix Environment</title>
<source>www.bn.com</source>
<price>65.95</price>
</book>
<book>
<title>TCP/IP Illustrated</title>
<source>www.amazon.com</source>
<price>65.95</price>
</book>
<book>
<title>TCP/IP Illustrated</title>
<source>www.bn.com</source>
<price>65.95</price>
</book>
<book>
<title>Data on the Web</title>
<source>www.amazon.com</source>
<price>34.95</price>
</book>
<book>
<title>Data on the Web</title>
<source>www.bn.com</source>
<price>39.95</price>
</book>
</prices>
Adapted from XML Query Use Cases
In the document "prices.xml", find the minimum price for each book, in the
form of a minprice element with the book title as its
title attribute.
<results>
{
let $doc := doc("prices.xml")
for $t in distinct-values($doc/prices/book/title)
let $p := $doc/prices/book[title = $t]/price
return
<minprice title="{$t}">
{ min($p) }
</minprice>
}
</results>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<results>
<minprice title="Advanced Programming in the Unix Environment">65.95</minprice>
<minprice title="TCP/IP Illustrated">65.95</minprice>
<minprice title="Data on the Web">34.95</minprice>
</results>Adapted from XML Query Use Cases
For each book with an author, return a
book with its title and authors. For
each book with an editor, return a
reference with the book title and the
editor's affiliation.
<bib>
{
for $b in doc("bib.xml")//book[author]
return
<book>
{ $b/title }
{ $b/author }
</book>,
for $b in doc("bib.xml")//book[editor]
return
<reference>
{ $b/title }
<org> { $b/editor/affiliation/text() } </org>
</reference>
}
</bib>Adapted from XML Query Use Cases
<?xml version="1.0" encoding="UTF-8"?>
<bib>
<book>
<title>TCP/IP Illustrated</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
</book>
<book>
<title>Advanced Programming in the Unix Environment</title>
<author>
<last>Stevens</last>
<first>W.</first>
</author>
</book>
<book>
<title>Data on the Web</title>
<author>
<last>Abiteboul</last>
<first>Serge</first>
</author>
<author>
<last>Buneman</last>
<first>Peter</first>
</author>
<author>
<last>Suciu</last>
<first>Dan</first>
</author>
</book>
<reference>
<title>The Economics of Technology and Content for Digital TV</title>
<org>CITI</org>
</reference>
</bib>
Adapted from XML Query Use Cases
Several namespace declarations are "understood":
xml = http://www.w3.org/XML/1998/namespace
xs = http://www.w3.org/2001/XMLSchema
xsi = http://www.w3.org/2001/XMLSchema-instance
fn = http://www.w3.org/2005/xpath-functions
xdt = http://www.w3.org/2005/xpath-datatypes
err = http://www.w3.org/2005/xqt-errors
Customary namespace declarations can be used in element constructors, much as in XSLT. For example,
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:html="http://www.w3.org/1999/xhtml">
<head>
{
let $title := doc('http://www.cafeconleche.org/')//html:title
return $title
}
</head>
</html>Alternately, you can declare the namespace in the query's prolog, like so:
declare namespace html= "http://www.w3.org/1999/xhtml";
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
{
let $title := doc('http://www.cafeconleche.org/')//html:title
return $title
}
</head>
</html>Usual rules about the nearest conflicting namespace declaration taking precedence apply
Output:
<?xml version="1.0" encoding="UTF-8"?>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Cafe con Leche XML News and Resources</title>
</head>
</html>Michael Kay's Saxon 8: http://saxon.sourceforge.net/
XQuisitor: http://www.cafeconleche.org/xquisitor/
eXist
Berkeley dbXML
Bell Labs' Galax: http://www.galaxquery.org/
Xavier Franc's Qizx/open: http://www.axyana.com/qizxopen, an open source impementation of XQuery, written in Java. It conforms to XQuery Basic with Static Type Checking.
