XML Pull Parsing
Elliotte Rusty Harold
Software Development 2002 East
Wednesday, November 20, 2002
elharo@metalab.unc.edu
http://www.cafeconleche.org/

XML Pull ParsingElliotte Rusty HaroldSoftware Development 2002 EastWednesday, November 20, 2002elharo@metalab.unc.eduhttp://www.cafeconleche.org/
|
Push: SAX, XNI
Tree: DOM, JDOM, XOM, ElectricXML, dom4j, Sparta
Data binding: Castor, Zeus, JAXB
Pull
pull parsing is the way to go in the future. The first 3 XML parsers (Lark, NXP, and expat) all were event-driven because... er well that was 1996, can't exactly remember, seemed like a good idea at the time.
--Tim Bray on the xml-dev mailing list, Wednesday, 18 Sep 2002
Fast
Memory efficient
Streamable
Read-only
XMLPULL
NekoPull
StAX
.Net
Open Source
http://www.xmlpull.org/
Designed for Java 2 Micro Edition (J2ME)
Two implementations:
Enhydra's kXML2: http://www.kxml.org/
Aleksander Slominski's XPP3/MXP1 http://www.extreme.indiana.edu/soap/xpp/mxp1/
![]()
XmlPullParser:XmlPullParserFactory:XmlPullParserXmlPullException:IOException
that might go wrong when parsing an
XML document, particularly well-formedness errors and tokens that don't have the expected typeXmlSerializer:import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PullChecker {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PullChecker url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
for (int event = parser.next();
event != XmlPullParser.END_DOCUMENT ;
event = parser.next()) ;
// If we get here there are no exceptions
System.out.println(args[0] + " is well-formed");
}
catch (XmlPullParserException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
~
The event codes returned by next()/nextToken()/nextTag()
inform you of what the parser read.
Ten event codes:
XmlPullParser.START_DOCUMENT
XmlPullParser.END_DOCUMENT
XmlPullParser.START_TAG
XmlPullParser.END_TAG
XmlPullParser.TEXT
XmlPullParser.CDSECT
XmlPullParser.ENTITY_REF
XmlPullParser.IGNORABLE_WHITESPACE
XmlPullParser.PROCESSING_INSTRUCTION
XmlPullParser.COMMENT
XmlPullParser.DOCDECL
Depending on what the event is, different methods are available on the XmlPullParser
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class EventLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java EventLister url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
System.out.println("Start tag");
}
else if (event == XmlPullParser.END_TAG) {
System.out.println("End tag");
}
else if (event == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document");
}
else if (event == XmlPullParser.TEXT) {
System.out.println("Text");
}
else if (event == XmlPullParser.CDSECT) {
System.out.println("CDATA Section");
}
else if (event == XmlPullParser.COMMENT) {
System.out.println("Comment");
}
else if (event == XmlPullParser.DOCDECL) {
System.out.println("Document type declaration");
}
else if (event == XmlPullParser.ENTITY_REF) {
System.out.println("Entity Reference");
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
System.out.println("Ignorable white space");
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Processing Instruction");
}
else if (event == XmlPullParser.END_DOCUMENT) {
System.out.println("End Document");
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
The getText()
method returns the text of the current event:
public String getText()Exactly what this is depends on the type of the event:
For tags, it's null, unless round-tripping is turned on, in which case it's the complete actual tag.
For entity references, it's the entity replacement text (or null if this is not available).
For text and ignorable white space, it's the actual text.
For CDATA sections, it's the text inside the CDATA section delimiters,
that is, between <![CDATA[ and ]]>.
For start and end document, it's null.
For comments, it's the content of the comment inside the <-- and -->.
For processing instructions, it's the content of the instruction inside the <? and ?>.
For document type declarations, it's the content of the DOCTYPE declaration between <!DOCTYPE and the closing >.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class EventText {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java EventText url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
System.out.println("Start-tag: " + parser.getText()) ;
}
else if (event == XmlPullParser.END_TAG) {
System.out.println("End-tag: " + parser.getText());
}
else if (event == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document: " + parser.getText());
}
else if (event == XmlPullParser.TEXT) {
System.out.println("Text: " + parser.getText());
}
else if (event == XmlPullParser.CDSECT) {
System.out.println("CDATA Section: " + parser.getText());
}
else if (event == XmlPullParser.COMMENT) {
System.out.println("Comment: " + parser.getText());
}
else if (event == XmlPullParser.DOCDECL) {
System.out.println("Document type declaration: " + parser.getText());
}
else if (event == XmlPullParser.ENTITY_REF) {
System.out.println("Entity Reference: " + parser.getText());
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
System.out.println("Ignorable white space: " + parser.getText());
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Processing Instruction: " + parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
System.out.println("End Document: " + parser.getText());
break;
} // end else if
} // end while
} // end try
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Unlike most APIs, XMLPULL can provide the client application with the complete input text. Fully faithful round tripping is possible.
