
The Web conquered gopher for one reason: HTML made it possible to embed hypertext links in documents.
HTML linking has limits
You can only link to one document at a time
You must link to the entire document.
Once the link is traversed the trail of where you've been is lost.
Includes are server dependent and don't work across domains
Links break
Linking in XML is divided into multiple parts:
A Uniform Resource Identifier (URI) names or locates a resource
An XLink defines connections between two or more documents identified by URIs
XPath identifies particular nodes within a document
An XPointer adds an XPath to a URI
XML Base (a.k.a. XBase) defines the URI against which relative URIs are resolved
XInclude embeds a document identified by a URI inside an XML document.
<?xml version="1.0"?>
<story date="January 9, 2001"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:xinclude="http://www.w3.org/1999/XML/xinclude"
xml:base="http://www.cafeaulait.org/">
<p>
The W3C XML Linking Working Group has pushed the
<link xlink:type="simple"
xlink:href="http://www.w3.org/TR/2001/WD-xptr-20010108">
XPointer specification
</link>
back to working draft status. The specific issue that was
uncovered during Candidate Recommendation was some
<link xlink:type="simple"
xlink:href="http://www.w3.org/TR/xptr#xpointer(//div[@class='div3'][7])">
confusion
</link>
over how to integrate XPointers, particularly those in non-XML documents,
with namespaces.
</p>
<p>
It's also come to light in this draft that Sun has
<link xlink:type="simple"
xlink:href=
"http://lists.w3.org/Archives/Public/www-xml-linking-comments/2000OctDec/0092.html"
>
claimed a patent</link> on some of the technologies needed to
implement XPointer. I think this is particularly offensive because Eve
L. Maler, a Sun employee, served as co-chair of the XML Linking
Working Group and a co-editor of the XPointer specification. As usual
Sun wants to use this as a club to lock implementers and users into a
licensing agreement that goes beyond what Sun and the W3C could
otherwise demand. The specific patent is <cite>United States Patent
No. 5,659,729, Method and system for implementing hypertext scroll
attributes</cite>, issued to Jakob Nielsen in 1997. The patent was
filed on February 1, 1996. It claims:
</p>
<blockquote>
<xinclude:include
href=
"http://www.delphion.com/details?&pn=US05659729__#xpointer(//abstract)"
>
</xinclude:include>
</blockquote>
</story>
This talk covers:
XLinks: June 27, 2001 Recommendation
XPointers: January 8, 2001 2nd Last Call Working Draft
XInclude: May 16, 2001 Last Call Working Draft
XML Base: June 27, 2001 Recommendation
Once you've tasted XLink's Chunky Monkey, it's hard to reconcile yourself to HTML's vanilla.--John E. Simpson on the xsl-list mailing list
Designed especially for use with XML
Multidirectional
Any element can be a link, not just <A>
Can link to arbitrary positions in the document
No general-purpose Web browsers or other applications support arbitrary XLinks.
XLinks have a much broader base of applicability than HTML links. They can be used by any custom application that needs to establish connections between documents and parts of documents, for any reason.
Even when XLinks are fully implemented in browsers they may not always be blue underlined text that you click to jump to another page.
Any element can be a link
XLink elements are identified by an xlink:type attribute with
one of these six values:
simple
extended
locator
arc
resource
title
Linking elements are identified by an xlink:type attribute with
one of these two values:
simple
extended
Each
linking element contains an xlink:href attribute whose
value is the URI of the resource being linked to.
An xmlns:xlink attribute associates the xlink
prefix with the http://www.w3.org/1999/xlink namespace.
<FOOTNOTE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="simple"
xlink:href="footnote7.xml">7</FOOTNOTE>
<COMPOSER xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="simple"
xlink:href="http://www.interport.net/~beand/">
Beth Anderson
</COMPOSER>
<IMAGE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="simple" xlink:href="logo.gif"/>
<!ELEMENT FOOTNOTE (#PCDATA)>
<!ATTLIST FOOTNOTE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
>
<!ELEMENT COMPOSER (#PCDATA)>
<!ATTLIST COMPOSER
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
>
<!ELEMENT IMAGE EMPTY>
<!ATTLIST IMAGE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
>
<FOOTNOTE xlink:href="footnote7.xml">7</FOOTNOTE>
<COMPOSER xlink:href="http://www.interport.net/~beand/">
Beth Anderson
</COMPOSER>
<IMAGE xlink:href="logo.gif"/>
<!ELEMENT IMAGE EMPTY>
<!ATTLIST IMAGE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
ALT CDATA #REQUIRED
HEIGHT CDATA #REQUIRED
WIDTH CDATA #REQUIRED
>
A link element may contain optional
xlink:role and xlink:title
attributes that describe the remote resource, that is, the
document or other resource to which the link points
The title contains a short plain text description.
The role contains a URI pointing to a long description.
<AUTHOR
xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:href="mailto:elharo@metalab.unc.edu"
xlink:title="Send email to Elliotte Rusty Harold"
xlink:role="http://www.macfaq.com/personal.html">
Please drop me a line.
</AUTHOR>
As with all other attributes, the
xlink:title and xlink:role
attributes should be declared in the DTD for all the
elements to which they belong. For example, this is a
reasonable declaration for the above AUTHOR
element:
<!ELEMENT AUTHOR (#PCDATA)>
<!ATTLIST AUTHOR
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
xlink:title CDATA #IMPLIED
xlink:role CDATA #IMPLIED
>
Linking elements can contain two more optional attributes that suggest to applications how the remote resource is associated with the current page. These are:
xlink:show suggests
where the content should be displayed when
the link is activated
xlink:actuate suggests whether the link should be traversed
automatically or whether a specific user request is required
These are application dependent, however, and applications are free to ignore the suggestions.
The xlink:show attribute has five predefined values:
replace
new
embed
other
none
Like all attributes in valid documents, the
xlink:show attribute must be declared in a
<!ATTLIST> declaration for the DTD's link
element. For example:
<!ELEMENT WEBSITE (#PCDATA)>
<!ATTLIST WEBSITE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
xlink:show (new | replace | embed) "replace"
>
A linking element's xlink:actuate attribute has
four predefined
values:
onRequest
onLoad
other
none
<IMAGE
xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="simple" xlink:href="logo.gif"
xlink:actuate="onLoad"/>
Like all attributes in valid documents, the
actuate attribute must be declared in the DTD
in a <!ATTLIST> declaration for the link
elements in which it appears. For example:
<!ELEMENT IMAGE EMPTY>
<!ATTLIST IMAGE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
xlink:show (new | replace | embed) "embed"
xlink:actuate (onRequest | onLoad) "onLoad"
>
<!ENTITY % link-attributes
"xlink:type CDATA #FIXED 'simple'
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED
xmlns:xlink CDATA #FIXED 'http://www.w3.org/1999/xlink'
xlink:href CDATA #REQUIRED
xlink:show (new | replace | embed) 'replace'
xlink:actuate (onRequest | onLoad) 'onRequest'"
>
<!ELEMENT COMPOSER (#PCDATA)>
<!ATTLIST COMPOSER
%link-attributes;
>
<!ELEMENT AUTHOR (#PCDATA)>
<!ATTLIST AUTHOR
%link-attributes;
>
<!ELEMENT WEBSITE (#PCDATA)>
<!ATTLIST WEBSITE
%link-attributes;
>
Simple links are very similar to HTML links, one-directional, one-element-to-one-document links
Extended links are multi-directional, many-to-many links
An extended link is a list of nodes and a list of the connections between them
An extended link is included in an XML document as an element of some arbitrary
type like COMPOSER or TEAM that has an
xlink:type attribute with the value
extended.
<WEBSITE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended">
...
</WEBSITE>
Extended links generally point to more than one target and from more than one source. Both sources and targets are called by the more generic word resource.
Resources are divided into remote resources and local resources.
A local resource is actually contained
inside the extended link element. It is enclosed in element of
arbitrary type that has an
xlink:type attribute with the value
resource.
A remote resource exists outside the extended link element, very possibly in
another document. The extended link element contains locator child elements that
point to the remote resource. These are elements with any name that have an
xlink:type attribute with the value locator.
Each locator element has an
xlink:href attribute whose value is
a URI locating the remote resource.
<WEBSITE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended">
<NAME xlink:type="resource">Cafe au Lait</NAME>
<HOMESITE xlink:type="locator"
xlink:href="http://ibiblio.org/javafaq/"/>
<MIRROR xlink:type="locator"
xlink:href="http://sunsite.kth.se/javafaq"/>
<MIRROR xlink:type="locator"
xlink:href="http://sunsite.informatik.rwth-aachen.de/javafaq/"/>
<MIRROR xlink:type="locator"
xlink:href="http://sunsite.cnlab-switch.ch/javafaq/"/>
</WEBSITE>
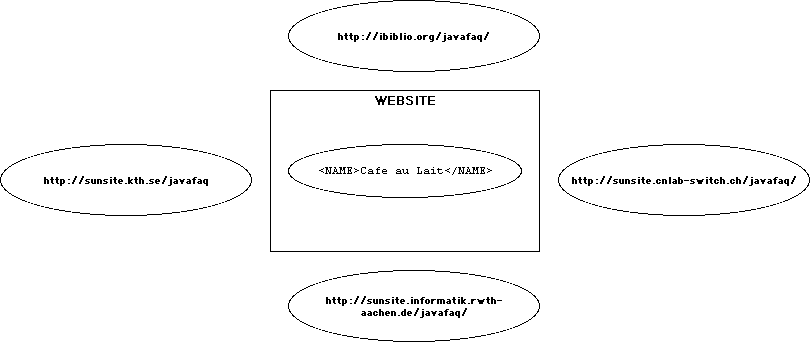
This WEBSITE element describes an extended link with five resources:
The text "Cafe au Lait", a local resource
The document at http://ibiblio.org/javafaq/, a remote resource
The document at http://sunsite.kth.se/javafaq, a remote resource
The document at http://sunsite.informatik.rwth-aachen.de/javafaq/, a remote resource
The document at http://sunsite.cnlab-switch.ch/javafaq/, a remote resource
Since one of the resources referenced by this extended link is contained in the extended link, it is called an inline link. It will be included as part of one of the documents it connects.
This picture shows the WEBSITE extended
link element and five resources, one of which WEBSITE contains,
the other four of which are referred to by URLs. However, this just
describes these resources. No connections are implied between them.
Both the extended link element itself and the individual
locator children may have descriptive attributes such as
xlink:role and xlink:title.
The
xlink:role and xlink:title attributes
of the extended link element provide default roles and titles
for each of the individual locator child elements.
Individual resource and
locator elements may override these defaults with
xlink:role and xlink:title attributes
of their own.
<WEBSITE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended" xlink:title="Cafe au Lait">
<NAME xlink:type="resource"
xlink:role="http://ibiblio.org/javafaq/">
Cafe au Lait
</NAME>
<HOMESITE xlink:type="locator"
xlink:href="http://ibiblio.org/javafaq/"
xlink:role="http://ibiblio.org/"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swedish Mirror"
xlink:role="http://sunsite.kth.se/"
xlink:href="http://sunsite.kth.se/javafaq"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait German Mirror"
xlink:role="http://sunsite.informatik.rwth-aachen.de/"
xlink:href=
"http://sunsite.informatik.rwth-aachen.de/javafaq/"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swiss Mirror"
xlink:role="http://sunsite.cnlab-switch.ch/"
xlink:href="http://sunsite.cnlab-switch.ch/javafaq/"/>
</WEBSITE>
<!ELEMENT WEBSITE (NAME, HOMESITE, MIRROR*) >
<!ATTLIST WEBSITE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type (extended) #FIXED "extended"
xlink:title CDATA #IMPLIED
xlink:role CDATA #IMPLIED
>
<!ELEMENT NAME (#PCDATA)>
<!ATTLIST NAME
xlink:type (resource) #FIXED "resource"
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED
>
<!ELEMENT HOMESITE (#PCDATA)>
<!ATTLIST HOMESITE
xlink:type (locator) #FIXED "locator"
xlink:href CDATA #REQUIRED
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED
>
<!ELEMENT MIRROR (#PCDATA)>
<!ATTLIST MIRROR
xlink:type (locator) #FIXED "locator"
xlink:href CDATA #REQUIRED
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED
>
<!ENTITY % extended.att
"xlink:type CDATA #FIXED 'extended'
xmlns:xlink CDATA #FIXED 'http://www.w3.org/1999/xlink'
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED"
>
<!ENTITY % resource.att
"xlink:type (resource) #FIXED 'resource'
xlink:href CDATA #REQUIRED
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED"
>
<!ENTITY % locator.att
"xlink:type (locator) #FIXED 'locator'
xlink:href CDATA #REQUIRED
xlink:role CDATA #IMPLIED
xlink:title CDATA #IMPLIED"
>
<!ELEMENT WEBSITE (HOMESITE, MIRROR*) >
<!ATTLIST WEBSITE
%extended.att;
>
<!ELEMENT NAME (#PCDATA)>
<!ATTLIST NAME
%resource.att;
>
<!ELEMENT HOMESITE (#PCDATA)>
<!ATTLIST HOMESITE
%locator.att;
>
<!ELEMENT MIRROR (#PCDATA)>
<!ATTLIST MIRROR
%locator.att;
>
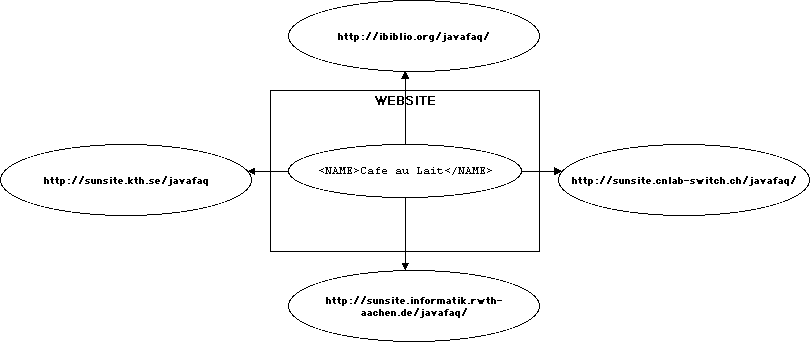
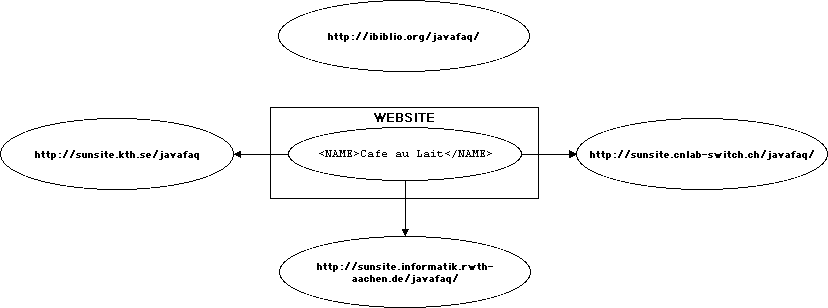
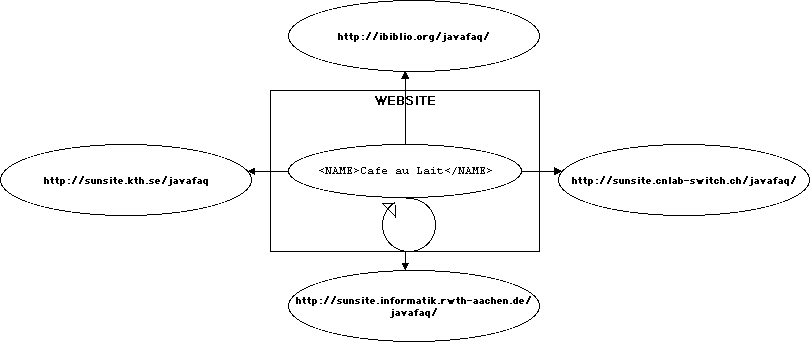
In an extended link with three resources, A, B, and C; there are nine different possible traversals.