Mark Logic Server: http://www.cerisent.com/products/ml_server.html
Software AG's Tamino: http://www.softwareag.com/tamino/
Ipedo: http://www.ipedo.com/
Cognetic Systems's XQuantum: http://www.cogneticsystems.com/xquery/xquery.html
Fatdog's XQEngine: http://xqengine.sourceforge.net/
GAEL's Derby: http://www.gael.fr/derby/
Qexo (Kawa-Query): http://www.qexo.org/ Compiles XQuery on-the-fly to Java bytecodes. Based on and part of the Kawa framework. Open-source.
IPSI's IPSI-XQ: http://ipsi.fhg.de/oasys/projects/ipsi-xq/index_e.html
Microsoft's XML Query Language Demo: http://xqueryservices.com
Oracle Database 10g Release 2: http://www.oracle.com/technology/tech/xml/xquery/index.html
QuiLogic's SQL/XML-IMDB: http://www.quilogic.cc/xml.htm
Chris Wilper's XQuench: http://xquench.sourceforge.net/ Open-source.
X-Hive's XQuery demo: http://www.x-hive.com/xquery
XSLT is document-driven; XQuery is program driven
XSLT is functional; XQuery is declarative
XSLT is written in XML; XQuery is not
An assertion (unproven): XSLT 2.0 can do everything XQuery can do
Used by XSLT 2.0 and XQuery
Schema Aware
Simplify manipulation of XML Schema-typed content
Simplify manipulation of string content
Support related XML standards
Improve ease of use
Improve interoperability
Improve internationalization (i18n) support
Maintain backward compatibility
Enable improved processor efficiency
Basic syntax
Location paths and location steps
Axes: parent, child, ancestor, ancestor-or-self, self, descendant, descendant-or-self, following, following-sibling, preceding, preceding-sibling, attribute, namespace
However, support for the ancestor, ancestor-or-self, following, following-sibling, preceding, and preceding-sibling axes are optional in XQuery. XQuery implementations cannot use the namespace axis.
Node tests
Predicates
Abbreviated syntax: *, @*, //, etc.
Operators: +, -, div, mod, *, etc.
All functions, but they are now more strongly typed and don't always behave exactly the same
Basic expression syntax, though this has been greatly expanded
Most XPath 1.0 expressions are still legal XPath 2.0 expressions that mean pretty much the same thing.
fn:node-name(Node)fn:string(Object)fn:data(Node)fn:base-uri(node)fn:document-uri(node)Create a simple type from a string
Constructors are in the
http://www.w3.org/2001/XMLSchema-datatypes
namespace which is "understood" to be mapped to the xs prefix
Numeric constructors:
xs:decimal(string $srcval) => decimal
xs:integer(string $srcval) => integer
xs:long(string $srcval) => integer
xs:int(string $srcval) => integer
xs:short(string $srcval) => integer
xs:byte(string $srcval) => integer
xs:float(string $srcval) => float
xs:double(string $srcval) => double
xs:nonPositiveInteger($arg as xdt:anyAtomicType) => xs:nonPositiveInteger
xs:negativeInteger($arg as xdt:anyAtomicType) => xs:negativeInteger
xs:long($arg as xdt:anyAtomicType) => xs:long
xs:int($arg as xdt:anyAtomicType) => xs:int
xs:short($arg as xdt:anyAtomicType) => xs:short
xs:byte($arg as xdt:anyAtomicType) => xs:byte
xs:nonNegativeInteger($arg as xdt:anyAtomicType) => xs:nonNegativeInteger
xs:unsignedLong($arg as xdt:anyAtomicType) => xs:unsignedLong
xs:unsignedInt($arg as xdt:anyAtomicType) => xs:unsignedInt
xs:unsignedShort($arg as xdt:anyAtomicType) => xs:unsignedShort
xs:unsignedByte($arg as xdt:anyAtomicType) => xs:unsignedByte
xs:positiveInteger($arg as xdt:anyAtomicType) => xs:positiveInteger
String constructors
xs:string(string $srcval) => string
xs:normalizedString(string $srcval) => normalizedString
xs:token(string $srcval) => token
xs:language(string $srcval) => language
xs:Name(string $srcval) => Name
xs:NMTOKEN(string $srcval) => NMTOKEN
xs:NCName(string $srcval) => NCName
xs:ID(string $srcval) => ID
xs:IDREF(string $srcval) => IDREF
xs:ENTITY(string $srcval) => ENTITY