If the event is a tag, then the following methods
in XmlPullParser also work:
public String getName()
public String getNamespace()
public String getPrefix()getName() returns the local (unprefixed) name of the tag
getNamespace() returns the namespace URI, or the empty string
if the tag is not in a namespace
getPrefix() returns the prefix of the tag, or null if the tag does not have a prefix
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class NamePrinter {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NamePrinter url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
System.out.println("Start tag: ");
printEvent(parser);
}
else if (event == XmlPullParser.END_TAG) {
System.out.println("End tag");
printEvent(parser);
}
else if (event == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document");
}
else if (event == XmlPullParser.TEXT) {
System.out.println("Text");
printEvent(parser);
}
else if (event == XmlPullParser.CDSECT) {
System.out.println("CDATA Section");
printEvent(parser);
}
else if (event == XmlPullParser.COMMENT) {
System.out.println("Comment");
printEvent(parser);
}
else if (event == XmlPullParser.DOCDECL) {
System.out.println("Document type declaration");
printEvent(parser);
}
else if (event == XmlPullParser.ENTITY_REF) {
System.out.println("Entity Reference");
printEvent(parser);
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
System.out.println("Ignorable white space");
printEvent(parser);
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Processing Instruction");
printEvent(parser);
}
else if (event == XmlPullParser.END_DOCUMENT) {
System.out.println("End Document");
break;
} // end else if
} // end while
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException ex) {
System.out.println("IOException while parsing " + args[0]);
ex.printStackTrace();
}
}
private static void printEvent(XmlPullParser parser) {
String localName = parser.getName();
String prefix = parser.getPrefix();
String uri = parser.getNamespace();
if (localName != null) System.out.println("\tName: " + localName);
if (prefix != null) System.out.println("\tPrefix: " + prefix);
if (uri != null) System.out.println("\tNamespace URI: " + uri);
System.out.println();
}
}
Like nextToken() except that it only reports:
START_TAG
TEXT
END_TAG
END_DOCUMENT
CDATA sections and entity references are accumulated into the above four types.
Other events are silently skipped
List all the titles in an RSS 0.91 document:
<?xml version="1.0" encoding="iso-8859-1" ?>
<!-- generator="HPE/1.0" -->
<!-- Copyright (C) 2000-2002 News Is Free. Terms Of Service http://www.newsisfree.com/termsofservice.php -->
<rss version="0.91">
<channel>
<title>Ananova: <!-- interrupting comment -->Archeology</title>
<link>http://www.ananova.com/news/index.html?keywords=Archaeology&menu=news.scienceanddiscovery.archaeology</link>
<description>Ananova: News on the move from the leading site for breaking
UK and world news, sport, entertainment, business and weather stories and information.
(By http://www.newsisfree.com/syndicate.php
- FOR PERSONAL AND NON COMMERCIAL USE ONLY!)</description>
<language>en</language>
<webMaster>mkrus@newsisfree.com</webMaster>
<lastBuildDate>11/05/02 22:16 CET</lastBuildDate>
<image>
<link>http://www.newsisfree.com/sources/info/3389/</link>
<url>http://www.newsisfree.com/HPE/Images/button.gif</url>
<title>Powered by News Is Free</title><width>88</width>
<height>31</height>
</image>
<item>
<title>Britain's earliest leprosy victim may have been found</title>
<link>http://www.newsisfree.com/click/-2,9782455,3389/</link>
</item>
<item>
<title>20th anniversary of Mary Rose recovery</title>
<link>http://www.newsisfree.com/click/-2,9773139,3389/</link>
</item>
<item>
<title>'Proof of Jesus' burial box damaged on way to Canada</title>
<link>http://www.newsisfree.com/click/-6,9663454,3389/</link>
</item>
<item>
<title>Remains of four woolly rhinos give new insight into Ice Age</title>
<link>http://www.newsisfree.com/click/-4,9533904,3389/</link>
</item>
<item>
<title>Experts solve crop lines mystery</title>
<link>http://www.newsisfree.com/click/-5,9352720,3389/</link>
</item>
</channel>
</rss>
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class RSSTitles {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java RSSTitles url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
boolean printing = false;
while (true) {
int event = parser.next();
if (event == XmlPullParser.START_TAG) {
String name = parser.getName();
if (name.equals("title")) printing = true;
}
else if (event == XmlPullParser.END_TAG) {
String name = parser.getName();
if (name.equals("title")) printing = false;
}
else if (event == XmlPullParser.TEXT) {
if (printing) System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
} // end else if
} // end while
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException ex) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Print only item titles:
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class BetterRSSLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java BetterRSSLister url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
boolean inItem = false;
boolean inTitle = false;
// Nested elements could be handled by incrementing
// and decrementing an integer instead
// of a simple boolean.
while (true) {
int event = parser.next();
if (event == XmlPullParser.START_TAG) {
String name = parser.getName();
if (name.equals("title")) inTitle = true;
if (name.equals("item")) inItem = true;
}
else if (event == XmlPullParser.END_TAG) {
String name = parser.getName();
if (name.equals("title")) inTitle = false;
if (name.equals("item")) inItem = false;
}
else if (event == XmlPullParser.TEXT) {
if (inTitle && inItem) System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
} // end else if
} // end while
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException ex) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Like next() but also skips text nodes that contain
only white space
It only reports:
START_TAG
END_TAG
Other tokens throw exceptions
Useful for skipping practically ignorable whitespace.