These potential traversals are called arcs
Arcs are represented in XML by elements
that have an xlink:type attribute with the value arc.
Traversal rules are defined by
attaching xlink:actuate
and xlink:show
attributes to arc elements.
An arc element has an xlink:from attribute and an
xlink:to attribute.
These attributes match the xlink:label
attributes of the locator
element in the extended link from which traversal is initiated and to which the
traversal goes.
<?xml version="1.0"?>
<WEBSITE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended" xlink:title="Cafe au Lait">
<NAME xlink:type="resource" xlink:label="source">
Cafe au Lait
</NAME>
<HOMESITE xlink:type="locator"
xlink:href="http://ibiblio.org/javafaq/"
xlink:label="us"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swedish Mirror"
xlink:label="se"
xlink:href="http://sunsite.kth.se/javafaq"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait German Mirror"
xlink:label="de"
xlink:href="http://sunsite.informatik.rwth-aachen.de/javafaq/"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swiss Mirror"
xlink:label="ch"
xlink:href="http://sunsite.cnlab-switch.ch/javafaq/"/>
<CONNECTION xlink:type="arc" xlink:from="source"
xlink:to="ch" xlink:show="replace"
xlink:actuate="onRequest"/>
<CONNECTION xlink:type="arc" xlink:from="source"
xlink:to="us" xlink:show="replace"
xlink:actuate="onRequest"/>
<CONNECTION xlink:type="arc" xlink:from="source"
xlink:to="se" xlink:show="replace"
xlink:actuate="onRequest"/>
<CONNECTION xlink:type="arc" xlink:from="source"
xlink:to="sk" xlink:show="replace"
xlink:actuate="onRequest"/>
</WEBSITE>
<WEBSITE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended" xlink:title="Cafe au Lait">
<NAME xlink:type="resource" xlink:label="source">
Cafe au Lait
</NAME>
<HOMESITE xlink:type="locator"
xlink:href="http://ibiblio.org/javafaq/"
xlink:label="us"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swedish Mirror"
xlink:label="mirror"
xlink:href="http://sunsite.kth.se/javafaq"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait German Mirror"
xlink:label="mirror"
xlink:href="http://sunsite.informatik.rwth-aachen.de/javafaq/"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swiss Mirror"
xlink:label="mirror"
xlink:href="http://sunsite.cnlab-switch.ch/javafaq/"/>
<CONNECTION xlink:type="arc" xlink:from="source"
xlink:to="mirror" xlink:show="replace"
xlink:actuate="onRequest"/>
</WEBSITE>
<?xml version="1.0"?>
<WEBSITE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended" xlink:title="Cafe au Lait">
<NAME xlink:type="resource" xlink:label="source">
Cafe au Lait
</NAME>
<HOMESITE xlink:type="locator"
xlink:href="http://ibiblio.org/javafaq/"
xlink:label="us"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swedish Mirror"
xlink:label="se"
xlink:href="http://sunsite.kth.se/javafaq"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait German Mirror"
xlink:label="sk"
xlink:href="http://sunsite.informatik.rwth-aachen.de/javafaq/"/>
<MIRROR xlink:type="locator"
xlink:title="Cafe au Lait Swiss Mirror"
xlink:label="ch"
xlink:href="http://sunsite.cnlab-switch.ch/javafaq/"/>
<xlink:arc from="source" show="new" actuate="onRequest"/>
<CONNECTION xlink:type="arc" xlink:from="source"
xlink:show="replace" xlink:actuate="onRequest"/>
</WEBSITE>
<!ELEMENT WEBSITE (HOMESITE, MIRROR*, xlink:arc*) >
<!ATTLIST WEBSITE
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
xlink:type (extended) #FIXED "extended"
xlink:title CDATA #IMPLIED
xlink:label CDATA #IMPLIED
>
<!ELEMENT HOMESITE (#PCDATA)>
<!ATTLIST HOMESITE
xlink:type (locator) #FIXED "locator"
xlink:href CDATA #REQUIRED
xlink:label CDATA #REQUIRED
xlink:title CDATA #IMPLIED
>
<!ELEMENT MIRROR (#PCDATA)>
<!ATTLIST MIRROR
xlink:type (locator) #FIXED "locator"
xlink:href CDATA #REQUIRED
xlink:label CDATA #REQUIRED
xlink:title CDATA #IMPLIED
>
<!ELEMENT xlink:arc EMPTY>
<!ATTLIST CONNECTION
xlink:type (arc) #FIXED "arc"
xlink:from CDATA #IMPLIED
xlink:to CDATA #IMPLIED
xlink:show (replace) "replace"
xlink:actuate (onRequest | onLoad) "onRequest"
>
Inline links, such as the familiar A element
from HTML, are themselves part of the source or target of the
link. The source of the link, that is the blue underlined text, is
included inside the A element that defines the link.
Most simple links are inline.
An out-of-line link does not contain any part of any of the resources it connects. Instead, the links are stored in a separate document called the linkbase.
Out of line links allow you to add links to and from documents that can't be modified such as a page on someone else's web site.
Out of line links allow you to add links to different parts of non-XML content.
Out of line links are not yet supported by software.
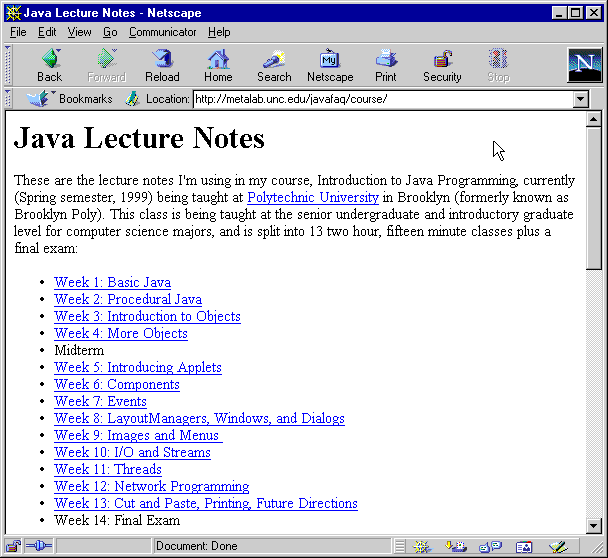
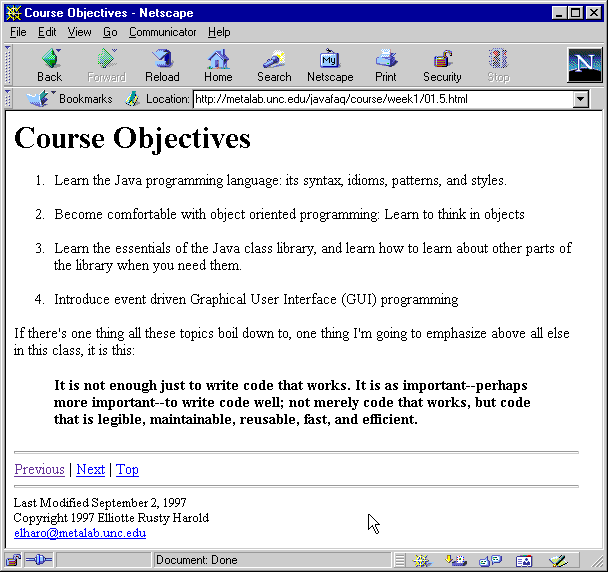
<COURSE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended">
<TOC xlink:type="locator"
xlink:href="http://www.ibiblio.org/javafaq/course/"
xlink:label="index"/>
<CLASS xlink:type="locator" xlink:label="class" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week1.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week2.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week3.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week4.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week5.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week6.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week7.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week8.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week9.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week10.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week11.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week12.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="http://www.ibiblio.org/javafaq/course/week13.xml"/>
<CONNECTION xlink:type="arc" from="index" to="class"/>
<CONNECTION xlink:type="arc" from="class" to="index"/>
</COURSE>
<COURSE xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:type="extended">
<CLASS xlink:type="locator" xlink:label="1"
xlink:href="http://www.ibiblio.org/javafaq/course/week1.xml"/>
<CLASS xlink:type="locator" xlink:label="2"
xlink:href="http://www.ibiblio.org/javafaq/course/week2.xml"/>
<CLASS xlink:type="locator" xlink:label="3"
xlink:href="http://www.ibiblio.org/javafaq/course/week3.xml"/>
<CLASS xlink:type="locator" xlink:label="4"
xlink:href="http://www.ibiblio.org/javafaq/course/week4.xml"/>
<CLASS xlink:type="locator" xlink:label="5"
xlink:href="http://www.ibiblio.org/javafaq/course/week5.xml"/>
<CLASS xlink:type="locator" xlink:label="6"
xlink:href="http://www.ibiblio.org/javafaq/course/week6.xml"/>
<CLASS xlink:type="locator" xlink:label="7"
xlink:href="http://www.ibiblio.org/javafaq/course/week7.xml"/>
<CLASS xlink:type="locator" xlink:label="8"
xlink:href="http://www.ibiblio.org/javafaq/course/week8.xml"/>
<CLASS xlink:type="locator" xlink:label="9"
xlink:href="http://www.ibiblio.org/javafaq/course/week9.xml"/>
<CLASS xlink:type="locator" xlink:label="10"
xlink:href="http://www.ibiblio.org/javafaq/course/week10.xml"/>
<CLASS xlink:type="locator" xlink:label="11"
xlink:href="http://www.ibiblio.org/javafaq/course/week11.xml"/>
<CLASS xlink:type="locator" xlink:label="12"
xlink:href="http://www.ibiblio.org/javafaq/course/week12.xml"/>
<CLASS xlink:type="locator" xlink:label="13"
xlink:href="http://www.ibiblio.org/javafaq/course/week13.xml"/>
<!-- Previous Links -->
<CONNECTION xlink:type="arc" xlink:from="2" xlink:to="1"/>
<CONNECTION xlink:type="arc" xlink:from="3" xlink:to="2"/>
<CONNECTION xlink:type="arc" xlink:from="4" xlink:to="3"/>
<CONNECTION xlink:type="arc" xlink:from="5" xlink:to="4"/>
<CONNECTION xlink:type="arc" xlink:from="6" xlink:to="5"/>
<CONNECTION xlink:type="arc" xlink:from="7" xlink:to="6"/>
<CONNECTION xlink:type="arc" xlink:from="8" xlink:to="7"/>
<CONNECTION xlink:type="arc" xlink:from="9" xlink:to="8"/>
<CONNECTION xlink:type="arc" xlink:from="10" xlink:to="9"/>
<CONNECTION xlink:type="arc" xlink:from="11" xlink:to="10"/>
<CONNECTION xlink:type="arc" xlink:from="12" xlink:to="11"/>
<CONNECTION xlink:type="arc" xlink:from="13" xlink:to="12"/>
<!-- Next Links -->
<CONNECTION xlink:type="arc" xlink:from="1" xlink:to="2"/>
<CONNECTION xlink:type="arc" xlink:from="2" xlink:to="3"/>
<CONNECTION xlink:type="arc" xlink:from="3" xlink:to="4"/>
<CONNECTION xlink:type="arc" xlink:from="4" xlink:to="5"/>
<CONNECTION xlink:type="arc" xlink:from="5" xlink:to="6"/>
<CONNECTION xlink:type="arc" xlink:from="6" xlink:to="7"/>
<CONNECTION xlink:type="arc" xlink:from="7" xlink:to="8"/>
<CONNECTION xlink:type="arc" xlink:from="8" xlink:to="9"/>
<CONNECTION xlink:type="arc" xlink:from="9" xlink:to="10"/>
<CONNECTION xlink:type="arc" xlink:from="10" xlink:to="11"/>
<CONNECTION xlink:type="arc" xlink:from="11" xlink:to="12"/>
<CONNECTION xlink:type="arc" xlink:from="12" xlink:to="13"/>
</COURSE>
A single XML document may contain multiple out-of-line extended links. However, the current XLink specification is relatively silent on exactly what the format of such a compound document should look like. About all it says is that such a document must be a well-formed XML document. An XLink processor would presumably read the entire document an extract any extended links that indicate connections to or from the current document.
A browser or other application that's reading the individual pages needs to be informed that there is a separate linkbase elsewhere that it should read and parse so that it can show the links to the user.
Ideally it would be handled through some external mechanism like HTTP headers.