xs:QName(string $srcval) => QName
Boolean constructors:
xs:boolean(string $srcval) => boolean
Duration and Datetime constructors:
xs:duration(string $srcval) => duration
xs:dateTime(string $srcval) => dateTime
xs:date(string $srcval) => date
xs:time(string $srcval) => time
xs:gYearMonth(string $srcval) => gYearMonth
xs:gYear(string $srcval) => gYear
xs:gMonthDay(string $srcval) => gMonthDay
xs:gMonth(string $srcval) => gMonth
xs:gDay(string $srcval) => gDay
xdt:yearMonthDuration($arg as xdt:anyAtomicType) => xdt:yearMonthDuration
xdt:dayTimeDuration($arg as xdt:anyAtomicType) => xdt:dayTimeDuration
Constructor for anyURI:
xs:anyURI(string $srcval) => anyURI
Constructors for NOTATION:
xs:NOTATION(string $srcval) => NOTATION
Binary types:
xs:hexBinary($arg as xdt:anyAtomicType) => xs:hexBinary
xs:base64Binary($arg as xdt:anyAtomicType) => xs:base64Binary
Untyped type:
xdt:untypedAtomic($arg as xdt:anyAtomicType) as xdt:untypedAtomic
instance of tests the type of an item against the QName of a type
Casting changes the type of an item
Not all casts are legal, but mostly it works like you'd expect.
castable returns true if the cast is possible, false otherwise
item cast as type permanently changes the type of an item
item treat as type temporarily changes
the type
of the item for this expression only
if ($x castable as xs:gYear) then
$x cast as xs:gYear
else if ($x castable as xs:integer) then
$x cast as xs:integer
else if ($x castable as xs:decimal) then
$x cast as xs:decimal
else
$x cast as stringValue comparisons: compare a single value to a single value of a comparable type for equality
General comparisons: compare a sequence to a sequence for equality of at least one pair of members
Node comparisons: test for node identity
Order comparisons: compare document order
Compare single values and sequences of single or no values:
eq
ne
lt
le
gt
ge
These operators return either true, false, the empty sequence, an error, or a type exception.
Types must be comparable (No automatic conversion from strings as in XPath 1.0!):
Subtype substitution: A derived type may substitute for its base type. In particular, integer may be used where decimal is expected.
Type promotion: decimal may be promoted to float, and float may be promoted to double.
Compare one sequence to another sequence
True the condition is true for any pair of items from the two sequences
=
!=
<
<=
>
>=
These operators always return either true or false.
is
Only used on single nodes and empty sequences; otherwise a type error is raised.
Test for node identity like
Java's == operator, not the
equals() method
>> and << compare single nodes
for document order
The << operator returns true
if the first operand node is reachable from the second operand node
using the
preceding axis; otherwise it returns false.
The >> operator returns true
if the first operand node is reachable from the second operand node
using the following axis; otherwise it returns false.
Functions are identified by the fn prefix
The function prefix is understood in XQuery, without being explicitly stated.
Operators are indicated by the op:
prefix
XPath implementations such as XQuery and XSLT map the operators to symbols like * and +
+: op:numeric-add(numeric $operand1, numeric $operand2) => numeric
-: op:numeric-subtract(numeric $operand1, numeric $operand2) => numeric
*: op:numeric-multiply(numeric $operand1, numeric $operand2) => numeric
div: op:numeric-divide(numeric $operand1, numeric $operand2) => numeric
idiv: op:numeric-integer-divide(integer $operand1, integer $operand2) => integer
mod: op:numeric-mod(numeric $operand1, numeric $operand2) => numeric
+: op:numeric-unary-plus(numeric $operand) => numeric
-: op:numeric-unary-minus(numeric $operand) => numeric
fn:abs(double? $srcval) => double?