Can only be called after a start-tag event
Reads and returns all text up till end-tag
Returns empty-string for empty-element tag
Throws exception if there are any nested elements/tags
Enables same code to handle
<name></name>, <name/>, and
<name>PCDATA</name>.
These methods are invokable when the event type is START_TAG:
public int getAttributeCount()
public String getAttributeNamespace(int index)
public String getAttributeName(int index)
public String getAttributePrefix(int index)
public String getAttributeType(int index)
public boolean isAttributeDefault(int index)
public String getAttributeValue(int index)
public String getAttributeValue(String namespace, String name)By default, xmlns and xmlns:prefix attributes are reported
If the http://xmlpull.org/v1/doc/features.html#process-namespaces
feature is true, xmlns and xmlns:prefix attributes are not reported
unless http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes is also true.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
import java.util.*;
public class PullSpider {
// Need to keep track of where we've been
// so we don't get stuck in an infinite loop
private List spideredURIs = new Vector();
// This linked list keeps track of where we're going.
// Although the LinkedList class does not guarantee queue like
// access, I always access it in a first-in/first-out fashion.
private LinkedList queue = new LinkedList();
private URL currentURL;
private XmlPullParser parser;
public PullSpider() {
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
this.parser = factory.newPullParser();
}
catch (XmlPullParserException ex) {
throw new RuntimeException("Could not locate a pull parser");
}
}
private void processStartTag() {
String type
= parser.getAttributeValue("http://www.w3.org/1999/xlink", "type");
if (type != null) {
String href
= parser.getAttributeValue("http://www.w3.org/1999/xlink", "href");
if (href != null) {
try {
URL foundURL = new URL(currentURL, href);
if (!spideredURIs.contains(foundURL)) {
queue.addFirst(foundURL);
}
}
catch (MalformedURLException ex) {
// skip it
}
}
}
}
public void spider(URL uri) {
System.out.println("Spidering " + uri);
currentURL = uri;
try {
parser.setInput(this.currentURL.openStream(), null);
spideredURIs.add(currentURL);
for (int event = parser.next(); event != XmlPullParser.END_DOCUMENT; event = parser.next()) {
if (event == XmlPullParser.START_TAG) {
processStartTag();
}
} // end for
while (!queue.isEmpty()) {
URL nextURL = (URL) queue.removeLast();
spider(nextURL);
}
}
catch (Exception ex) {
// skip this document
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.err.println("Usage: java PullSpider url" );
return;
}
PullSpider spider = new PullSpider();
spider.spider(new URL(args[0]));
} // end main
} // end PullSpider
Unlike SAX, JDOM, and DOM, processing instructions don't really require any special treatment, classes, or methods.
What should happen:
The getName() method returns the target.
The getText() method returns the data.
What does happen:
The getName() method returns null.
The getText() method returns the complete content between the <?
and ?>.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PILister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PILister url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Target: " + parser.getName());
System.out.println("Data: " + parser.getText());
System.out.println();
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Unlike SAX, JDOM, and DOM, comments don't really require any special treatment, classes, or methods.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class CommentPuller {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java CommentPuller url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.COMMENT) {
System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
As in SAX, features are boolean; properties have object values.
Features and properties are named by URIs.
All features are false by default.
Properties aren't used much.
public void setFeature(String name, boolean state)
throws XmlPullParserException;
public boolean getFeature(String name);
public void setProperty(String name, Object value)
throws XmlPullParserException;
public Object getProperty(String name);http://xmlpull.org/v1/doc/features.html#process-namespaces
http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes
http://xmlpull.org/v1/doc/features.html#process-docdecl
http://xmlpull.org/v1/doc/features.html#validation
http://xmlpull.org/v1/doc/features.html#names-interned
http://xmlpull.org/v1/doc/features.html#expand-entity-ref
http://xmlpull.org/v1/doc/features.html#xml-roundtrip
http://xmlpull.org/v1/doc/features.html#detect-encoding
http://xmlpull.org/v1/doc/features.html#serializer-attvalue-use-apostrophe
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PullValidator {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PullValidator url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
try {
parser.setFeature(XmlPullParser.FEATURE_VALIDATION, true);
}
catch (XmlPullParserException ex) {
System.err.println("This is not a validating parser");
return;
}
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
for (int event = parser.next();
event != XmlPullParser.END_DOCUMENT ;
event = parser.next()) ;
// If we get here there are no exceptions
System.out.println(args[0] + " is valid");
}
catch (XmlPullParserException ex) {
System.out.println(args[0] + " is not valid");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
<?xml version="1.0" encoding="ISO-8859-1" stanalone="no"?>
The value of the version attribute is
available as a String from the
http://xmlpull.org/v1/doc/properties.html#xmldecl-version
property
The value of the standalone attribute is
available as a Boolean from the
http://xmlpull.org/v1/doc/features.html#xmldecl-standalone
property
The actual encoding is returned by the
getInputEncoding() method of
XmlPullParser.