The only currently defined way to do this
is to add an arc element inside the documents the out-of-line
link connects. This arc has an xlink:arcrole attribute with the value
http://www.w3.org/1999/xlink/properties/linkbase.
Its xlink:to attribute points to the linkbase.
<METADATA xlink:type="xlink:extended"
xmlns:xlink="http://www.w3.org/1999/xlink">
<LINKBASE xlink:type="arc"
xmlns:xlink="http://www.w3.org/1999/xlink"
xlink:arcrole="http://www.w3.org/1999/xlink/properties/linkbase"
xlink:to="courselinks"/>
<RESOURCE xlink:type="locator" href="courselinks.xml"
xlink:label="courselinks"/>
</METADATA>
XLinks can do everything HTML links can do and quite a bit more, but they aren't supported by current applications.
XLink elements of all types are placed in the
http://www.w3.org/1999/xlink namespace, normally with
the xlink prefix.
Simple links behave much like HTML links, but they are not
restricted to a single <A> tag.
Linking elements are identified by xlink:type
attributes.
Simple link elements are identified by
xlink:type attributes with the value simple.
Linking elements can describe the resource they're linking to
with xlink:title and xlink:role attributes.
Linking elements can use the xlink:show attribute to
tell the application how the content should be displayed when
the link is activated, for example, by opening a new window.
Linking elements can use the xlink:actuate attribute to
tell the application whether the link should be traversed
without a specific user request.
Extended link elements are identified by
xlink:type attributes with the value extended.
Extended links can contain multiple locators, resources, and arcs. Currently, it's left to the application to decide how to choose between different alternatives.
A resource element represents a local, inline
resource. It is identified by an xlink:type
attributes with the value resource.
A locator element represents a remote, out-of-line resource.
It is identified by an xlink:type
attribute with the value locator.
Both locator and resource elements can be labeled by
xlink:label attributes. These labels are
used to define arcs between resources.
A locator element has an
xlink:href attribute whose value is the URI of the
resource it locates.
Arc elements are identified by xlink:type
attributes with the value arc.
Arc elements have xlink:from and xlink:to
attributes of IDREF type that identify the
resources they connect by their labels.
Arc elements may have xlink:show and
xlink:actuate attributes to determine when and how
traversal of the link occurs.
An out-of-line link is a link that does not contain any local resources.
A linkbase is a document containing multiple out-of-line, extended link elements.
A linkbase is found when a document with an extended link with the role xlink:external-linkset is read.

This presentation: http://www.ibiblio.org/xml/slides/xmlone/amsterdam2001/hypertext/
XLink Specification: http://www.w3.org/TR/xlink/
Chapter 19 of the XML Bible, 2nd Edition: http://www.ibiblio.org/xml/books/bible2/chapters/ch19.html
Chapter 10 of XML in a Nutshell
The flaw is the conflation of name, location and identity but that flaw is the basic feature by which the WWW runs so we are stuck there. All the handwaving about URN/URI/URL doesn't avoid the simple fact that if one puts http:// anywhere in browser display space, the system colors it blue and puts up a finger.
The monkey expects a resource and when it doesn't get one, it shocks the monkey. Monkeys don't read specs to find out why they should be shocked. They turn red and put up a finger.
- -Claude L Bullard on the xml-dev mailing list
An XML application for pages at the end of a namespace URI.
Invented by Jonathan Borden, Tim Bray, and others on the xml-dev mailing list
A Resource Directory provides a text description of some class of resources and of other resources related to that class. It also contains a directory of links to these related resources.
An XML Namespace is one possible kind of resource. Related resources might include schemas, stylesheets, Java content handlers, browser plug-ins, and more.
The RDDL 1.0 DTD is an extension of XHTML Basic 1.0 using XHTML Modularization.
RDDL 1.0 DTD adds one new element to XHTML Basic 1.0: resource.
The resource element is in
the http://www.rddl.org/ namespace.
The rddl prefix is customary.
The rddl:resource element is a simple XLink;
that is, it has an xlink:type="simple" attrobite
The rddl:resource element
can be placed anywhere in HTML
where a p element may appear.
The rddl:resource can contain may of the XHTML Basic elements
(headings, paragraphs, lists, hyperlinks,
forms, tables, images, meeta information )
that the body element may contain.
The content of the
rddl:resource element should describe the associated resource.
Resource elements can contain other resource elements.
For the http://www.cafeconleche.org/baseball/ namespace:
<rddl:resource xlink:href="baseball.css"
xlink:role="http://www.rddl.org/arcrole.htm#CSS">
<div id="CSS" class="resource">
<h3>CSS Stylesheet</h3>
<p>A <a href="baseball.css">CSS stylesheet</a>
for baseball statistics documents.</p>
</div>
</rddl:resource>
<rddl:resource xlink:href="baseball.dtd"
xlink:role="http://www.rddl.org/arcrole.htm#DTD">
<div id="DTD" class="resource">
<h3>DTD</h3>
<p>A <a href="baseball.dtd">DTD</a> for ,
baseball statistics</p>
</div>
</rddl:resource>
<!DOCTYPE html PUBLIC "-//XML-DEV//DTD XHTML RDDL 1.0//EN"
"http://www.openhealth.org/RDDL/rddl-xhtml.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:rddl="http://www.rddl.org/">
<head>
<title>RDDL Resources for Baseball Statistics</title>
</head>
<body>
<h1>RDDL Resources for Baseball Statistics</h1>
<p>This is a sample RDDL document
used in Elliotte Rusty Harold's seminars
including</p>
<ul>
<li>XLinks and XPointers</li>
<li>Namespaces in XML</li>
</ul>
<p>It describes resources related to
the baseball statistics DTD developed in the XML
Bible and located at the namespace
<code>http://www.cafeconleche.org/baseball/</code>.</p>
<p>
<img src="../smallbiblecover.jpg" width="127" height='156'
alt="Cover of the XMl Bible"/>
</p>
<rddl:resource xlink:href="baseball.css"
xlink:role="http://www.rddl.org/arcrole.htm#CSS">
<div id="CSS" class="resource">
<h3>CSS Stylesheet</h3>
<p>A <a href="baseball.css">CSS stylesheet</a>
for baseball statistics documents.</p>
</div>
</rddl:resource>
<rddl:resource xlink:href="baseball.dtd"
xlink:role="http://www.rddl.org/arcrole.htm#DTD">
<div id="DTD" class="resource">
<h3>DTD</h3>
<p>A <a href="baseball.dtd">DTD</a> for ,
baseball statistics</p>
</div>
</rddl:resource>
<p>
Copyright 2001 <a href="http://www.macfaq.com/personal.html">Elliotte Rusty Harold</a><br class="empty"/>
<a href="mailto:elharo@metalab.unc.edu">elharo@metalab.unc.edu</a><br class="empty"/>
Last Modified Sunday, January 14, 2001
</p>
</body>
</html>View in BrowserContains a URI, possibly relative, pointing to the related resource
Identifies the type of the related resource with an absolute URI
Can be the namespace URI of the root element:
http://www.w3.org/2000/10/XMLSchemahttp://www.rddl.org/arcrole.htm#SOCAThttp://www.ascc.net/xml/schematronhttp://www.xml.gr.jp/xmlns/relaxCorehttp://www.w3.org/2000/01/rdf-schema#Can be a MIME type URI at http://www.isi.edu/in-notes/iana/assignments/media-types/
http://www.rddl.org/arcrole.htm#DTDhttp://www.isi.edu/in-notes/iana/assignments/media-types/application/pdfCan be a spec-defined URI:
http://www.rddl.org/arcrole.htm#DTDFor situations where the role alone isn't enough, this offers an additional URI
May contain a short, human readable description of the resource as plain, unmarked text.
Should not be used as a substitute for a more complete,
HTML-marked-up description of the related resource in the
contents of the rddl:resource element.
These two attributes are not used on
rddl:resource. They must
have the value none.
<!ELEMENT rddl:resource (#PCDATA | %Flow.mix;)*>
<!ATTLIST rddl:resource
id ID #IMPLIED
xlink:type (simple) #FIXED "simple"
xmlns:rddl CDATA #FIXED 'http://www.rddl.org/'
xml:lang NMTOKEN #IMPLIED
xlink:arcrole CDATA #IMPLIED
xlink:href CDATA #IMPLIED
xlink:role CDATA 'http://www.rddl.org/#resource'
xlink:title CDATA #IMPLIED
xlink:embed (none) #FIXED "none"
xlink:actuate (none) #FIXED "none"
>
The RDDL Specification: http://www.rddl.org/ (Written in RDDL)
The many advantages of descriptive pointing are crucial for a scalable, generic pointing system. Descriptive pointing is crucial for all the same reasons that descriptive markup is crucial to documents, and that making links first-class objects is crucial to linking. It is also clearly feasible, as shown by multiple implementations of the prior WDs from the XML WG, and of TEI extended pointers.--XML Linking Working Group, XML XPointer Requirements
Why Use XPointers?
XPointer Examples
A Concrete Example
Location Paths, Steps, and Sets
Axes
Node Tests
Predicates
Functions that Return Node Sets
Points
Ranges
Child Sequences
XPointer, the XML Pointer Language, defines an addressing scheme for individual parts of an XML document.
XLinks point to a URI (in practice, a URL) that specifies a particular resource.
The URI may include an XPointer part that more specifically identifies the desired part or element of the targeted resource or document.
XPointers use the same XPath syntax you're familiar with from XSL transformations to identify the parts of the document they point to, along with a few additional pieces.
The element with a given ID
All elements that possess a certain attribute
The first element of a certain type
The last element whose class attribute has the value pending.
The seventh element of a given type
The first child of the seventh element
and many more including combinations of these addresses...
xpointer(id("ebnf"))
xpointer(descendant::language[position()=2])
ebnf
xpointer(/child::spec/child::body/child::*/child::language[position()=2])
/1/14/2
xpointer(id("ebnf"))xpointer(id("EBNF"))
The XPointer does not specify the document. A URI does.
XPointers can be used as fragment identifiers
in a URI after a #
For example,
http://www.w3.org/TR/1998/REC-xml-19980210.xml#xpointer(id("ebnf"))
http://www.w3.org/TR/1998/REC-xml-19980210.xml#xpointer(descendant::language[position()=2])
http://www.w3.org/TR/1998/REC-xml-19980210.xml#ebnf
http://www.w3.org/TR/1998/REC-xml-19980210.xml#xpointer(/child::spec/child::body/child::*/child::language[position()=2])
http://www.w3.org/TR/1998/REC-xml-19980210.xml#/1/14/2
http://www.w3.org/TR/1998/REC-xml-19980210.xml#xpointer(id("ebnf"))xpointer(id("EBNF"))
<SPECIFICATION xmlns:xlink="http://www.w3.org/1999/xlink" xlink:type="simple"
xlink:href="http://www.w3.org/TR/1998/REC-xml-19980210.xml#xpointer(id('ebnf'))">
xlink:actuate="onRequest" xlink:show="replace">
Extensible Markup Language (XML) 1.0
</SPECIFICATION>
<?xml version="1.0"?>
<!DOCTYPE FAMILYTREE [
<!ELEMENT FAMILYTREE (PERSON | FAMILY)*>
<!-- PERSON elements -->
<!ELEMENT PERSON (NAME*, BORN*, DIED*, SPOUSE*)>
<!ATTLIST PERSON
ID ID #REQUIRED
FATHER CDATA #IMPLIED
MOTHER CDATA #IMPLIED
>
<!ELEMENT NAME (#PCDATA)>
<!ELEMENT BORN (#PCDATA)>
<!ELEMENT DIED (#PCDATA)>
<!ELEMENT SPOUSE EMPTY>
<!ATTLIST SPOUSE IDREF IDREF #REQUIRED>
<!--FAMILY-->
<!ELEMENT FAMILY (HUSBAND?, WIFE?, CHILD*) >
<!ATTLIST FAMILY ID ID #REQUIRED>
<!ELEMENT HUSBAND EMPTY>
<!ATTLIST HUSBAND IDREF IDREF #REQUIRED>
<!ELEMENT WIFE EMPTY>
<!ATTLIST WIFE IDREF IDREF #REQUIRED>
<!ELEMENT CHILD EMPTY>
<!ATTLIST CHILD IDREF IDREF #REQUIRED>
]>
<FAMILYTREE>
<PERSON ID="p1">
<NAME>Domeniquette Celeste Baudean</NAME>
<BORN>21 Apr 1836</BORN>
<DIED>Unknown</DIED>
<SPOUSE IDREF="p2"/>
</PERSON>
<PERSON ID="p2">
<NAME>Jean Francois Bellau</NAME>
<SPOUSE IDREF="p1"/>
</PERSON>
<PERSON ID="p3" FATHER="p2" MOTHER="p1">
<NAME>Elodie Bellau</NAME>
<BORN>11 Feb 1858</BORN>
<DIED>12 Apr 1898</DIED>
<SPOUSE IDREF="p4"/>
</PERSON>
<PERSON ID="p4" FATHER="p2" MOTHER="p1">
<NAME>John P. Muller</NAME>
<SPOUSE IDREF="p3"/>
</PERSON>
<PERSON ID="p7">
<NAME>Adolf Eno</NAME>
<SPOUSE IDREF="p6"/>
</PERSON>
<PERSON ID="p6" FATHER="p2" MOTHER="p1">
<NAME>Maria Bellau</NAME>
<SPOUSE IDREF="p7"/>
</PERSON>
<PERSON ID="p5" FATHER="p2" MOTHER="p1">
<NAME>Eugene Bellau</NAME>
</PERSON>
<PERSON ID="p8" FATHER="p2" MOTHER="p1">
<NAME>Louise Pauline Bellau</NAME>
<BORN>29 Oct 1868</BORN>
<DIED>3 May 1938</DIED>
<SPOUSE IDREF="p9"/>
</PERSON>
<PERSON ID="p9">
<NAME>Charles Walter Harold</NAME>
<BORN>about 1861</BORN>
<DIED>about 1938</DIED>
<SPOUSE IDREF="p8"/>
</PERSON>
<PERSON ID="p10" FATHER="p2" MOTHER="p1">
<NAME>Victor Joseph Bellau</NAME>
<SPOUSE IDREF="p11"/>
</PERSON>
<PERSON ID="p11">
<NAME>Ellen Gilmore</NAME>
<SPOUSE IDREF="p10"/>
</PERSON>
<PERSON ID="p12" FATHER="p2" MOTHER="p1">
<NAME>Honore Bellau</NAME>
</PERSON>
<FAMILY ID="f1">
<HUSBAND IDREF="p2"/>
<WIFE IDREF="p1"/>
<CHILD IDREF="p3"/>
<CHILD IDREF="p5"/>
<CHILD IDREF="p6"/>
<CHILD IDREF="p8"/>
<CHILD IDREF="p10"/>
<CHILD IDREF="p12"/>
</FAMILY>
<FAMILY ID="f2">
<HUSBAND IDREF="p7"/>
<WIFE IDREF="p6"/>
</FAMILY>
</FAMILYTREE>
Many (though not all) XPointers are location paths. These are the same location paths used by XSLT.