fn:floor(double? $srcval) => integer?
fn:ceiling(double? $srcval) => integer?
fn:round(double? $srcval) => integer?
fn:round-half-to-even(double? $srcval) => integer?
fn:codepoints-to-string( $arg as xs:integer*) => xs:string
fn:string-to-codepoints( $arg as xs:string?) => xs:integer*
fn:concat() => string
fn:concat(string? $op1) => string
fn:concat(string? $op1, string? $op2, ...) => string
fn:string-join(string* $operand1, string* $operand2) => string
fn:starts-with(string? $operand1, string? $operand2) => boolean?
fn:starts-with(string? $operand1, string? $operand2, anyURI $collationLiteral) => boolean?
fn:ends-with(string? $operand1, string? $operand2) => boolean?
fn:ends-with(string? $operand1, string? $operand2, anyURI $collationLiteral) => boolean?
fn:contains(string? $operand1, string? $operand2) => boolean?
fn:contains(string? $operand1, string? $operand2, anyURI $collationLiteral) => boolean?
fn:substring(string? $sourceString, decimal? $startingLoc) => string?
fn:substring(string? $sourceString, decimal? $startingLoc, decimal? $length) => string?
fn:string-length(string? $srcval) => integer?
fn:substring-before(string? $operand1, string? $operand2) => string?
fn:substring-before(string? $operand1, string? $operand2, anyURI $collationLiteral) => string?
fn:substring-after(string? $operand1, string? $operand2) => string?
fn:substring-after(string? $operand1, string? $operand2, anyURI $collationLiteral) => string?
fn:normalize-space(string? $srcval) => string?
fn:normalize-unicode(string? $srcval, string $normalizationForm) => string?
fn:upper-case(string? $srcval) => string?
fn:lower-case(string? $srcval) => string?
fn:translate(string? $srcval, string? $mapString, string? $transString) => string?
fn:matches(string? $srcval, string? $regexp) => integer*
fn:replace(string? $srcval, string? $regexp, string? $repval) => string?
fn:tokenize(string? $input as string?, string? $pattern) => string*
fn:tokenize(string? $input as string?, string? $pattern as string?, string? $flags) => string*
fn:escape-uri(string $uri-part as string, boolean $escape-reserved) => string
Syntax for fn:matches()
is based on W3C XML Schema Language
regular expressions:
Syntax for fn:replace() is based
on W3C XML Schema Language
regular expressions plus $N in replace patterns to indicate the
Nth match.
and: op:boolean-and(boolean $value1, boolean $value2) => boolean
or: op:boolean-or(boolean $value1, boolean $value2) => boolean
eq: op:boolean-equal(boolean? $value1, boolean? $value2) => boolean?
fn:not(boolean? $srcval) => boolean
xs:duration is underspecified so new xdt:yearMonthDuration and xdt:dayTimeDuration types are defined.