Namespace support is turned off by default:
By default, xmlns and xmlns:prefix attributes are reported
as regular attributes
Turn on namespace support by setting the http://xmlpull.org/v1/doc/features.html#process-namespaces feature to true
In this case, xmlns and xmlns:prefix attributes are not reported
unless http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes is also set to true.
The require() method asserts that the current event has a certain type, local name,
and namespace URI:
public void require(int type,
String namespaceURI,
String localName)
throws XmlPullParserException,
IOException
If the event does not have the right name and URI and XmlPullParserException is thrown.
You can pass null for the local name or namespace URI, to match any local name/namespace URI..
This is useful for in-process validation.
package org.xmlpull.v1;
public class XmlPullParserFactory {
public static final String PROPERTY_NAME =
"org.xmlpull.v1.XmlPullParserFactory";
public void setFeature(String name, boolean state)
throws XmlPullParserException;
public boolean getFeature (String name);
public void setNamespaceAware(boolean awareness);
public boolean isNamespaceAware();
public void setValidating(boolean validating) ;
public boolean isValidating();
public XmlPullParser newPullParser()
throws XmlPullParserException;
public static XmlPullParserFactory newInstance()
throws XmlPullParserException;
public static XmlPullParserFactory newInstance(String classNames, Class context)
throws XmlPullParserException;
}
package org.xmlpull.v1;
public interface XmlPullParser {
public final static String NO_NAMESPACE = "";
public final static int START_DOCUMENT;
public final static int END_DOCUMENT;
public final static int START_TAG;
public final static int END_TAG;
public final static int TEXT;
public final static int CDSECT;
public final static int ENTITY_REF;
public final static int IGNORABLE_WHITESPACE;
public final static int PROCESSING_INSTRUCTION;
public final static int COMMENT;
public final static int DOCDECL;
public final static String [] TYPES = {
"START_DOCUMENT",
"END_DOCUMENT",
"START_TAG",
"END_TAG",
"TEXT",
"CDSECT",
"ENTITY_REF",
"IGNORABLE_WHITESPACE",
"PROCESSING_INSTRUCTION",
"COMMENT",
"DOCDECL"
};
public final static String FEATURE_PROCESS_NAMESPACES =
"http://xmlpull.org/v1/doc/features.html#process-namespaces";
public final static String FEATURE_REPORT_NAMESPACE_ATTRIBUTES =
"http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes";
public final static String FEATURE_PROCESS_DOCDECL =
"http://xmlpull.org/v1/doc/features.html#process-docdecl";
public final static String FEATURE_VALIDATION =
"http://xmlpull.org/v1/doc/features.html#validation";
public void setFeature(String name, boolean state)
throws XmlPullParserException;
public boolean getFeature(String name);
public void setProperty(String name, Object value)
throws XmlPullParserException;
public Object getProperty(String name);
public void setInput(Reader in) throws XmlPullParserException;
public void setInput(InputStream inputStream, String inputEncoding)
throws XmlPullParserException;
// actual parsing methods
public int getEventType()
throws XmlPullParserException;
public int next()
throws XmlPullParserException, IOException;
public int nextToken()
throws XmlPullParserException, IOException;
// Utility methods
public void require(int type, String namespace, String name)
throws XmlPullParserException, IOException;
public String nextText() throws XmlPullParserException, IOException;
public int nextTag() throws XmlPullParserException, IOException;
public String getInputEncoding();
public void defineEntityReplacementText( String entityName,
String replacementText ) throws XmlPullParserException;
public int getNamespaceCount(int depth)
throws XmlPullParserException;
public String getNamespacePrefix(int position) throws XmlPullParserException;
public String getNamespaceUri(int position) throws XmlPullParserException;
public String getNamespace(String prefix);
public int getDepth();
public String getPositionDescription();
public int getLineNumber();
public int getColumnNumber();
// Text methods
public boolean isWhitespace() throws XmlPullParserException;
public String getText();
public char[] getTextCharacters(int[] holderForStartAndLength);
// Tag methods
public String getNamespace();
public String getName();
public String getPrefix();
public boolean isEmptyElementTag() throws XmlPullParserException;
// Attribute methods
public int getAttributeCount();
public String getAttributeNamespace(int index);
public String getAttributePrefix(int index);
public String getAttributeType(int index);
public boolean isAttributeDefault(int index);
public String getAttributeValue(int index);
public String getAttributeValue(String namespace, String name);
}
package org.xmlpull.v1;
public class XmlPullParserException extends Exception {
public XmlPullParserException(String message);
public XmlPullParserException(String message, Throwable throwble) ;
public XmlPullParserException(String message, int row, int column);
public XmlPullParserException(String message, XmlPullParser parser, Throwable chain);
public Throwable getDetail();
public void printStackTrace();
}
An event based API for creating XML documents
Instances are created by XmlPullParserFactory.newSerializer() factory method:
XmlSerializer serializer = XmlPullParserFactory.newSerializer(System.out);