Location paths are built from location steps.
Each location step specifies a point in the targeted document, generally relative to some other well-known point such as the start of the document or another location step. This well-known point is called the context node.
A location step has three parts:
The axis
The node test
An optional predicate
axis::node-test[predicate]
child::PERSON[position()=2]
The axis tells you in what direction to search from the context node.
The node test tells you which nodes to consider along the axis.
The predicate is a boolean expression that tests each node in that set. If that expression returns false, then the node is removed from the set.
xpointer(/child::FAMILYTREE/child::PERSON[position()=3])
The location path of this XPointer is
/child::FAMILYTREE/child::PERSON[position()=3].
It is built from two location steps:
/child::FAMILYTREE
child::PERSON[position()=3]
It identifies the single node:
<PERSON ID="p3" FATHER="p2" MOTHER="p1">
<NAME>Elodie Bellau</NAME>
<BORN>11 Feb 1858</BORN>
<DIED>12 Apr 1898</DIED>
<SPOUSE IDREF="p4"/>
</PERSON>
xpointer(/child::FAMILYTREE/child::PERSON[position()>3])
Identifies all PERSON element nodes after Elodie Bellau
XPath defines twelve axes along which an XPointer may search for nodes
These depend on context to determine exactly what they point to.
For instance, consider this location path:
id("p6")/child::NAME
id() function that returns a
node set containing the element with the ID type attribute whose
value is p6. This provides a context node for the
following location step along the relative child
axis. Other axes include
ancestor
descendant
self
ancestor-or-self
descendant-or-self
attribute
Each selects nodes from a
particular subset of the nodes in the document. For instance,
the following axis selects from nodes that come
after the context node. The preceding axis selects
from nodes that come before the context node.
| Axis | Selects From |
ancestor |
the parent of the context node, the parent of the parent of the context node, the parent of the parent of the parent of the context node, and so forth back to the root node |
ancestor-or-self |
the ancestors of the context node and the context node itself |
attribute |
the attributes of the context node |
child |
the immediate children of the context node |
descendant |
the children of the context node, the children of the children of the context node, and so forth |
descendant-or-self |
the context node itself and its descendants |
following |
all nodes that start after the end of the context node, excluding attribute and namespace nodes |
following-sibling |
all nodes that start after the end of the context node and have the same parent as the context node |
parent |
the unique parent node of the context node |
preceding |
all nodes that end before the beginning of the context node, excluding attribute and namespace nodes |
preceding-sibling |
all nodes that start before the beginning of the context node and have the same parent as the context node |
self |
the context node |
There are ten node tests in XPointer, eight from XPath and two new ones:
name*prefix:*@namenode()text()comment()processing-instruction()point()range()A node test is attached to an axis to specify which nodes along the axis are chosen.
For example:
/descendant::body/child::*/attribute::xlink:*
Each location step can contain zero or more predicates that further restrict which nodes an XPointer points to. In most non-trivial cases a predicate is necessary to pick the one node from a node set that you want.
Each predicate contains a boolean
expression in square brackets ([]) that further
winnows the node set.
This allows an XPointer to select nodes according to many different criteria. For example, you can select:
All elements that have a specified attribute
All elements that have a specified attribute with a specified value
The first element that contains a specified child element
An element whose text content includes a specified string
All elements that are not the first or last children of their parents
All elements whose value is a number
All elements whose value is a number greater than 100
XPath predicate expressions are ultimately converted to a boolean after all calculations are finished. Non-boolean results are converted as follows:
A number is true if it's equal to the position of the context node, false otherwise.
An empty node set is false; all other node sets are true.
A zero length string is false; all other strings are true (including the string "false")
The predicate expression is evaluated for each node in the context node list. Each node for which the expression ultimately evaluates to false is removed from the list. Thus only those nodes that satisfy the predicate remain.
Probably the function most frequently used in XPointer
predicates is position(). This returns the index of
the node in the context node list. This allows you to find the
first, second, third, or other indexed node.
You can compare
positions using the various relational operators like
<, >, =,
!=, >=, and <=.
xpointer(/child::FAMILYTREE/child::*[position()=1])
xpointer(/child::FAMILYTREE/child::*[position()=2])
xpointer(/child::FAMILYTREE/child::*[position()=3])
xpointer(/child::FAMILYTREE/child::*[position()=4])
xpointer(/child::FAMILYTREE/child::*[position()=5])
xpointer(/child::FAMILYTREE/child::*[position()=6])
xpointer(/child::FAMILYTREE/child::*[position()=7])
xpointer(/child::FAMILYTREE/child::*[position()=8])
xpointer(/child::FAMILYTREE/child::*[position()=9])
xpointer(/child::FAMILYTREE/child::*[position()=10])
xpointer(/child::FAMILYTREE/child::*[position()=11])
xpointer(/child::FAMILYTREE/child::*[position()=12])
xpointer(/child::FAMILYTREE/child::*[position()=13])
xpointer(/child::FAMILYTREE/child::*[position()=14])
xpointer(/child::FAMILYTREE/child::*[1])
xpointer(/child::FAMILYTREE/child::*[2])
xpointer(/child::FAMILYTREE/child::*[3])
xpointer(/child::FAMILYTREE/child::*[4])
xpointer(/child::FAMILYTREE/child::*[5])
xpointer(/child::FAMILYTREE/child::*[6])
xpointer(/child::FAMILYTREE/child::*[7])
xpointer(/child::FAMILYTREE/child::*[8])
xpointer(/child::FAMILYTREE/child::*[9])
xpointer(/child::FAMILYTREE/child::*[10])
xpointer(/child::FAMILYTREE/child::*[11])
xpointer(/child::FAMILYTREE/child::*[12])
xpointer(/child::FAMILYTREE/child::*[13])
xpointer(/child::FAMILYTREE/child::*[14])
id()
here()
origin()
The last two, here() and origin()
are XPointer extensions to XPath that are not available in XSLT.
The id() function
selects the element in the
document that has an ID type attribute with a specified value.
For example, consider the URI http://www.theharolds.com/genealogy.xml#xpointer(id("p12")). If you look back at Listing 17-1, you find this element:
<PERSON ID="p12" FATHER="p2" MOTHER="p1">
<NAME>Honore Bellau</NAME>
</PERSON>
Since ID pointers are so common and so useful, there's also
a shortcut for this. If all you want to do is point to a
particular element with a particular ID, you can skip all the
xpointer(id("")) fru-fru and just use the
bare ID after the #
like this:
http://www.theharolds.com/genealogy.xml#p12
Consider a simple slide show. In this example,
here()/following::SLIDE[1] refers to the next slide in the
show. here()/preceding::SLIDE[1] refers to the previous slide
in the show. Presumably this would be used in conjunction with a
style sheet that showed one slide at a time.
<?xml version="1.0"?>
<SLIDESHOW xmlns:xlink="http://www.w3.org/1999/xlink">
<SLIDE>
<H1>Welcome to the slide show!</H1>
<BUTTON xlink:type="simple"
xlink:href="here()/following::SLIDE[1]">
Next
</BUTTON>
</SLIDE>
<SLIDE>
<H1>This is the second slide</H1>
<BUTTON xlink:type="simple"
xlink:href="here()/preceding::SLIDE[1]">
Previous
</BUTTON>
<BUTTON xlink:type="simple"
xlink:href="here()/following::SLIDE[1]">
Next
</BUTTON>
</SLIDE>
<SLIDE>
<H1>This is the second slide</H1>
<BUTTON xlink:type="simple"
xlink:href="here()/preceding::SLIDE[1]">
Previous
</BUTTON>
<BUTTON xlink:type="simple"
xlink:href="here()/following::SLIDE[1]">
Next
</BUTTON>
</SLIDE>
<SLIDE>
<H1>This is the third slide</H1>
<BUTTON xlink:type="simple"
xlink:href="here()/preceding::SLIDE[1]">
Previous
</BUTTON>
<BUTTON xlink:type="simple"
xlink:href="here()/following::SLIDE[1]">
Next
</BUTTON>
</SLIDE>
...
<SLIDE>
<H1>This is the last slide</H1>
<BUTTON xlink:type="simple"
xlink:href="here()/preceding::SLIDE[1]">
Previous
</BUTTON>
</SLIDE>
</SLIDESHOW>
Generally, the here() location term is only used in fully
relative URIs in XLinks. If any URI part is included, it must be
the same as the URI of the current document.
The origin() function is much the same as here();
that is, it refers to the source of a link. However,
origin() is used in out-of-line links where the
link is not actually present in the source document. It points to the
element in the source document from which the user activated the link.
Every point is either between two nodes or between two characters in the parsed character data of a document. To make sense of this you have to remember that parsed character data is part of a text node. For instance, consider this very simple but well-formed XML document:
<GREETING>
Hello
</GREETING>
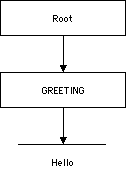
There are exactly three nodes and 13 distinct points in this document. In order the points are:
The point before the root node
The point before the GREETING element node
The point before the text node containing the text "Hello" (as well as assorted white space)
The point before the white space between <GREETING> and Hello.
The point before the first H in Hello
The point between the H and the e in Hello
The point between the e and the l in Hello
The point between the l and the l in Hello
The point between the l and the o in Hello
The point after the o in Hello
The point after the white space between Hello and </GREETING>.
The point after the GREETING element.
The point after the root node.
The exact details of the white space in the document are not considered here. XPointer collapses all runs of white space to a single space.
In some applications it may be important to specify a range across a document rather than a particular point in the document. For instance, the selection a user makes with a mouse is not necessarily going to match up with any one element or node. It may start in the middle of one paragraph, extend across a heading and a picture and then into the middle of another paragraph two pages down. Any such contiguous area of a document can be described with a range.
A range begins at one point and continues until another point.
The start- and end-points of the range are identified by location paths.
The first point in the location set the start path identifies is the start-point.
The last point in the location set the end path identifies is the end-point of the range.
To specify a range, you append
/range-to(end-point)
to a location path specifying the start-point of the range.
The parentheses contain a location path specifying the end-point of the range.
For example, suppose you want to select everything
between the first PERSON element and the last
PERSON element
xpointer(/child::PERSON[position() = 1]/range-to(/child::PERSON[position() = last()]))
range(location-set) The range is the minimum range necessary to cover the entire location.
range-inside(location-set) Returns a location set containing the interiors of each of the locations in the input.
start-point(location-set) Returns a location set that contains
one point representing the first point of each location in
the input location set.
For example,
start-point(//PERSON[1])
Returns the point immediately before the first PERSON element.
start-point(//PERSON)
returns the set of points immediately before each PERSON element.
end-point(location-set) The same as start-point() except that it returns the
points immediately after each location in its input.
string-range(node-set,substring,index,length)
A string range points to an occurrence of a specified string, or a substring of a given string in the text (not markup) of the document.
string-range()
takes as arguments a node set to search and a substring to
search for.
string-range() returns a node set containing one range for each
non-overlapping match to the string.
By default, the range returned starts before the first matched character and encompasses all the matched characters.
You can also provide optional index and length arguments indicating how many characters after the match the range should start and how many characters after the start the range should continue.
For example, this XPointer finds all occurrences of the string "Harold":
xpointer(string-range(/,"Harold"))
You can change the first argument to specify what nodes you want
to look in. For example, this XPointer finds all occurrences of
the string "Harold" in NAME elements:
xpointer(string-range(//NAME,"Harold"))
String ranges may have node tests. Thus this XPointer finds only the first occurrence of the string "Harold" in the document:
xpointer(string-range(/,"Harold")[position()=1])
This targets the position immediately preceding the word Harold
in Charles Walter Harold's NAME element. This is not
the same as pointing at the entire NAME element as an
element-based selector would do.
A third numeric argument targets a particular position in the string. For example, this targets the point immediately following the first occurrence of the string "Harold" because Harold has six letters:
xpointer(string-range(/,"Harold",6)[position()=1])
An optional fourth argument specifies the number of characters to select. For example, this URI selects the "old" from the first occurrence of the entire string "Harold":
xpointer(string-range(/,"Harold",4,3)[position()=1])
When matching strings, case is considered. All white space is condensed to a single space. Markup characters are ignored.
Normally, the only way to get a point location is by getting
a range first and using the
start-point() or end-point() functions
For example, to
select the point immediately before the D in Domeniquette
Celeste Baudean's NAME element,
start-point(range-inside(/child::FAMILYTREE/descendant::*[position()=1]/child::NAME/))
XPointers may appear in non-XML documents where namespace prefixes are not defined.
You use an xmlns() scheme to
map a prefix to a URI. For example,
xmlns(svg=http://www.w3.org/2000/svg) xpointer(//svg:polygon[3])
A child sequence is a shortcut for XPointers that consist of nothing but a series of child relative location steps counting down from the root node, each of which selects a particular child by position only.
The shortcut is to use only the position number and the slashes that separate individual elements from each other, like this:
http://www.theharolds.com/genealogy.xml#/1/4
/1/4 is a child sequence that says to select the
fourth child element of the first child element of the root.
Child sequences may include an initial ID. In that case the
counting begins from the element with that ID rather than from
the root. For example, John P. Muller's PERSON element has an ID
attribute with the value p4. Consequently the XPointer p4/1
points to his NAME element and p4/2 points to his SPOUSE
element.
Each child sequence always points to a single element. You cannot use child sequences with any other relative location steps. You cannot use them to select elements of a particular type. You cannot use them to select attribute or strings. You can only use them to select a single element by its relative location in the tree.