op:add-yearMonthDurations( $arg1 as xdt:yearMonthDuration,
$arg2 as xdt:yearMonthDuration) => xdt:yearMonthDuration
op:subtract-yearMonthDurations( $arg1 as xdt:yearMonthDuration,
$arg2 as xdt:yearMonthDuration) => xdt:yearMonthDuration
op:multiply-yearMonthDuration( $arg1 as xdt:yearMonthDuration,
$arg2 as xs:double) => xdt:yearMonthDuration
op:divide-yearMonthDuration( $arg1 as xdt:yearMonthDuration,
$arg2 as xs:double) => xdt:yearMonthDuration
op:add-dayTimeDurations( $arg1 as xdt:dayTimeDuration,
$arg2 as xdt:dayTimeDuration) => xdt:dayTimeDuration
op:subtract-dayTimeDurations( $arg1 as xdt:dayTimeDuration,
$arg2 as xdt:dayTimeDuration) => xdt:dayTimeDuration
op:multiply-dayTimeDuration( $arg1 as xdt:dayTimeDuration,
$arg2 as xs:double) => xdt:dayTimeDuration
op:divide-dayTimeDuration( $arg1 as xdt:dayTimeDuration,
$arg2 as xs:double) => xdt:dayTimeDuration
Comparisons of Duration and Datetime Values:
op:duration-equal(duration $operand1, duration $operand2) => boolean
op:gYearMonth-equal(gYearMonth $operand1, gYearMonth $operand2) => boolean
op:gYear-equal(gYear $operand1, gYear $operand2) => boolean
op:gMonthDay-equal(gMonthDay $operand1, gMonthDay $operand2) => boolean
op:gMonth-equal(gMonth $operand1, gMonth $operand2) => boolean
op:gDay-equal(gDay $operand1, gDay $operand2) => boolean
op:yearMonthDuration-equal(yearMonthDuration $operand1, yearMonthDuration $operand2) => boolean
op:yearMonthDuration-less-than(yearMonthDuration $operand1, yearMonthDuration $operand2) => boolean
op:yearMonthDuration-greater-than(yearMonthDuration $operand1, yearMonthDuration $operand2) => boolean
op:dayTimeDuration-equal(dayTimeDuration $operand1, dayTimeDuration $operand2) => boolean
op:dayTimeDuration-less-than(dayTimeDuration $operand1, dayTimeDuration $operand2) => boolean
op:dayTimeDuration-greater-than(dayTimeDuration $operand1, dayTimeDuration $operand2) => boolean
op:dateTime-equal(dateTime $operand1, dateTime $operand2) => boolean
op:dateTime-less-than(dateTime $operand1, dateTime $operand2) => boolean
op:dateTime-greater-than(dateTime $operand1, dateTime $operand2) => boolean
op:time-equal(time $operand1, time $operand2) => boolean
op:time-less-than(time $operand1, time $operand2) => boolean
op:time-greater-than(time $operand1, time $operand2) => boolean
op:date-equal(date $operand1, date $operand2) => boolean
op:date-less-than(date $operand1, date $operand2) => boolean
op:date-greater-than(date $operand1, date $operand2) => boolean
Component Extraction Functions on Duration, Date and Time Values:
fn:get-years-from-yearMonthDuration(yearMonthDuration $srcval) => integer
fn:get-months-from-yearMonthDuration(yearMonthDuration $srcval) => integer
fn:get-days-from-dayTimeDuration(dayTimeDuration $srcval) => integer
fn:get-hours-from-dayTimeDuration(dayTimeDuration $srcval) => integer
fn:get-minutes-from-dayTimeDuration(dayTimeDuration $srcval) => integer
fn:get-seconds-from-dayTimeDuration(dayTimeDuration $srcval) => integer
fn:get-year-from-dateTime(dateTime $srcval) => integer
fn:get-month-from-dateTime(dateTime $srcval) => integer
fn:get-day-from-dateTime(dateTime $srcval) => integer
fn:get-hours-from-dateTime(dateTime $srcval) => integer
fn:get-minutes-from-dateTime(dateTime $srcval) => integer
fn:get-seconds-from-dateTime(dateTime $srcval) => integer
fn:get-timezone-from-dateTime(dateTime $srcval) => integer
fn:get-year-from-date(date $srcval) => integer
fn:get-month-from-date(date $srcval) => integer
fn:get-day-from-date(date $srcval) => integer
fn:get-timezone-from-date(date $srcval) => integer
fn:get-hours-from-time(time $srcval) => integer
fn:get-minutes-from-time(time $srcval) => integer
fn:get-seconds-from-time(time $srcval) => integer
fn:get-timezone-from-time(time $srcval) => integer
Time zone adjustment
fn:adjust-dateTime-to-timezone( $arg as xs:dateTime?) => xs:dateTime?
fn:adjust-dateTime-to-timezone( $arg as xs:dateTime?,
$timezone as xdt:dayTimeDuration?) => xs:dateTime?
fn:adjust-date-to-timezone( $arg as xs:date?) => xs:date?
fn:adjust-date-to-timezone( $arg as xs:date?,
$timezone as xdt:dayTimeDuration?) => xs:date?
fn:adjust-time-to-timezone( $arg as xs:time?) => xs:time?
fn:adjust-time-to-timezone( $arg as xs:time?,
$timezone as xdt:dayTimeDuration?) => xs:time?