Still under development
package org.xmlpull.v1;
public interface XmlSerializer {
public void setFeature(String name, boolean state)
throws IllegalArgumentException, IllegalStateException;
public boolean getFeature(String name);
public void setProperty(String name, Object value)
throws IllegalArgumentException, IllegalStateException;
public Object getProperty(String name);
public void setOutput(OutputStream out, String encoding)
throws IOException, IllegalArgumentException, IllegalStateException;
public void setOutput(Writer out)
throws IOException, IllegalArgumentException, IllegalStateException;
public void startDocument(String encoding, Boolean standalone)
throws IOException, IllegalArgumentException, IllegalStateException;
public void endDocument()
throws IOException, IllegalArgumentException, IllegalStateException;
public void setPrefix(String prefix, String namespace)
throws IOException, IllegalArgumentException, IllegalStateException;
public String getPrefix(String namespace, boolean generatePrefix)
throws IllegalArgumentException;
public int getDepth();
public String getNamespace();
public String getName();
public XmlSerializer startTag(String namespace, String name)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer attribute(String namespace, String name, String value)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer endTag(String namespace, String name)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer text(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer text(char [] buf, int start, int len)
throws IOException, IllegalArgumentException, IllegalStateException;
public void cdsect(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void entityRef(String text) throws IOException,
IllegalArgumentException, IllegalStateException;
public void processingInstruction(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void comment(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void docdecl(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void ignorableWhitespace(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void flush() throws IOException;
}
Goal: Convert a RDDL document to pure XHTML.
RDDL is
just an XHTML Basic document in which there's one extra element:
rddl:resource
which can appear anywhere a p
element can appear, and can contain anything a
div element can contain.
The customary rddl prefix is mapped to the
http://www.rddl.org/ namespace URL:
<rddl:resource id="rec-xhtml"
xlink:title="W3C REC XHTML"
xlink:role="http://www.w3.org/1999/xhtml"
xlink:arcrole="http://www.rddl.org/purposes#reference"
xlink:href="http://www.w3.org/tr/xhtml1"
>
<li><a href="http://www.w3.org/tr/xhtml1">W3C XHTML 1.0</a></li>
</rddl:resource>The program needs to throw away the
<rddl:resource> start-tag and </rddl:resource>
end-tag while leaving everything else intact.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class RDDLStripper {
public final static String RDDL_NS = "http://www.rddl.org/";
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java RDDLStripper url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser parser = factory.newPullParser();
XmlSerializer serializer = factory.newSerializer();
serializer.setOutput(System.out, "ISO-8859-1");
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
String namespaceURI = parser.getNamespace();
if (!namespaceURI.equals(RDDL_NS)) {
String prefix = parser.getPrefix();
if (prefix == null) prefix = "";
if (namespaceURI != null) {
serializer.setPrefix(prefix, namespaceURI);
}
serializer.startTag(namespaceURI, parser.getName());
// add attributes
for (int i = 0; i < parser.getAttributeCount(); i++) {
serializer.attribute(
parser.getAttributeNamespace(i),
parser.getAttributeName(i),
parser.getAttributeValue(i)
);
// How to define attribute prefixes????
}
}
}
else if (event == XmlPullParser.END_TAG) {
String namespaceURI = parser.getNamespace();
if (!namespaceURI.equals(RDDL_NS)) {
serializer.endTag(namespaceURI, parser.getName());
}
}
else if (event == XmlPullParser.TEXT) {
serializer.text(parser.getText());
}
else if (event == XmlPullParser.CDSECT) {
serializer.cdsect(parser.getText());
}
else if (event == XmlPullParser.COMMENT) {
serializer.comment(parser.getText());
}
else if (event == XmlPullParser.DOCDECL) {
serializer.docdecl(parser.getText());
}
else if (event == XmlPullParser.ENTITY_REF) {
serializer.entityRef(parser.getName());
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
serializer.ignorableWhitespace(parser.getText());
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
serializer.processingInstruction(parser.getText());
}
else if (event == XmlPullParser.TEXT) {
serializer.text(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
serializer.flush();
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Makes certain kinds of programs really easy:
Filter out certain kinds of nodes
Filter out certain tags
Convert processing instructions to elements
Comment reader
Change names of elements
Add attributes to elements
Changes have to be local to be easy:
Start-tag changes based on name, namespace, and attributes
End-tag changes based on name and namespace
Event changes based on that event only
No direct filtering support
I don't know whether these programs are realistic patterns or just common tutorial examples
Too few classes; on the flip side too much is forced into the
XmlPullParser class.