XPointers refer to particular parts of or locations in XML documents.
The syntax of an XPointer is the keyword xpointer, followed
by parentheses containing an XPath expression that returns a
node set.
The id() function points to an element with a
specified value for an ID type attribute.
Location steps can be chained to make more sophisticated location paths.
Each location step contains an axis, a node test, and zero or more predicates.
Relative location steps select nodes in a document based on their relationship to a context node.
The self axis points to the context node. It
can be abbreviated as a period (.).
The parent axis points to the node that
contains the context node. It can be abbreviated as a double
period (..).
The child axis points to immediate children of
the context node. It can be abbreviated simply by a node test.
The descendant axis points to all elements
contained in the context node. It can be abbreviated as a double
slash (//).
The descendant-or-self axis points to all
elements contained in the context node as well as the context
node itself.
The ancestor axis points to an element that
contains the context node.
The ancestor-or-self axis points to all
elements that contain the context node as well as the context
node itself.
The preceding axis points to any element that
comes before the context node.
The following axis points to any element
following the context node.
The preceding-sibling axis selects from sibling
elements that precede the context node.
The following-sibling axis selects from sibling
elements that follow the context node.
The attribute axis points to an attribute of the context
node. It can be abbreviated as a @ sign.
The node test of a relative location step is normally an
element name, but may also be * to
select all elements, @* to
select all attributes, @name
to select all attributes with the given name,
prefix:* to select all
elements in the specified namespace,
or one of the keywords
comment(), text(),
processing-instruction(), node(),
point() or range().
The optional predicate of a relative location step is an XPath boolean expression enclosed in square brackets that further narrows down the node set the XPointer refers to.
A point indicates a position preceding or following a node or a character.
A range identifies the parsed character data between two points.
The string-range() function points to a
specified block of text.
A child sequence points to an element by counting children from the root.

This presentation: http://www.ibiblio.org/xml/slides/xmlone/amsterdam2001/hypertext
XPointer Specification: http://www.w3.org/TR/xptr
Chapter 20 of the XML Bible, 2nd edition: http://www.ibiblio.org/xml/books/bible2/chapters/ch20.html
Chapter 10 of XML in a Nutshell
An inband means of specifying the proper URI for a document that can succeed even if out-of-band mechanisms aren't available.
A means of specifying the proper base URI which relative URLs are relative to, even if the document itself is copied to a different location.
An XML replacement for the HTML BASE element
<slide xml:base="http://www.ibiblio.org/xml/slides/xmlone/amsterdam2001/hypertext/">
<title>The xml:base attribute</title>
...
<previous xlink:type="simple" xlink:href="What_Is_XBase.xml"/>
<next xlink:type="simple" xlink:href="xbaseexample.xml"/>
</slide>
May be attached to any element to set the base URI for that element and its descendants
The xml prefix is automatically bound
to the http://www.w3.org/XML/1998/namespace URI
The value should be an absolute URI
<COURSE xmlns:xlink="http://www.w3.org/1999/xlink"
xml:base="http://www.ibiblio.org/javafaq/course/"
xlink:type="extended">
<TOC xlink:type="locator" xlink:href="index.html" xlink:label="index"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week1.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week2.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week3.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week4.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week5.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week6.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week7.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week8.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week9.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week10.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week11.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week12.xml"/>
<CLASS xlink:type="locator" xlink:label="class"
xlink:href="week13.xml"/>
<CONNECTION xlink:type="arc" from="index" to="class"/>
<CONNECTION xlink:type="arc" from="class" to="index"/>
</COURSE>
"index.html" now resolves to the URI "http://www.ibiblio.org/javafaq/course/index.html"
"week1.xml" resolves to the URI "http://www.ibiblio.org/javafaq/course/week1.xml"
"week2.xml" resolves to the URI "http://www.ibiblio.org/javafaq/course/week2.xml"
"week3.xml" resolves to the URI "http://www.ibiblio.org/javafaq/course/week3.xml"
etc.
How does it interact with XHTML? in particular,
the XHTML base
element?
Browser and other application support?
XML Base Specification: http://www.w3.org/TR/xmlbase
The problem is that we're not providing the tools. We're providing the specs. That's a whole different ball game. If tools existed for actually making really interesting use of RDF and XLink and XInclude then people would use them. If IE and/or Mozilla supported the full gamut of specs, from XSLT 1.0 to XLink and XInclude (OK, so they're not quite REC's, but with time...) then you would find people using them more.--Matt Sergeant on the xml-dev mailing list
A means of including one XML document inside another, irrespective of validation.
Based on the XML Infoset; a source infoset is transformed into a result infoset
xlink:show="embed" only graphically includes,
like the IMG element in HTML.
It does not merge infosets.
External parsed entities:
Require a DTD
Can only handle very limited documents; i.e. not all well-formed XML documents are well-formed external parsed entities. In particular XML declarations can be and document type declarations are a problem.
Doesn't allow unparsed text inserted as CDATA
XSLT document() function
Only handles XSLT
No unparsed, pure-text includes
Server side includes:
HTML only
Server dependent
Custom code or XSLT extension functions
href attribute identifies the document (or part thereof)
to be included
In the http://www.w3.org/2001/XInclude
namespace.
The prefixes xinclude or xi
are customary.
<book xmlns:xinclude="http://www.w3.org/2001/XInclude">
<title>Processing XML with Java</title>
<chapter><xinclude:include href="dom.xml"/></chapter>
<chapter><xinclude:include href="sax.xml"/></chapter>
<chapter><xinclude:include href="jdom.xml"/></chapter>
</book>
parse="xml"parse="text"< will change to < and so forth.
<slide xmlns:xinclude="http://www.w3.org/2001/XInclude">
<title>The href attribute</title>
<ul>
<li>Identifies the document to be included with a URI</li>
<li>The document at the URI replaces the <code>include</code>
element in the including document</li>
<li>The <code>xinclude</code> prefix is bound to the http://www.w3.org/2001/XInclude
namespace URI.
</li>
</ul>
<pre><code><xinclude:include parse="text" href="processing_xml_with_java.xml"/>
</code></pre>
<description>
A slide from Elliotte Rusty Harold's XML Hypertext seminar at
<host_ref/>, <date_ref/>
</description>
<last_modified>October 26, 2000</last_modified>
</slide>
Used when parse="text"
Value is the name of the text file's character encoding, as in the encoding declaration in the XML declaration
e.g. ISO-8859-1, UTF-8, UTF-16, MacRoman, etc.
<slide xmlns:xinclude="http://www.w3.org/2001/XInclude">
<title>The href attribute</title>
<ul>
<li>Identifies the document to be included with a URI</li>
<li>The document at the URI replaces the <code>include</code>
element in the including document</li>
<li>The <code>xinclude</code> prefix is bound to the http://www.w3.org/2001/XInclude
namespace URI.
</li>
</ul>
<pre><code><xinclude:include parse="text" encoding="ISO-8859-1"
href="processing_xml_with_java.xml"/>
</code></pre>
<description>
A slide from Elliotte Rusty Harold's XML Hypertext seminar at
<host_ref/>, <date_ref/>
</description>
<last_modified>October 26, 2000</last_modified>
</slide>
/*--
Copyright 2001 Elliotte Rusty Harold.
All rights reserved.
I haven't yet decided on a license.
It will be some form of open source.
THIS SOFTWARE IS PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED
WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL ELLIOTTE RUSTY HAROLD OR ANY
OTHER CONTRIBUTORS TO THIS PACKAGE
BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF
USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT
OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
SUCH DAMAGE.
*/
package com.macfaq.xml;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.Locator;
import org.xml.sax.helpers.XMLReaderFactory;
import org.xml.sax.helpers.XMLFilterImpl;
import org.xml.sax.helpers.NamespaceSupport;
import java.net.URL;
import java.net.URLConnection;
import java.net.MalformedURLException;
import java.io.UnsupportedEncodingException;
import java.io.IOException;
import java.io.InputStream;
import java.io.BufferedInputStream;
import java.io.InputStreamReader;
import java.util.Stack;
/**
* <p>
* This is a SAX filter which resolves all XInclude include elements
* before passing them on to the client application. Currently this
* class has the following known deviation from the XInclude specification:
* </p>
* <ol>
* <li>XPointer is not supported.</li>
* </ol>
*
* <p>
* Furthermore, I would definitely use a new instance of this class
* for each document you want to process. I doubt it can be used
* successfully on multiple documents. Furthermore, I can virtually
* guarantee that this class is not thread safe. You have been
* warned.
* </p>
*
* <p>
* Since this class is not designed to be subclassed, and since
* I have not yet considered how that might affect the methods
* herein or what other protected methods might be needed to support
* subclasses, I have declared this class final. I may remove this
* restriction later, though the use-case for subclassing is weak.
* This class is designed to have its functionality extended via a
* a horizontal chain of filters, not a
* vertical hierarchy of sub and superclasses.
* </p>
*
* <p>
* To use this class:
* </p>
* <ol>
* <li>Construct an <code>XIncludeFilter</code> object with a known base URL</li>
* <li>Pass the <code>XMLReader</code> object from which the raw document will
* be read to the <code>setParent()</code> method of this object. </li>
* <li>Pass your own <code>ContentHandler</code> object to the
* <code>setContentHandler()</code> method of this object. This is the
* object which will receive events from the parsed and included
* document.
* </li>
* <li>Optional: if you wish to receive comments, set your own
* <code>LexicalHandler</code> object as the value of this object's
* http://xml.org/sax/properties/lexical-handler property.
* Also make sure your <code>LexicalHandler</code> asks this object
* for the status of each comment using <code>insideIncludeElement</code>
* before doing anything with the comment.
* </li>
* <li>Pass the URL of the document to read to this object's
* <code>parse()</code> method</li>
* </ol>
*
* <p> e.g.</p>
* <pre><code>XIncludeFilter includer = new XIncludeFilter(base);
* includer.setParent(parser);
* includer.setContentHandler(new SAXXIncluder(System.out));
* includer.parse(args[i]);</code>
* </pre>
* </p>
*
* @author Elliotte Rusty Harold
* @version 1.0d8
*/
public final class XIncludeFilter extends XMLFilterImpl {
public final static String XINCLUDE_NAMESPACE
= "http://www.w3.org/2001/XInclude";
private Stack bases = new Stack();
private Stack locators = new Stack();
// what if this isn't called????
// do I need to check this in startDocument() and push something
// there????
public void setDocumentLocator(Locator locator) {
locators.push(locator);
String base = locator.getSystemId();
try {
bases.push(new URL(base));
}
catch (MalformedURLException e) {
throw new UnsupportedOperationException("Unrecognized SYSTEM ID: " + base);
}
super.setDocumentLocator(locator);
}
// necessary to throw away contents of non-empty XInclude elements
private int level = 0;
/**
* <p>
* This utility method returns true if and only if this reader is
* currently inside a non-empty include element. (This is <strong>
* not</strong> the same as being inside the node set whihc replaces
* the include element.) This is primarily needed for comments
* inside include elements. It must be checked by the actual
* LexicalHandler to see whether a comment is passed or not.
* </p>
*
* @return boolean
*/
public boolean insideIncludeElement() {
return level != 0;
}
public void startElement(String uri, String localName,
String qName, Attributes atts) throws SAXException {
if (level == 0) { // We're not inside an xi:include element
// Adjust bases stack by pushing either the new
// value of xml:base or the base of the parent
String base = atts.getValue(NamespaceSupport.XMLNS, "base");
URL parentBase = (URL) bases.peek();
URL currentBase = parentBase;
if (base != null) {
try {
currentBase = new URL(parentBase, base);
}
catch (MalformedURLException e) {
throw new SAXException("Malformed base URL: "
+ currentBase, e);
}
}
bases.push(currentBase);
if (uri.equals(XINCLUDE_NAMESPACE) && localName.equals("include")) {
// include external document
String href = atts.getValue("href");
// Verify that there is an href attribute
if (href==null) {
throw new SAXException("Missing href attribute");
}
String parse = atts.getValue("parse");
if (parse == null) parse = "xml";
if (parse.equals("text")) {
String encoding = atts.getValue("encoding");
includeTextDocument(href, encoding);
}
else if (parse.equals("xml")) {
includeXMLDocument(href);
}
// Need to check this also in DOM and JDOM????
else {
throw new SAXException(
"Illegal value for parse attribute: " + parse);
}
level++;
}
else {
super.startElement(uri, localName, qName, atts);
}
}
}
public void endElement (String uri, String localName, String qName)
throws SAXException {
if (uri.equals(XINCLUDE_NAMESPACE)
&& localName.equals("include")) {
level--;
}
else if (level == 0) {
bases.pop();
super.endElement(uri, localName, qName);
}
}
private int depth = 0;
public void startDocument() throws SAXException {
level = 0;
if (depth == 0) super.startDocument();
depth++;
}
public void endDocument() throws SAXException {
locators.pop();
depth--;
if (depth == 0) super.endDocument();
}
// how do prefix mappings move across documents????
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
if (level == 0) super.startPrefixMapping(prefix, uri);
}
public void endPrefixMapping(String prefix)
throws SAXException {
if (level == 0) super.endPrefixMapping(prefix);
}
public void characters(char[] ch, int start, int length)
throws SAXException {
if (level == 0) super.characters(ch, start, length);
}
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
if (level == 0) super.ignorableWhitespace(ch, start, length);
}
public void processingInstruction(String target, String data)
throws SAXException {
if (level == 0) super.processingInstruction(target, data);
}
public void skippedEntity(String name) throws SAXException {
if (level == 0) super.skippedEntity(name);
}
// convenience method for error messages
private String getLocation() {
String locationString = "";
Locator locator = (Locator) locators.peek();
String publicID = "";
String systemID = "";
int column = -1;
int line = -1;
if (locator != null) {
publicID = locator.getPublicId();
systemID = locator.getSystemId();
line = locator.getLineNumber();
column = locator.getColumnNumber();
}
locationString = " in document included from " + publicID
+ " at " + systemID
+ " at line " + line + ", column " + column;
return locationString;
}
/**
* <p>
* This utility method reads a document at a specified URL
* and fires off calls to <code>characters()</code>.