Adding and Subtracting Durations From dateTime, date and time:
fn:subtract-dateTimes-yielding-yearMonthDuration( $arg1 as xs:dateTime?,
$arg2 as xs:dateTime?) => xdt:yearMonthDuration?
fn:subtract-dateTimes-yielding-dayTimeDuration( $arg1 as xs:dateTime?,
$arg2 as xs:dateTime?) => xdt:dayTimeDuration?
op:subtract-dates($arg1 as xs:date?, $arg2 as xs:date?) => xdt:dayTimeDuration?
op:subtract-times($arg1 as xs:time?, $arg2 as xs:time?) => xdt:dayTimeDuration?
op:add-yearMonthDuration-to-dateTime( $arg1 as xs:dateTime,
$arg2 as xdt:yearMonthDuration) => xs:dateTime
op:add-dayTimeDuration-to-dateTime( $arg1 as xs:dateTime,
$arg2 as xdt:dayTimeDuration) => xs:dateTime
op:subtract-yearMonthDuration-from-dateTime( $arg1 as xs:dateTime,
$arg2 as xdt:yearMonthDuration) => xs:dateTime
op:subtract-dayTimeDuration-from-dateTime( $arg1 as xs:dateTime,
$arg2 as xdt:dayTimeDuration) => xs:dateTime
op:add-yearMonthDuration-to-date( $arg1 as xs:date,
$arg2 as xdt:yearMonthDuration) => xs:date
op:add-dayTimeDuration-to-date( $arg1 as xs:date,
$arg2 as xdt:dayTimeDuration) => xs:date
op:subtract-yearMonthDuration-from-date( $arg1 as xs:date,
$arg2 as xdt:yearMonthDuration) => xs:date
op:subtract-dayTimeDuration-from-date( $arg1 as xs:date,
op:add-dayTimeDuration-to-time( $arg1 as xs:time,
$arg2 as xdt:dayTimeDuration) => xs:time
op:subtract-dayTimeDuration-from-time( $arg1 as xs:time,
$arg2 as xdt:dayTimeDuration) => xs:time
fn:QName-in-context(string $qname, boolean $use-default) => QName
fn:QName-in-context(string $qname, boolean $use-default, node $node) => QName
fn:get-local-name-from-QName(QName? $srcval) => string?
fn:get-namespace-uri-from-QName(QName? $srcval) => anyURI?
fn:get-namespace-uri-for-prefix(element $element, string $prefix) => string?
fn:get-in-scope-prefixes(element $element) => string*
fn:resolve-QName($qname as xs:string?, $element as element()?) => xs:QName?
fn:expanded-QName($paramURI as xs:string?, $paramLocal as xs:string) => xs:QName
fn:name() => string
fn:name(node $srcval) => string
fn:local-name() => string
fn:local-name(node $srcval) => string
fn:namespace-uri() => string
fn:namespace-uri(node $srcval) => string
fn:root() => node
fn:root(node $srcval) => node
fn:number() => double
fn:number(node $srcval) => double
fn:lang(string $testlang) => boolean
fn:boolean(item* $srcval) => boolean
,: op:concatenate(item* $seq1, item* $seq2) => item*
op:item-at(item* $seqParam, decimal $posParam) => item?
fn:index-of(item* $seqParam, item $srchParam) => unsignedInt?
fn:index-of(item* $seqParam, item $srchParam, anyURI $collationLiteral) => unsignedInt?