Does not take advantage of polymorphism
Int type codes
Namespace support is turned off by default
DOCTYPE is sporadic and unreliable; may be getting better
Part of Andy Clark's CyberNeko Tools for the Xerces Native Interface (XNI):
NekoPull was invented for two reasons: to fix the inadequacies the author sees in other pull-parsing designs; and to add native pull-parsing capability to Xerces2.
Not yet true pull parsing; layered on top of a push parser
Apache license
Not round trippable
Uses Event Classes instead of int type constants
The base class is XMLEvent:
package org.cyberneko.pull;
public class XMLEvent {
public static final short DOCUMENT = 0;
public static final short ELEMENT = 1;
public static final short CHARACTERS = 2;
public static final short PREFIX_MAPPING = 3;
public static final short GENERAL_ENTITY = 4;
public static final short COMMENT = 5;
public static final short PROCESSING_INSTRUCTION = 6;
public static final short CDATA = 7;
public static final short TEXT_DECL = 8;
public static final short DOCTYPE_DECL = 9;
public final short type;
public Augmentations augs;
public XMLEvent next;
public XMLEvent(short type);
}
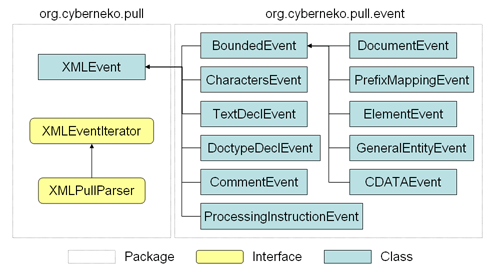
BoundedEvent have beginnings and ends:
CDATAEvent
DocumentEvent
ElementEvent
GeneralEntityEvent
PrefixMappingEvent
CharactersEvent
CommentEvent
DoctypeDeclEvent
ProcessingInstructionEvent
TextDeclEvent
XMLPullParser class represents the parser
Loaded by a subclass constructor:
XMLPullParser parser = new org.cyberneko.pull.parsers.Xerces2();
The document is read from an
org.apache.xerces.xni.parser.XMLInputSource:
XMLInputSource source = new XMLInputSource(publicID, systemID, baseSystemID);
parser.setInputSource(source);The parser's nextEvent() method returns the next XMLEvent:
public XMLEvent nextEvent() throws XNIException, IOException
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoChecker {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoChecker url" );
return;
}
try {
XMLPullParser parser = new Xerces2();;
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
// read entire document
while (parser.nextEvent() != null) ;
// If we get here there are no exceptions
System.out.println(args[0] + " is well-formed");
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an " + ex.getClass().getName());
ex.printStackTrace();
}
}
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoLister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();;
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
switch (event.type) {
case XMLEvent.ELEMENT:
System.out.println("Element");
break;
case XMLEvent.DOCUMENT:
System.out.println("Document");
break;
case XMLEvent.CHARACTERS:
System.out.println("Characters");
break;
case XMLEvent.PREFIX_MAPPING:
System.out.println("Prefix mapping");
break;
case XMLEvent.GENERAL_ENTITY:
System.out.println("General Entity");
break;
case XMLEvent.PROCESSING_INSTRUCTION:
System.out.println("Processing instruction");
break;
case XMLEvent.CDATA:
System.out.println("CDATA section");
break;
case XMLEvent.TEXT_DECL:
System.out.println("Text declaration");
break;
case XMLEvent.DOCTYPE_DECL:
System.out.println("Document type declaration");
break;
default:
System.out.println("Unexpected event");
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an " + ex.getClass().getName());
ex.printStackTrace();
}
}
}
Bounded events have both starts and ends, with various other events in the middle:
CDATAEvent
DocumentEvent
ElementEvent
GeneralEntityEvent
PrefixMappingEvent
The public start field is true if this event is the start of the element/document/entity/etc.