* It's used to include files with <code>parse="text"</code>
* </p>
*
* @param url URL of the document that will be read
* @param encoding Encoding of the document; e.g. UTF-8,
* ISO-8859-1, etc.
* @return void
* @throws SAXException if the requested document cannot
be downloaded from the specified URL
or if the encoding is not recognized
*/
private void includeTextDocument(String url, String encoding)
throws SAXException {
if (encoding == null || encoding.trim().equals("")) encoding = "UTF-8";
URL source;
try {
URL base = (URL) bases.peek();
source = new URL(base, url);
}
catch (MalformedURLException e) {
UnavailableResourceException ex =
new UnavailableResourceException("Unresolvable URL " + url
+ getLocation());
ex.setRootCause(e);
throw new SAXException("Unresolvable URL " + url + getLocation(), ex);
}
try {
URLConnection uc = source.openConnection();
InputStream in = new BufferedInputStream(uc.getInputStream());
String encodingFromHeader = uc.getContentEncoding();
String contentType = uc.getContentType();
if (encodingFromHeader != null) encoding = encodingFromHeader;
else {
// What if file does not have a MIME type but name ends in .xml????
// MIME types are case-insensitive
// Java may be picking this up from file URL
if (contentType != null) {
contentType = contentType.toLowerCase();
if (contentType.equals("text/xml")
|| contentType.equals("application/xml")
|| (contentType.startsWith("text/") && contentType.endsWith("+xml") )
|| (contentType.startsWith("application/") && contentType.endsWith("+xml"))) {
encoding = EncodingHeuristics.readEncodingFromStream(in);
}
}
}
InputStreamReader reader = new InputStreamReader(in, encoding);
char[] c = new char[1024];
while (true) {
int charsRead = reader.read(c, 0, 1024);
if (charsRead == -1) break;
if (charsRead > 0) this.characters(c, 0, charsRead);
}
}
catch (UnsupportedEncodingException e) {
throw new SAXException("Unsupported encoding: "
+ encoding + getLocation(), e);
}
catch (IOException e) {
throw new SAXException("Document not found: "
+ source.toExternalForm() + getLocation(), e);
}
}
/**
* <p>
* This utility method reads a document at a specified URL
* and fires off calls to various <code>ContentHandler</code> methods.
* It's used to include files with <code>parse="xml"</code>
* </p>
*
* @param url URL of the document that will be read
* @return void
* @throws SAXException if the requested document cannot
be downloaded from the specified URL.
*/
private void includeXMLDocument(String url)
throws SAXException {
URL source;
try {
URL base = (URL) bases.peek();
source = new URL(base, url);
}
catch (MalformedURLException e) {
UnavailableResourceException ex =
new UnavailableResourceException("Unresolvable URL " + url
+ getLocation());
ex.setRootCause(e);
throw new SAXException("Unresolvable URL " + url + getLocation(), ex);
}
try {
// make this more robust
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
}
catch (SAXException e2) {
System.err.println("Could not find an XML parser");
return;
}
}
parser.setContentHandler(this);
// save old level and base
int previousLevel = level;
this.level = 0;
if (bases.contains(source)) {
Exception e = new CircularIncludeException(
"Circular XInclude Reference to " + source + getLocation()
);
throw new SAXException("Circular XInclude Reference", e);
}
bases.push(source);
parser.parse(source.toExternalForm());
// restore old level and base
this.level = previousLevel;
bases.pop();
}
catch (IOException e) {
throw new SAXException("Document not found: "
+ source.toExternalForm() + getLocation(), e);
}
}
}
/*--
Copyright 2001 Elliotte Rusty Harold.
All rights reserved.
I haven't yet decided on a license.
It will be some form of open source.
THIS SOFTWARE IS PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED
WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL ELLIOTTE RUSTY HAROLD OR ANY
OTHER CONTRIBUTORS TO THIS PACKAGE
BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF
USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT
OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
SUCH DAMAGE.
*/
package com.macfaq.xml;
import org.xml.sax.SAXException;
import org.xml.sax.ContentHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import org.xml.sax.XMLReader;
import org.xml.sax.Locator;
import org.xml.sax.Attributes;
import org.xml.sax.ext.LexicalHandler;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.io.OutputStream;
import java.io.Writer;
import java.io.OutputStreamWriter;
import java.io.File;
import java.net.URL;
import java.net.MalformedURLException;
import java.util.Stack;
/**
* <p><code>SAXXIncluder</code> is a simple <code>ContentHandler</code> that
* writes its XML document onto an output stream after resolving
* all <code>xinclude:include</code> elements.
* </p>
*
* <p>
* The only current known bug is that the notation and
* unparsed entity information items are not included
* in the result infoset. Furthermore, processing
* instructions in the DTD are not included. Note that this is
* only relevant to the source infoset. The DOCTYPE declaration
* is specifically excluded from included infosets.
* </p>
*
* <p>
* I also need to check how section 4.4.3.1 applies for inscope
* namespaces in included documents. Currently this is not an issue
* because I only include full documents, but it may become an
* an issue when XPointer support is added.
* </p>
*
* <p>
* There's no XPointer support yet. Only full documents are
* included.
* </p>
*
* <p>
* The parser used to drive this must support the <code>LexicalHandler</code>
* interface. It must also provide a <code>Locator</code> object.
* These are optional in SAX, but Xerces-J does support these features.
* </p>
*
* @author Elliotte Rusty Harold
* @version 1.0d8
*/
public class SAXXIncluder implements ContentHandler, LexicalHandler {
private Writer out;
private String encoding;
// should try to combine two constructors so as not to duplicate
// code
public SAXXIncluder(OutputStream out, String encoding)
throws UnsupportedEncodingException {
this.out = new OutputStreamWriter(out, encoding);
this.encoding = encoding;
}
public SAXXIncluder(OutputStream out) {
try {
this.out = new OutputStreamWriter(out, "UTF8");
this.encoding="UTF-8";
}
catch (UnsupportedEncodingException e) {
// This really shouldn't happen
}
}
public void setDocumentLocator(Locator locator) {}
public void startDocument() throws SAXException {
try {
out.write("<?xml version='1.0' encoding='"
+ encoding + "'?>\r\n");
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
public void endDocument() throws SAXException {
try {
out.flush();
}
catch (IOException e) {
throw new SAXException("Flush failed", e);
}
}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
}
public void endPrefixMapping(String prefix)
throws SAXException {
}
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts)
throws SAXException {
try {
out.write("<" + qualifiedName);
for (int i = 0; i < atts.getLength(); i++) {
out.write(" ");
out.write(atts.getQName(i));
out.write("='");
String value = atts.getValue(i);
// + 4 allows space for one entitiy reference.
// If there's more than that, then the StringBuffer
// will automatically expand
// Need to use character references if the encoding
// can't support the character
StringBuffer encodedValue=new StringBuffer(value.length() + 4);
for (int j = 0; j < value.length(); j++) {
char c = value.charAt(j);
if (c == '&') encodedValue.append("&");
else if (c == '<') encodedValue.append("<");
else if (c == '>') encodedValue.append(">");
else if (c == '\'') encodedValue.append("'");
else encodedValue.append(c);
}
out.write(encodedValue.toString());
out.write("'");
}
out.write(">");
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
try {
out.write("</" + qualifiedName + ">");
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
// need to escape characters that are not in the given
// encoding using character references????
// need to escape characters that are not in the given
// encoding using character references????
public void characters(char[] ch, int start, int length)
throws SAXException {
try {
for (int i = 0; i < length; i++) {
char c = ch[start+i];
if (c == '&') out.write("&");
else if (c == '<') out.write("<");
else out.write(c);
}
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
this.characters(ch, start, length);
}
// do I need to escape text in PI????
public void processingInstruction(String target, String data)
throws SAXException {
try {
out.write("<?" + target + " " + data + "?>");
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
public void skippedEntity(String name) throws SAXException {
try {
out.write("&" + name + ";");
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
// LexicalHandler methods
private boolean inDTD = false;
private Stack entities = new Stack();
public void startDTD(String name, String publicId, String systemId)
throws SAXException {
inDTD = true;
// if this is the source document, output a DOCTYPE declaration
if (entities.size() == 0) {
String id;
if (publicId != null) id = "PUBLIC \"" + publicId + "\" \"" + systemId + '"';
else id = "SYSTEM \"" + systemId + '"';
try {
out.write("<!DOCTYPE " + name + " " + id + ">\r\n");
}
catch (IOException e) {
throw new SAXException("Error while writing DOCTYPE", e);
}
}
}
public void endDTD() throws SAXException { }
public void startEntity(String name) throws SAXException {
entities.push(name);
}
public void endEntity(String name) throws SAXException {
entities.pop();
}
public void startCDATA() throws SAXException {}
public void endCDATA() throws SAXException {}
// Just need this reference so we can ask if a comment is
// inside an include element or not
private XIncludeFilter filter = null;
public void setFilter(XIncludeFilter filter) {
this.filter = filter;
}
public void comment(char[] ch, int start, int length)
throws SAXException {
if (!inDTD && !filter.insideIncludeElement()) {
try {
out.write("<!--");
out.write(ch, start, length);
out.write("-->");
}
catch (IOException e) {
throw new SAXException("Write failed", e);
}
}
}
/**
* <p>
* The driver method for the SAXXIncluder program.
* </p>
*
* @param args contains the URLs and/or filenames
* of the documents to be procesed.
*/
public static void main(String[] args) {
// make this more robust
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e2) {
System.err.println("Could not find an XML parser");
return;
}
}
// Need better namespace handling
try {
parser.setFeature("http://xml.org/sax/features/namespace-prefixes", true);
}
catch (SAXException e) {
System.err.println(e);
return;
}
for (int i = 0; i < args.length; i++) {
try {
/* URL base;
try {
base = new URL(args[i]);
}
catch (MalformedURLException e) {
File f = new File(args[i]);
base = f.toURL();
} */
XIncludeFilter includer = new XIncludeFilter();
includer.setParent(parser);
SAXXIncluder s = new SAXXIncluder(System.out);
includer.setContentHandler(s);
try {
includer.setProperty(
"http://xml.org/sax/properties/lexical-handler",
s);
s.setFilter(includer);
}
catch (SAXException e) {
// Will not support comments
}
includer.parse(args[i]);
}
catch (Exception e) { // be specific about exceptions????
System.err.println(e);
e.printStackTrace();
}
}
}
}
/*--
Copyright 2000, 2001 Elliotte Rusty Harold.
All rights reserved.
I haven't yet decided on a license.
It will be some form of open source.
THIS SOFTWARE IS PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED
WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE APACHE SOFTWARE FOUNDATION OR
ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF
USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT
OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
SUCH DAMAGE.
*/
package com.macfaq.xml;
import java.net.URL;
import java.net.URLConnection;
import java.net.MalformedURLException;
import java.util.Stack;
import java.util.Iterator;
import java.util.List;
import java.util.LinkedList;
import java.io.File;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.io.InputStreamReader;
import java.io.BufferedInputStream;
import java.io.InputStream;
import org.jdom.Namespace;
import org.jdom.Comment;
import org.jdom.CDATA;
import org.jdom.Text;
import org.jdom.JDOMException;
import org.jdom.Attribute;
import org.jdom.Element;
import org.jdom.ProcessingInstruction;
import org.jdom.Document;
import org.jdom.DocType;
import org.jdom.EntityRef;
import org.jdom.input.SAXBuilder;
import org.jdom.input.DOMBuilder;
import org.jdom.output.XMLOutputter;
/**
* <p><code>JDOMXIncluder</code> provides methods to
* resolve JDOM elements and documents to produce
* a new <code>Document</code>, <code>Element</code>,
* or <code>List</code> of nodes with all
* XInclude references resolved.
* </p>
*
* <p>
* Known bugs include:
* </p>
* <ul>
* <li>XPointer fragment identifiers are not handled</li>
* <li>Notations and unparsed entities from the included infosets
* are not merged into the final infoset</li>
* </ul>
*
* @author Elliotte Rusty Harold
* @version 1.0d8, September 18, 2001
*/
public class JDOMXIncluder {
public final static Namespace XINCLUDE_NAMESPACE
= Namespace.getNamespace("xi", "http://www.w3.org/2001/XInclude");
// No instances allowed
private JDOMXIncluder() {}
private static SAXBuilder builder = new SAXBuilder();
/**
* <p>
* This method resolves a JDOM <code>Document</code>
* and merges in all XInclude references.
* The <code>Document</code> object returned is a new document.
* The original <code>Document</code> is not changed.
* </p>
*
* @param original <code>Document</code> that will be processed
* @param base <code>String</code> form of the base URI against which
* relative URLs will be resolved. This can be null if the
* document includes an <code>xml:base</code> attribute.
* @return Document new <code>Document</code> object in which all
* XInclude elements have been replaced.
* @throws MissingHrefException if an <code>xinclude:include</code> element does not have an href attribute.
* @throws UnavailableResourceException if an included document cannot be located
* or cannot be read.
* @throws MalformedResourceException if an included document is not namespace well-formed
* @throws CircularIncludeException if this document possesses a cycle of
* XIncludes.
* @throws XIncludeException if any of the rules of XInclude are violated
*/
public static Document resolve(Document original, String base)
throws XIncludeException {
if (original == null) {
throw new NullPointerException("Document must not be null");
}
Document result = (Document) original.clone();
Element root = result.getRootElement();
List resolved = resolve(root, base);
// check that the list returned contains
// exactly one root element
Element newRoot = null;
Iterator iterator = resolved.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Element) {
if (newRoot != null) {
throw new XIncludeException("Tried to include multiple roots");
}
newRoot = (Element) o;
}
else if (o instanceof Comment || o instanceof ProcessingInstruction) {
// do nothing
}
else if (o instanceof Text || o instanceof String) {
throw new XIncludeException(
"Tried to include text node outside of root element"
);
}
else if (o instanceof EntityRef) {
throw new XIncludeException(
"Tried to include a general entity reference outside of root element"
);
}
else {
throw new XIncludeException(
"Unexpected type " + o.getClass()
);
}
}
if (newRoot == null) {
throw new XIncludeException("No root element");
}
// Could probably combine two loops
List newContent = result.getContent();
// resolved contains list of new content
// use it to replace old root element
iterator = resolved.iterator();
// put in nodes before root element
int rootPosition = newContent.indexOf(result.getRootElement());
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Comment || o instanceof ProcessingInstruction) {
newContent.add(rootPosition, o);
rootPosition++;
}
else if (o instanceof Element) { // the root
break;
}
else {
// throw exception????