fn:empty(item* $srcval) => boolean
fn:exists(item* $srcval) => boolean
fn:distinct-values(item* $srcval) => item*
fn:distinct-values(item* $srcval, anyURI $collationLiteral) => item*
fn:insert-before(item* $target, decimal $position, item* $inserts) => item*
fn:remove(item* $target, decimal $position) => item*
fn:reverse($arg as item()*) => item()*
fn:unordered($sourceSeq as item()*) => item()*
fn:subsequence(item* $sourceSeq, decimal $startingLoc) => item*
fn:subsequence(item* $sourceSeq, decimal $startingLoc, decimal $length) => item*
fn:deep-equal(item* $parameter1, item* $parameter2) => boolean?
fn:deep-equal(item* $parameter1, item* $parameter2, anyURI $collationLiteral) => boolean?
fn:count(item* $srcval) => unsignedInt
fn:avg(item* $srcval) => double?
fn:max(item* $srcval) => anySimpleType?
fn:max(item* $srcval, anyURI $collationLiteral) => anySimpleType?
fn:min(item* $srcval) => anySimpleType?
fn:min(item* $srcval, anyURI $collationLiteral) => anySimpleType?
fn:avg(item* $srcval) => double?
fn:max(item* $srcval) => double?
fn:min(item* $srcval) => double?
fn:sum(item* $srcval) => double?
fn:id(IDREF* $srcval) => elementNode*
fn:idref(string* $srcval) => elementNode*
fn:collection(string $srcval) => node*
fn:input() => node*
fn:doc(string? $srcval) => node?
fn:zero-or-one($arg as item()*) => item()?fn:one-or-more($arg as item()*) => item()?fn:exactly-one($arg as item()*) => item()?fn:position() => unsignedInt
fn:last() => unsignedInt
op:context-document() => DocumentNode
fn:current-dateTime() => dateTime
fn:current-time() => time
fn:current-date() => date
fn:default-collation() => anyURI?
fn:implicit-timezone() => dayTimeDuration?
Comments
Namespace wildcards
Functions as location steps
Parenthesized expressions as location steps
Dereference steps
For Expressions
Conditional Expressions
Quantified Expressions
(: This is an XPath comment :)
<xsl:apply-templates
select="(: The difference between the context node and the
current node is crucial here :)
../composition[@composer=current()/@id]"/><xsl:template match="*:set">
This matches MathML set elements, SVG set elements, set
elements in no namespace at all, etc.
</xsl:template>The doc() function returns the root of a document at a given URL
doc("http://www.cafeconleche.org/")//today
/child::contacts/(child::personal | child::business)/child::name
Abbreviated: /contacts/(personal | business)/name
Map an IDREF attribute node to the element it refers to
Composers and their compositions are linked through the
an ID-type
id attribute of the composer element
and the IDREF-type composer attribute of the
composition element:
<composer id="c3">
<name>
<first_name>Beth</first_name>
<middle_name></middle_name>
<last_name>Anderson</last_name>
</name>
</composer>
<composition composers="c3">
<title>Trio: Dream in D</title>
<date><year>(1980)</year></date>
<length>10'</length>
<instruments>fl, pn, vc, or vn, pn, vc</instruments>
<description>
Rhapsodic. Passionate. Available on CD
<cite><a href="http://www.amazon.com/exec/obidos/ASIN/B000007NMH/qid%3D913265342/sr%3D1-2/">Two by Three</a></cite>
from North/South Consonance (1998).
</description>
<publisher></publisher>
</composition>
With XPath 1.0:
<xsl:template match="composition">
<h2>
<xsl:value-of select="name"/> by
<xsl:value-of select="../composer[@id=current()/@composer]"/>
</h2>
</xsl:template>With XPath 2.0:
<xsl:template match="composition">
<h2>
<xsl:value-of select="name"/> by
<xsl:value-of select="@composers=>composer/name"/>
</h2>
</xsl:template>Useful for joining documents
Useful for restructuring data
Syntax:
for $var1 in expression, $var2 in expression...