The public start field is false if this event is the end of the element/document/entity/etc.
package org.cyberneko.pull.event;
public abstract class BoundedEvent extends XMLEvent {
public boolean start;
protected BoundedEvent(short type);
}
The name is an org.apache.xerces.xni.QName:
Empty elements have both a start and an end event; however,
the boolean empty field is set to true
The attributes are reported as
an org.apache.xerces.xni.Attributes object:
package org.cyberneko.pull.event;
public class ElementEvent extends BoundedEvent {
public QName element;
public XMLAttributes attributes;
public boolean empty;
public ElementEvent();
}
Used for element and attribute names
package org.apache.xerces.xni;
public class QName implements Cloneable {
public String prefix;
public String localpart;
public String rawname;
public String uri;
public QName();
public QName(String prefix, String localpart, String rawname, String uri);
public QName(QName qname);
public void setValues(QName qname);
public void setValues(String prefix, String localpart, String rawname, String uri);
public void clear();
public Object clone();
public int hashCode();
public boolean equals(Object object);
public String toString();
}
The org.apache.xerces.xni.XMLString contains the text
Not necessarily maximum number of characters (like SAX)
The boolean
ignorable field is true if this is ignorable white space.
package org.cyberneko.pull.event;
public class CharactersEvent extends XMLEvent {
public XMLString text;
public boolean ignorable;
public CharactersEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoRSSLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoRSSLister url");
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
boolean inTitle = false
while ((event = parser.nextEvent()) != null) {
switch (event.type) {
case XMLEvent.ELEMENT:
ElementEvent element = (ElementEvent) event;
String name = element.QName.localpart;
if (name.equals("title") && element.QName.uri == null) {
if (element.start) inTitle = true;
else inTitle = false;
}
break;
case XMLEvent.CHARACTERS:
if (inTitle) {
CharactersEvent text = (CharactersEvent) event;
System.out.println(text.text);
}
break;
case XMLEvent.CDATA:
if (inTitle) {
CDATAEvent text = (CDATAEvent) event;
System.out.println(text.text);
}
break;
default:
// do nothing
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
An org.apache.xerces.xni.XMLAttributes object
is set as the value of the attributes field of each
start ElementEvent object.
package org.apache.xerces.xni;
public interface XMLAttributes {
public int getLength();
public int getIndex(String qualifiedName);
public int getIndex(String uri, String localPart);
public void setName(int index, QName name);
public void getName(int index, QName name);
public String getPrefix(int index);
public String getURI(int index);
public String getLocalName(int index);
public String getQName(int index);
public void setValue(int index, String value);
public String getValue(int index);
public String getValue(String qualifiedName);
public String getValue(String uri, String localName);
public void setNonNormalizedValue(int index, String value);
public String getNonNormalizedValue(int index);
public void setType(int index, String type);
public String getType(int index);
public String getType(String qualifiedName);
public String getType(String uri, String localName);
public void setSpecified(int index, boolean specified);
public boolean isSpecified(int index);
public int addAttribute(QName name, String type, String value);
public void removeAllAttributes();
public void removeAttributeAt(int index);
public Augmentations getAugmentations (int attributeIndex);
public Augmentations getAugmentations (String uri, String localPart);
public Augmentations getAugmentations(String qualifiedName);
}
import org.apache.xerces.xni.*;
import org.apache.xerces.xni.parser.XMLInputSource;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.net.*;
import java.io.*;
import java.util.*;
public class NekoSpider {
// Need to keep track of where we've been
// so we don't get stuck in an infinite loop
private List spideredURIs = new Vector();
// This linked list keeps track of where we're going.
// Although the LinkedList class does not guarantee queue like
// access, I always access it in a first-in/first-out fashion.
private LinkedList queue = new LinkedList();
private URL currentURL;
private XMLPullParser parser;
public NekoSpider() {
this.parser = new Xerces2();
}
private void processStartTag(ElementEvent element) {
XMLAttributes attributes = element.attributes;
String type = attributes.getValue("http://www.w3.org/1999/xlink", "type");
if (type != null) {
String href = attributes.getValue("http://www.w3.org/1999/xlink", "href");
if (href != null) {
try {
URL foundURL = new URL(currentURL, href);
if (!spideredURIs.contains(foundURL)) {
queue.addFirst(foundURL);
}
}
catch (MalformedURLException ex) {
// skip it
}
}
}
}
public void spider(URL uri) {
System.out.println("Spidering " + uri);
try {
XMLInputSource source
= new XMLInputSource(null, uri.toExternalForm(), null);
parser.setInputSource(source);
spideredURIs.add(uri);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.ELEMENT) {
ElementEvent element = (ElementEvent) event;
if (element.start) processStartTag(element);
}
} // end for
while (!queue.isEmpty()) {
URL nextURL = (URL) queue.removeLast();
spider(nextURL);
}
}
catch (Exception ex) {
// skip this document
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.err.println("Usage: java NekoSpider url" );
return;
}
NekoSpider spider = new NekoSpider();
spider.spider(new URL(args[0]));
} // end main
} // end NekoSpider
The public locator field contains an
org.apache.xerces.xni.XMLLocator object for reporting positions within the document.
The public encoding field contains the actual encoding of
the document.
package org.cyberneko.pull.event;
public class DocumentEvent extends BoundedEvent {
public XMLLocator locator;
public String encoding;
public DocumentEvent();
}
The public target field contains a
String object for the processing instruction's target.