}
}
// put in root element
result.setRootElement(newRoot);
int addPosition = rootPosition+1;
// put in nodes after root element
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Comment || o instanceof ProcessingInstruction) {
newContent.add(addPosition, o);
addPosition++;
}
else {
// throw exception????
}
}
return result;
}
/**
* <p>
* This method resolves a JDOM <code>Element</code>
* and merges in all XInclude references. This process is recursive.
* The element returned contains no XInclude elements.
* If a referenced document cannot be found it is replaced with
* an error message. The <code>Element</code> object returned is a new element.
* The original <code>Element</code> is not changed.
* </p>
*
* @param original <code>Element</code> that will be processed
* @param base <code>String</code> form of the base URI against which
* relative URLs will be resolved. This can be null if the
* element includes an <code>xml:base</code> attribute.
* @return List A List containing all nodes that replace this element.
* If this element is not an <code>xinclude:include</code>
* this list is guaranteed to contain a single <code>Element</code> object.
* @throws MissingHrefException if an <code>xinclude:include</code> element does not have an href attribute.
* @throws NullPointerException if <code>original</code> element is null.
* @throws UnavailableResourceException if an included document cannot be located
* or cannot be read.
* @throws MalformedResourceException if an included document is not namespace well-formed
* @throws CircularIncludeException if this <code>Element</code> contains an XInclude element
* that attempts to include a document in which
* this element is directly or indirectly included.
*/
public static List resolve(Element original, String base)
throws CircularIncludeException, XIncludeException, NullPointerException {
if (original == null) {
throw new NullPointerException("You can't XInclude a null element.");
}
Stack bases = new Stack();
if (base != null) bases.push(base);
List result = resolve(original, bases);
bases.pop();
return result;
}
private static boolean isIncludeElement(Element element) {
if (element.getName().equals("include") &&
element.getNamespace().equals(XINCLUDE_NAMESPACE)) {
return true;
}
return false;
}
/**
* <p>
* This method resolves a JDOM <code>Element</code>
* and merges in all XInclude references. This process is recursive.
* The list returned contains no XInclude elements.
* The nodes in the list returned are new objects.
* The original <code>Element</code> is not changed.
* </p>
*
* @param original <code>Element</code> that will be processed
* @param bases <code>Stack</code> containing the string forms of
* all the URIs of documents which contain this element
* through XIncludes. This is used to detect if any circular
* references occur.
* @return List A <code>List</code> containing all nodes that replace this element.
* If this element is not an <code>xinclude:include</code>
* this list is guaranteed to contain a single <code>Element</code> object.
* @throws MissingHrefException if an <code>xinclude:include</code> element does not have an href attribute.
* @throws UnavailableResourceException if an included document cannot be located
* or cannot be read.
* @throws BadParseAttributeException if an <code>include</code> element has a <code>parse</code> attribute
with any value other than <code>text</code> or <code>parse</code>
* @throws MalformedResourceException if an included document is not namespace well-formed
* @throws CircularIncludeException if this <code>Element</code> contains an XInclude element
* that attempts to include a document in which
* this element is directly or indirectly included.
*/
protected static List resolve(Element original, Stack bases)
throws CircularIncludeException, MalformedResourceException,
UnavailableResourceException, BadParseAttributeException, XIncludeException {
String base = "";
if (bases.size() != 0) base = (String) bases.peek();
if (isIncludeElement(original)) {
return resolveXIncludeElement(original, bases);
}
else {
Element resolvedElement = resolveNonXIncludeElement(original, bases);
List resultList = new LinkedList();
resultList.add(resolvedElement);
return resultList;
}
}
private static List resolveXIncludeElement(Element original, Stack bases)
throws CircularIncludeException, MalformedResourceException,
UnavailableResourceException, XIncludeException {
String base = "";
if (bases.size() != 0) base = (String) bases.peek();
// These lines are probably unnecessary
if (!isIncludeElement(original)) {
throw new RuntimeException("Bad private Call");
}
Attribute href = original.getAttribute("href");
if (href == null) {
throw new MissingHrefException("Missing href attribute");
}
Attribute baseAttribute
= original.getAttribute("base", Namespace.XML_NAMESPACE);
if (baseAttribute != null) {
base = baseAttribute.getValue();
}
URL remote;
if (base != null) {
try {
URL context = new URL(base);
remote = new URL(context, href.getValue());
}
catch (MalformedURLException ex) {
XIncludeException xex = new UnavailableResourceException(
"Unresolvable URL " + base + "/" + href);
xex.setRootCause(ex);
throw xex;
}
}
else { // base == null
try {
remote = new URL(href.getValue());
}
catch (MalformedURLException ex) {
XIncludeException xex = new UnavailableResourceException(
"Unresolvable URL " + href.getValue());
xex.setRootCause(ex);
throw xex;
}
}
boolean parse = true;
Attribute parseAttribute = original.getAttribute("parse");
if (parseAttribute != null) {
String parseValue = parseAttribute.getValue();
if (parseValue.equals("text")) parse = false;
else if (!parseValue.equals("xml")) {
throw new BadParseAttributeException(
parseAttribute + "is not a legal value for the parse attribute"
);
}
}
if (parse) {
// System.err.println("parsed");
// checks for equality (OK) or identity (not OK)????
if (bases.contains(remote.toExternalForm())) {
// need to figure out how to get file and number where
// bad include occurs
throw new CircularIncludeException(
"Circular XInclude Reference to "
+ remote.toExternalForm() + " in "
);
}
try {
Document doc = builder.build(remote); // this Document object never leaves this method
// System.err.println(doc);
bases.push(remote.toExternalForm());
// This is the point where I need to select out
// the nodes pointed to by the XPointer
// I really need to push this out into a separate method
// that returns a list of the nodes pointed to by the XPointer
String fragment = remote.getRef();
// I need to return the full document child list including comments and PIs,
// not just the resolved root
Element root = doc.getRootElement();
List topLevelNodes = doc.getContent();
int rootPosition = topLevelNodes.indexOf(root);
List beforeRoot = topLevelNodes.subList(0, rootPosition);
List afterRoot = topLevelNodes.subList(rootPosition+1, topLevelNodes.size());
List rootList = resolve(root, bases);
List resultList = new LinkedList();
resultList.addAll(beforeRoot);
resultList.addAll(rootList);
resultList.addAll(afterRoot);
// the top-level things I return should be disconnected from their parents
for (int i = 0; i < resultList.size(); i++) {
Object o = resultList.get(i);
if (o instanceof Element) {
Element element = (Element) o;
List nodes = resolve(element, bases);
resultList.addAll(i, nodes);
i += nodes.size();
resultList.remove(i);
i--;
// System.err.println(element);
element.detach();
}
if (o instanceof Comment) {
Comment comment = (Comment) o;
comment.detach();
}
if (o instanceof ProcessingInstruction) {
ProcessingInstruction pi = (ProcessingInstruction) o;
pi.detach();
}
}
bases.pop();
return resultList;
}
// should this be a MalformedResourceException????
// probably; maybe check on why JDOMException was thrown
catch (JDOMException e) {
XIncludeException xex = new UnavailableResourceException(
"Unresolvable URL " + href.getValue());
xex.setRootCause(e);
throw xex;
}
}
else { // unparsed, insert text
String encoding = original.getAttributeValue("encoding");
String s = downloadTextDocument(remote, encoding);
List resultList = new LinkedList();
resultList.add(s);
return resultList;
}
}
private static Element resolveNonXIncludeElement(Element original, Stack bases)
throws CircularIncludeException, MalformedResourceException,
UnavailableResourceException, XIncludeException {
String base = "";
if (bases.size() != 0) base = (String) bases.peek();
// Not an include element; a copy of this element in which its
// descendants have been resolved will be returned
// recursively process children
Element result = new Element(original.getName(), original.getNamespace());
Iterator attributes = original.getAttributes().iterator();
while (attributes.hasNext()) {
Attribute a = (Attribute) attributes.next();
result.setAttribute((Attribute) a.clone());
}
List newChildren = result.getContent(); // live list
Iterator originalChildren = original.getContent().iterator();
while (originalChildren.hasNext()) {
Object o = originalChildren.next();
if (o instanceof Element) {
Element element = (Element) o;
if (isIncludeElement(element)) {
newChildren.addAll(resolveXIncludeElement(element, bases));
}
else {
newChildren.add(resolveNonXIncludeElement(element, bases));
}
}
else if (o instanceof String) {
newChildren.add(o);
}
else if (o instanceof Text) {
newChildren.add(o);
}
else if (o instanceof CDATA) {
newChildren.add(o);
}
else if (o instanceof Comment) {
Comment c = (Comment) o;
newChildren.add(c.clone());
}
else if (o instanceof EntityRef) {
EntityRef entity = (EntityRef) o;
newChildren.add(entity.clone());
}
else if (o instanceof ProcessingInstruction) {
ProcessingInstruction pi = (ProcessingInstruction) o;
newChildren.add(pi.clone());
}
else {
throw new XIncludeException("Unexpected Type " + o.getClass());
}
} // end while
return result;
}
/**
* <p>
* This utility method reads a document at a specified URL
* and returns the contents of that document as a <code>String</code>.
* It's used to include files with <code>parse="text"</code>.
* </p>
*
* @param source <code>URL</code> of the document that will be stored in
* <code>String</code>.
* @param encoding Encoding of the document; e.g. UTF-8,
* ISO-8859-1, etc.
* @return String The document retrieved from the source <code>URL</code>.
* @throws UnavailableResourceException if the source document cannot be located
* or cannot be read.
*/
public static String downloadTextDocument(URL source, String encoding)
throws UnavailableResourceException {
if (encoding == null || encoding.equals("")) encoding = "UTF-8";
try {
StringBuffer s = new StringBuffer();
URLConnection uc = source.openConnection();
String encodingFromHeader = uc.getContentEncoding();
String contentType = uc.getContentType();
InputStream in = new BufferedInputStream(uc.getInputStream());
if (encodingFromHeader != null) encoding = encodingFromHeader;
else {
// What if file does not have a MIME type but name ends in .xml????
// MIME types are case-insensitive
// Java may be picking this up from file URL
if (contentType != null) {
contentType = contentType.toLowerCase();
if (contentType.equals("text/xml")
|| contentType.equals("application/xml")
|| (contentType.startsWith("text/") && contentType.endsWith("+xml") )
|| (contentType.startsWith("application/") && contentType.endsWith("+xml"))) {
encoding = EncodingHeuristics.readEncodingFromStream(in);
}
}
}
InputStreamReader reader = new InputStreamReader(in, encoding);
int c;
while ((c = in.read()) != -1) {
if (c == '<') s.append("<");
else if (c == '&') s.append("&");
else s.append((char) c);
}
return s.toString();
}
catch (UnsupportedEncodingException e) {
UnavailableResourceException ex = new UnavailableResourceException(
"Encoding " + encoding + " not recognized for included document: "
+ source.toExternalForm());
ex.setRootCause(e);
throw ex;
}
catch (IOException e) {
UnavailableResourceException ex = new UnavailableResourceException(
"Document not found: " + source.toExternalForm());
ex.setRootCause(e);
throw ex;
}
}
/**
* <p>
* The driver method for the XIncluder program.
* I'll probably move this to a separate class soon.
* </p>
*
* @param args <code>args[0]</code> contains the URL or file name
* of the first document to be processed; <code>args[1]</code>
* contains the URL or file name
* of the second document to be processed, etc.
*/
public static void main(String[] args) {
SAXBuilder builder = new SAXBuilder();
XMLOutputter outputter = new XMLOutputter();
for (int i = 0; i < args.length; i++) {
try {
Document input = builder.build(args[i]);
// absolutize URL
String base = args[i];
if (base.indexOf(':') < 0) {
File f = new File(base);
base = f.toURL().toExternalForm();
}
Document output = resolve(input, base);
// need to set encoding on this to Latin-1 and check what
// happens to UTF-8 curly quotes
outputter.output(output, System.out);
}
catch (Exception e) {
System.err.println(e);
e.printStackTrace();
}
}
}
}
/*--
Copyright 2001 Elliotte Rusty Harold.
All rights reserved.
I haven't yet decided on a license.
It will be some form of open source.
THIS SOFTWARE IS PROVIDED "AS IS" AND ANY EXPRESSED OR IMPLIED
WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL ELLIOTTE RUSTY HAROLD OR ANY
OTHER CONTRIBUTORS TO THIS PACKAGE
BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF
USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT
OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
SUCH DAMAGE.
*/
package com.macfaq.xml;
import java.net.URL;
import java.net.URLConnection;
import java.net.MalformedURLException;
import java.util.Stack;
import java.util.List;
import java.util.ArrayList;
import java.io.File;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.io.InputStreamReader;
import java.io.BufferedInputStream;
import java.io.InputStream;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.w3c.dom.Element;
import org.w3c.dom.Document;
import org.w3c.dom.Comment;
import org.w3c.dom.ProcessingInstruction;
import org.w3c.dom.DocumentType;
import org.w3c.dom.Text;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.DOMImplementation;
import org.apache.xerces.parsers.DOMParser;
import org.apache.xml.serialize.OutputFormat;
import org.apache.xml.serialize.XMLSerializer;
/**
* <p><code>DOMXIncluder</code> provides methods to
* resolve DOM elements and documents to produce
* a new <code>Document</code> or <code>Element</code> with all
* XInclude references resolved.
* </p>
*
* <p>
* It does not yet handle the merging of unparsed entity
* and notation information items from the included infosets.
* Furthermore it does not include the source document's doctype
* declaration if that contains an internal DTD subset.
* This may be the result of a Xerces bug.
* </p>
*
*
* @author Elliotte Rusty Harold
* @version 1.0d8
*/
public class DOMXIncluder {
public final static String XINCLUDE_NAMESPACE
= "http://www.w3.org/2001/XInclude";
public final static String XML_NAMESPACE
= "http://www.w3.org/XML/1998/namespace";
// No instances allowed
private DOMXIncluder() {}
private static DOMParser parser = new DOMParser();
/**
* <p>
* This method resolves a DOM <code>Document</code>
* and merges in all XInclude references.