return expressionConsider the list of weblogs at http://static.userland.com/weblogMonitor/logs.xml
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd">
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl></imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description></description>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
The changesUrl element points to a document like
this:
<?xml version="1.0"?>
<!DOCTYPE rss PUBLIC "-//Netscape Communications//DTD RSS 0.91//EN"
"http://my.netscape.com/publish/formats/rss-0.91.dtd">
<rss version="0.91">
<channel>
<title>MozillaZine</title>
<link>http://www.mozillazine.org/</link>
<language>en-us</language>
<description>Your source for Mozilla news, advocacy, interviews, builds, and more!</description>
<copyright>Copyright 1998-2002, The MozillaZine Organization</copyright>
<managingEditor>jason@mozillazine.org</managingEditor>
<webMaster>jason@mozillazine.org</webMaster>
<image>
<title>MozillaZine</title>
<url>http://www.mozillazine.org/image/mynetscape88.gif</url>
<description>Your source for Mozilla news, advocacy, interviews, builds, and more!</description>
<link>http://www.mozillazine.org/</link>
</image>
<item>
<title>BugDays Are Back!</title>
<link>http://www.mozillazine.org/talkback.html?article=2151</link>
</item>
<item>
<title>Independent Status Reports</title>
<link>http://www.mozillazine.org/talkback.html?article=2150</link>
</item>
</channel>
</rss>
We want to process all the item elements from each weblog.
<xsl:template match="weblogs">
<xsl:apply-templates select="
for $url in log/changesUrl
return doc($url)//item
"/>
</xsl:template>if ( expression) then expression else expression
Not all weblogs have a changesUrl
<xsl:template match="log">
<xsl:apply-templates select="
if (changesUrl)
then document(changesUrl)
else document(url)"/>
</xsl:template>some $QualifedName in expression satisfies expression
every $QualifedName in expression satisfies expression
Both return boolean values, true or false
<xsl:template match="weblogs">
<xsl:if test="some $log in log satisfies changesURL">
At least one log has a changesURL
</xsl:if>
</xsl:template>
<xsl:template match="weblogs">
<xsl:if test="every $log in log satisfies url">
Every log has a url
</xsl:if>
</xsl:template>"Documents vs. Data"?
"Documents and Data"?
Or "Documents are Data"
Traditionally we have distinguished between documents, which are static, linear files that live in a file system and data, which are small chunks of information that are stored in a database. Much, perhaps most, PHP is little more than a glue language for inserting data into templates to form documents. Ditto for many report generation tools.
What if we break down the walls? Suppose everything goes into the database, not just the "data"? A single controller turns every request to the web server into a database query. Everything is stored in one place, and gets the benefits of the database: ACID, backups, distribution, professional management, etc. Everything can be queried, and the architecture is simpler: one piece (a database) instead of two (database+file system). Furthermore the system is more flexible. Modern web servers are still crippled by the assumption that what they're doing is serving files, and that the URL structure maps to a file system. That's too limiting, especially for fully RESTful applications. To enable the next generation of web applications, we need to pull the file system out from under the web servers and teach developers to think in terms of URL design and database queries. SQL is too limited to handle data this broad. XQuery can.
This presentation: http://www.cafeconleche.org/slides/sd2008west/xmldb
XQuery: A Query Language for XML: http://www.w3.org/TR/xquery/
XML Query Requirements: http://www.w3.org/TR/xmlquery-req
XML Query Use Cases: http://www.w3.org/TR/xmlquery-use-cases
XML Query Data Model: http://www.w3.org/TR/query-datamodel/
The XML Query Algebra: http://www.w3.org/TR/query-algebra/
XML Syntax for XQuery 1.0 (XQueryX): http://www.w3.org/TR/xqueryx
XSLT 2.0 and XQuery 1.0 Serialization: http://www.w3.org/TR/xslt-xquery-serialization/
XQuery 1.0 and XPath 2.0 Functions and Operators Version 1.0: http://www.w3.org/TR/xquery-operators/
XPath 2.0: http://www.w3.org/TR/xpath20
XPath 2.0 Requirements: http://www.w3.org/TR/xpath20req
XSLT 2.0: http://www.w3.org/TR/xslt20
XSLT 2.0 Requirements: http://www.w3.org/TR/xslt20req