The public data field contains a
String object for the processing instruction's data.
package org.cyberneko.pull.event;
public class ProcessingInstructionEvent extends XMLEvent {
public String target;
public XMLString data;
public ProcessingInstructionEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoPILister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoPILister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.PROCESSING_INSTRUCTION) {
ProcessingInstructionEvent instruction
= (ProcessingInstructionEvent) event;
System.out.println("Target: " + instruction.target);
System.out.println("Data: " + instruction.data);
System.out.println();
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
The public
text field is an org.apache.xerces.xni.XMLString containing the content
of the comment.
package org.cyberneko.pull.event;
public class CommentEvent extends XMLEvent {
public XMLString text;
public CommentEvent();
} // class CommentEvent
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoCommentReader {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoCommentReader url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.COMMENT) {
CommentEvent comment = (CommentEvent) event;
System.out.println(comment.text);
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
Used for both text declarations and XML declarations.
The public boolean
xmldecl field determines which; true for an XML declaration,
false for a text declaration
package org.cyberneko.pull.event;
public class TextDeclEvent extends XMLEvent {
public boolean xmldecl;
public String version;
public String encoding;
public String standalone;
public TextDeclEvent();
}
Starts or ends a namespace prefix mapping
The default namespace has an empty string for a prefix
package org.cyberneko.pull.event;
public class PrefixMappingEvent extends BoundedEvent {
public String prefix;
public String uri;
public PrefixMappingEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class PrefixLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PrefixLister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.PREFIX_MAPPING) {
PrefixMappingEvent mapping = (PrefixMappingEvent) event;
System.out.println("Prefix: " + mapping.prefix);
System.out.println("URI: " + mapping.uri);
System.out.println();
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
Reports the beginning or end of a non-predefined???? general entity
package org.cyberneko.pull.event;
public class GeneralEntityEvent extends BoundedEvent {
public String name;
public String pubid;
public String basesysid;
public String literalsysid;
public String expandedsysid;
public String encoding;
public GeneralEntityEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class EntityLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java EntityLister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.GENERAL_ENTITY) {
GeneralEntityEvent entity = (GeneralEntityEvent) event;
if (entity.start) {
System.out.println("Name: " + entity.name);
System.out.println("Public ID: " + entity.pubid);
System.out.println("Base System ID: " + entity.basesysid);
System.out.println("Literal System ID: " + entity.literalsysid);
System.out.println("Expanded System ID: " + entity.expandedsysid);
System.out.println("Encoding: " + entity.encoding);
System.out.println();
}
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
package org.cyberneko.pull;
public interface XMLPullParser
extends XMLEventIterator, XMLComponentManager {
public void setInputSource(XMLInputSource inputSource)
throws XMLConfigurationException, IOException;
public void cleanup();
public void setErrorHandler(XMLErrorHandler errorHandler);
public XMLErrorHandler getErrorHandler();
public void setEntityResolver(XMLEntityResolver entityResolver);
public XMLEntityResolver getEntityResolver();
public void setLocale(Locale locale) throws XNIException;
public Locale getLocale();
public boolean getFeature(String featureId)
throws XMLConfigurationException;
public void setFeature(String featureId, boolean state)
throws XMLConfigurationException;
public void setProperty(String propertyId, Object value)
throws XMLConfigurationException;
public Object getProperty(String propertyId)
throws XMLConfigurationException;
public XMLEvent nextEvent() throws XNIException, IOException;
}
Streaming API for XML
javax.xml.stream.
JSR-173, proposed by BEA Systems:
Two recently proposed JSRs, JAXB and JAX-RPC, highlight the need for an XML Streaming API. Both data binding and remote procedure calling (RPC) require processing of XML as a stream of events, where the current context of the XML defines subsequent processing of the XML. A streaming API makes this type of code much more natural to write than SAX, and much more efficient than DOM.
Goals:
Develop APIs and conventions that allow a user to programmatically pull parse events from an XML input stream.
Develop APIs that allow a user to write events to an XML output stream.
Develop a set of objects and interfaces that encapsulate the information contained in an XML stream.
The specification should be easy to use, efficient, and not require a grammar. It should include support for namespaces, and associated XML constructs. The specification will make reasonable efforts to define APIs that are "pluggable".
Expert Group:
Christopher Fry BEA Systems
James Clark
Stefan Haustein
Aleksander Slominski
James Strachan
K Karun, Oracle Corporation
Gregory Messner, The Breeze Factor
Anil Vijendran, Sun Microsystems
This presentation: http://www.cafeconleche.org/slides/sd2002east/xmlpull
The XMLPULL API: http://www.xml.com/pub/a/2002/08/14/xmlpull.html
Who's Jon Johansen? http://www.eff.org/IP/DeCSS_prosecutions/Johansen_DeCSS_case/
"XML documents on the run, Part 3", Dennis M. Sosnoski: http://www.javaworld.com/javaworld/jw-04-2002/jw-0426-xmljava3.html