* The <code>Document</code> object returned is a new document.
* The original <code>Document</code> object is not changed.
* </p>
*
* <p>
* This method depends on the ability to clone a DOM <code>Document</code>
* which not all DOM parsers may be able to do.
* It definitely exercises a bug in Xerces-J 1.3.1.
* This bug is fixed in Xerces-J 1.4.0.
* </p>
*
* @param original <code>Document</code> that will be processed
* @param base <code>String</code> form of the base URI against which
* relative URLs will be resolved. This can be null if the
* document includes an <code>xml:base</code> attribute.
* @return Document new <code>Document</code> object in which all
* XInclude elements have been replaced.
* @throws XIncludeException if this document, though namespace well-formed,
* violates one of the rules of XInclude.
* @throws NullPointerException if the original argument is null.
*/
public static Document resolve(Document original, String base)
throws XIncludeException, NullPointerException {
if (original == null) {
throw new NullPointerException("Document must not be null");
}
Document resultDocument = (Document) original.cloneNode(true);
// This clone doesn't seem to include the DOCTYPE
// if there's an internal DTD subset????
// Is this the correct behavior? No, a bug in Xerces 1.4.3
Element resultRoot = resultDocument.getDocumentElement();
// Should this method return a DocumentFragment instead of a
// NodeList????
NodeList resolved = resolve(resultRoot, base, resultDocument);
// Check that this contains exactly one root element
// and no Text, DocumentType, or other nodes
int numberRoots = 0;
for (int i = 0; i < resolved.getLength(); i++) {
if (resolved.item(i) instanceof Comment
|| resolved.item(i) instanceof ProcessingInstruction) {
continue;
}
else if (resolved.item(i) instanceof Element) numberRoots++;
else if (resolved.item(i) instanceof Text) {
throw new XIncludeException(
"Tried to include text node outside document element");
}
else {
throw new XIncludeException(
// convert type to a string????
"Cannot include a " + resolved.item(i).getNodeType() + " node");
}
}
if (numberRoots != 1) {
throw new XIncludeException("Tried to include multiple roots");
}
// insert nodes before the root
int nodeIndex = 0;
while (nodeIndex < resolved.getLength()) {
if (resolved.item(nodeIndex) instanceof Element) break;
resultDocument.insertBefore(resolved.item(nodeIndex), resultRoot);
nodeIndex++;
}
// insert new root
resultDocument.replaceChild(
resolved.item(nodeIndex), resultRoot
);
nodeIndex++;
//insert nodes after new root
Node refNode = resultDocument.getDocumentElement().getNextSibling();
if (refNode == null) {
while (nodeIndex < resolved.getLength()) {
resultDocument.appendChild(resolved.item(nodeIndex));
nodeIndex++;
}
}
else {
while (nodeIndex < resolved.getLength()) {
resultDocument.insertBefore(resolved.item(nodeIndex), refNode);
nodeIndex++;
}
}
return resultDocument;
}
/**
* <p>
* This method resolves a DOM <code>Element</code>
* and merges in all XInclude references. This process is recursive.
* The element returned contains no XInclude elements.
* If a referenced document cannot be found it is replaced with
* an error message. The <code>Element</code> object returned is a new element.
* The original <code>Element</code> is not changed.
* </p>
*
* @param original <code>Element</code> that will be processed
* @param base <code>String</code> form of the base URI against which
* relative URLs will be resolved. This can be null if the
* element includes an <code>xml:base</code> attribute.
* @param resolved <code>Document</code> into which the resolved element will be placed.
* @return NodeList the infoset that this element resolves to
* @throws CircularIncludeException if this <code>Element</code> contains an XInclude element
* that attempts to include a document in which
* this element is directly or indirectly included.
* @throws NullPointerException if the <code>original</code> argument is null.
*/
public static NodeList resolve(Element original, String base, Document resolved)
throws XIncludeException, NullPointerException {
if (original == null) {
throw new NullPointerException(
"You can't XInclude a null element."
);
}
Stack bases = new Stack();
if (base != null) bases.push(base);
NodeList result = resolve(original, bases, resolved);
bases.pop();
return result;
}
private static boolean isIncludeElement(Element element) {
if (element.getLocalName().equals("include") &&
element.getNamespaceURI().equals(XINCLUDE_NAMESPACE)) {
return true;
}
return false;
}
/**
* <p>
* This method resolves a DOM <code>Element</code> into an infoset
* and merges in all XInclude references. This process is recursive.
* The returned infoset contains no XInclude elements.
* If a referenced document cannot be found it is replaced with
* an error message. The <code>NodeList</code> object returned is new.
* The original <code>Element</code> is not changed.
* </p>
*
* @param original <code>Element</code> that will be processed
* @param bases <code>Stack</code> containing the string forms of
* all the URIs of documents which contain this element
* through XIncludes. This used to detect if a circular
* reference is being used.
* @param resolved <code>Document</code> into which the resolved element will be placed.
* @return NodeList the infoset into whihc this element resolves. This is just a copy
of the element if the element is not an XInclude element and does
not contain any XInclude elements.
* @throws CircularIncludeException if this <code>Element</code> contains an XInclude element
* that attempts to include a document in which
* this element is directly or indirectly included.
* @throws MissingHrefException if the <code>href</code> attribute is missing from an include element.
* @throws MalformedResourceException if an included document is not namespace well-formed
* @throws BadParseAttributeException if an <code>include</code> element has a <code>parse</code> attribute
with any value other than <code>text</code> or <code>parse</code>
* @throws UnavailableResourceException if the URL in the include element's
<code>href</code> attribute cannot be loaded.
* @throws XIncludeException if this document, though namespace well-formed,
* violates one of the rules of XInclude.
*/
private static NodeList resolve(Element original, Stack bases, Document resolved)
throws CircularIncludeException, MissingHrefException, MalformedResourceException,
BadParseAttributeException, UnavailableResourceException, XIncludeException {
XIncludeNodeList result = new XIncludeNodeList();
String base = null;
if (bases.size() != 0) base = (String) bases.peek();
if (isIncludeElement(original)) {
// Verify that there is an href attribute
if (!original.hasAttribute("href")) {
throw new MissingHrefException("Missing href attribute");
}
String href = original.getAttribute("href");
// Check for a base attribute
String baseAttribute
= original.getAttributeNS(XML_NAMESPACE, "base");
if (baseAttribute != null && !baseAttribute.equals("")) {
base = baseAttribute;
}
String remote;
if (base != null) {
try {
URL context = new URL(base);
URL u = new URL(context, href);
remote = u.toExternalForm();
}
catch (MalformedURLException ex) {
XIncludeException xex = new UnavailableResourceException(
"Unresolvable URL " + base + "/" + href);
xex.setRootCause(ex);
throw xex;
}
}
else {
remote = href;
}
// check for parse attribute; default is true
boolean parse = true;
if (original.hasAttribute("parse")) {
String parseAttribute = original.getAttribute("parse");
if (parseAttribute.equals("text")) {
parse = false;
}
else if (!parseAttribute.equals("xml")) {
throw new BadParseAttributeException(
parseAttribute + "is not a legal value for the parse attribute"
);
}
}
if (parse) {
// checks for equality (OK) or identity (not OK)????
if (bases.contains(remote)) {
// need to figure out how to get file and number where
// bad include occurs????
throw new CircularIncludeException(
"Circular XInclude Reference to "
+ remote + " in " );
}
try {
parser.parse(remote);
Document doc = parser.getDocument();
bases.push(remote);
// this method needs to remove DocType node if any
NodeList docChildren = doc.getChildNodes();
for (int i = 0; i < docChildren.getLength(); i++) {
Node node = docChildren.item(i);
if (node instanceof Element) {
result.add(resolve((Element) node, bases, resolved));
}
else if (node instanceof DocumentType) continue;
else result.add(node);
}
bases.pop();
}
catch (SAXParseException e) {
int line = e.getLineNumber();
int column = e.getColumnNumber();
if (line <= 0) {
XIncludeException ex = new UnavailableResourceException("Document "
+ remote + " was not found.");
ex.setRootCause(e);
throw ex;
}
else {
XIncludeException ex = new MalformedResourceException("Document "
+ remote + " is not well-formed at line " + line + ", column " + column);
ex.setRootCause(e);
throw ex;
}
}
catch (SAXException e) {
XIncludeException ex = new MalformedResourceException("Document "
+ remote + " is not well-formed.");
ex.setRootCause(e);
throw ex;
}
catch (IOException e) {
XIncludeException ex
= new UnavailableResourceException("Document not found: "
+ remote);
ex.setRootCause(e);
throw ex;
}
}
else { // insert text
String encoding = original.getAttribute("encoding");
String s = downloadTextDocument(remote, encoding);
result.add(resolved.createTextNode(s));
}
}
// not an include element
else { // recursively process children
// still need to adjust bases here????
// replace nodes instead
// Do I need to explicitly attach attributes here or does
// importing take care of that????
Element copy = (Element) resolved.importNode(original, false);
NodeList children = original.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n instanceof Element) {
Element e = (Element) n;
NodeList kids = resolve(e, bases, resolved);
for (int j = 0; j < kids.getLength(); j++) {
copy.appendChild(kids.item(j));
}
}
else {
copy.appendChild(resolved.importNode(n, true));
}
}
result.add(copy);
}
return result;
}
/**
* <p>
* This utility method reads a document at a specified URL
* and returns the contents of that document as a <code>Text</code>.
* It's used to include files with <code>parse="text"</code>
* </p>
*
* @param url URL of the document that will be stored in
* <code>String</code>.
* @param encoding Encoding of the document; e.g. UTF-8,
* ISO-8859-1, etc. If this is null or the empty string
* then UTF-8 is guessed.
* @return String The document retrieved from the source <code>URL</code>
* @throws UnavailableResourceException if the requested document cannot
be downloaded from the specified URL.
*/
private static String downloadTextDocument(String url, String encoding)
throws UnavailableResourceException {
if (encoding == null || encoding.equals("")) {
encoding = "UTF-8";
// should try to read encoding from HTTP header
// and XML declaration heuristics
}
URL source;
try {
source = new URL(url);
}
catch (MalformedURLException e) {
UnavailableResourceException ex =
new UnavailableResourceException("Unresolvable URL " + url);
ex.setRootCause(e);
throw ex;
}
StringBuffer s = new StringBuffer();
try {
URLConnection uc = source.openConnection();
InputStream in = new BufferedInputStream(uc.getInputStream());
String encodingFromHeader = uc.getContentEncoding();
String contentType = uc.getContentType();
if (encodingFromHeader != null) encoding = encodingFromHeader;
else {
// What if file does not have a MIME type but name ends in .xml????
// MIME types are case-insensitive
// Java may be picking this up from file URL
if (contentType != null) {
contentType = contentType.toLowerCase();
if (contentType.equals("text/xml")
|| contentType.equals("application/xml")
|| (contentType.startsWith("text/") && contentType.endsWith("+xml") )
|| (contentType.startsWith("application/") && contentType.endsWith("+xml"))) {
encoding = EncodingHeuristics.readEncodingFromStream(in);
}
}
}
InputStreamReader reader = new InputStreamReader(in, encoding);
int c;
while ((c = in.read()) != -1) {
s.append((char) c);
}
return s.toString();
}
catch (UnsupportedEncodingException e) {
UnavailableResourceException ex = new UnavailableResourceException(
"Encoding not recognized for document " + source.toExternalForm());
ex.setRootCause(e);
throw ex;
}
catch (IOException e) {
UnavailableResourceException ex = new UnavailableResourceException(
"Document not found: " + source.toExternalForm());
ex.setRootCause(e);
throw ex;
}
}
/**
* <p>
* The driver method for the XIncluder program.
* I'll probably move this to a separate class soon.
* </p>
*
* @param args contains the URLs and/or filenames
* of the documents to be procesed.
*/
public static void main(String[] args) {
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
parser.parse(args[i]);
Document input = parser.getDocument();
// absolutize URL
String base = args[i];
if (base.indexOf(':') < 0) {
File f = new File(base);
base = f.toURL().toExternalForm();
}
Document output = resolve(input, base);
// need to set encoding on this to Latin-1 and check what
// happens to UTF-8 curly quotes
OutputFormat format = new OutputFormat("XML", "ISO-8859-1", false);
format.setPreserveSpace(true);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(output);
}
catch (Exception e) {
System.err.println(e);
e.printStackTrace();
}
}
}
}
// I need to create NodeLists in a parser independent fashion
class XIncludeNodeList implements NodeList {
private List data = new ArrayList();
// could easily expose more List methods if they seem useful
public void add(int index, Node node) {
data.add(index, node);
}
public void add(Node node) {
data.add(node);
}
public void add(NodeList nodes) {
for (int i = 0; i < nodes.getLength(); i++) {
data.add(nodes.item(i));
}
}
public Node item(int index) {
return (Node) data.get(index);
}
// copy DOM JavaDoc
public int getLength() {
return data.size();
}
}
This presentation: http://www.ibiblio.org/xml/slides/xmlone/amsterdam2001/hypertext/
XInclude Specification: http://www.w3.org/TR/xinclude
XML Bible, Gold edition
Elliotte Rusty Harold
Hungry Minds, 2001
ISBN 0-7645-4819-0
This presentation: http://www.ibiblio.org/xml/slides/xmlone/amsterdam2001/hypertext
XML Base Specification: http://www.w3.org/TR/xmlbase
XPath Specification: http://www.w3.org/TR/xpath
XInclude Specification: http://www.w3.org/TR/xinclude
XML in a Nutshell
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2001
ISBN 0-596-00058-8
XPath: http://www.oreilly.com/catalog/xmlnut/chapter/ch09.html
 XML Bible, second edition
XML Bible, second edition
Elliotte Rusty Harold
Hungry Minds, 2001
ISBN 0-7645-4760-7
XLinks: http://www.ibiblio.org/xml/books/bible2/chapters/ch19.html
XPointers: http://www.ibiblio.org/xml/books/bible2/chapters/ch20.html