 XML in a Nutshell, second edition
XML in a Nutshell, second edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2002
ISBN 0-596-00292-0
 XML Bible, second edition
XML Bible, second edition
Elliotte Rusty Harold
Hungry Minds, 2001
ISBN 0-7645-4760-7
Part I: XML Overview
Part II: What is XML Good For?
Part III: Processing XML
XML succeeded, and in ways that weren't expected - at least not by many. Originally it was conceived as a document-oriented technology for robust quality publishing of documents over networks. the original workplan had three pillars - XML syntax, XML link, and XML stylesheets. Schemas were not high on the agenda and XML was not seen as an infrastructure for middleware or glueware. It was expected that at some stage it would be necessary to manage data but there was little activity in this area in 1997. When developing Chemical Markup Language (which must be one of the first published XML applications), I found the lack of datatypes very frustrating!
Well, XML is now a basic infrastructure of much modern information. I doubt that anyone now designs a protocol, or operating system without including XML. Although this list sometimes complains that XML isn't as clean as we would like, it works, and it works pretty well.
--Peter Murray-Rust on the xml-dev mailing list, Thursday, February 7, 2002
Extensible Markup Language
A syntax for documents
A Meta-Markup Language
A Structural and Semantic language, not a formatting language
Not just for Web pages
Not like HTML, troff, LaTeX
Make up the tags you need as you need them
The tags you create can be documented in a Document Type Definition (DTD)
A meta syntax for domain-specific markup languages like MusicML, MathML, and CML
XML documents form a tree
Element and attribute names reflect the kind of the element
Formatting can be added with a style sheet
<dt>Hot Cop
<dd> by Jacques Morali, Henri Belolo, and Victor Willis
<ul>
<li>Jacques Morali
<li>PolyGram Records
<li>6:20
<li>1978
<li>Village People
</ul>
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
At the top of the document, you normally find an XML declaration:
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
version attribute
required
always has the value 1.0
standalone attribute
yes
no
encoding attribute
UTF-8
ISO-8859-1
etc.
Documents are composed of elements
An element is delimited by a start-tag and a matching end-tag:
<COMPOSER>Jacques Morali</COMPOSER>
Start-tag <COMPOSER>
Contents "Jacques Morali"
End-tag </COMPOSER>
Elements can contain other elements:
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
A simple and straight-forward language for applying styles like bold and Helvetica to particular XML elements.
Rather than being stored as part of the document itself, all the style information is placed in a separate document called a style sheet.
Partially supported by Mozilla, Netscape 6, IE 5.0/5.5, and Opera 4.0/5.0
Full W3C Recommendation
SONG {display: block}
TITLE {display: block; font-family: Helvetica, sans-serif;
font-size: 20pt; font-weight: bold}
COMPOSER {display: block;
font-family: Times, Times New Roman, serif;
font-size: 14pt;
font-style: italic}
ARTIST {display: block;
font-family: Times, Times New Roman, serif;
font-size: 14pt; font-weight: bold;
font-style: italic}
PUBLISHER {display: block;
font-family: Times, Times New Roman, serif;
font-size: 14pt}
LENGTH {display: block;
font-family: Times, Times New Roman, serif;
font-size: 14pt}
YEAR {display: block;
font-family: Times, Times New Roman, serif;
font-size: 14pt}
<?xml version="1.0"?>
<?xml-stylesheet type="text/css" href="song1.css"?>
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="SONG">
<html>
<body>
<h1>
<xsl:value-of select="TITLE"/>
by the
<xsl:value-of select="ARTIST"/>
</h1>
<ul>
<xsl:apply-templates select="COMPOSER"/>
<li>Publisher: <xsl:value-of select="PUBLISHER"/></li>
<li>Year: <xsl:value-of select="YEAR"/></li>
<li>Producer: <xsl:value-of select="PRODUCER"/></li>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="COMPOSER">
<li>Composer: <xsl:value-of select="."/></li>
</xsl:template>
</xsl:stylesheet>Browser support is weak but improving.
Can use third party tools like Xalan, Saxon, and XT
Let's use Saxon to apply this stylesheet to compositions.xml.
Windows executable:
C:\> saxon hotcop.xml song.xsl>hotcop.html
Java executable:
C:\> java com.icl.saxon.StyleSheet hotcop.xml song.xsl>hotcop.html
<html>
<body>
<h1>Hot Cop
by the
Village People
</h1>
<ul>
<li>Composer: Jacques Morali</li>
<li>Composer: Henri Belolo</li>
<li>Composer: Victor Willis</li>
<li>Publisher: PolyGram Records</li>
<li>Year: 1978</li>
<li>Producer: Jacques Morali</li>
</ul>
</body>
</html>Plain ASCII or UTF-8 text
.xml is standard file extension
Any standard text editor will work
Rules:
Open and close all tags
Empty-element tags end with />
There is a unique root element
Elements may not overlap
Attribute values are quoted
< and & are
only used to start tags and entity references
Only the five predefined entity references are used
Plus more...
To be valid an XML document must be
Well-formed
Must have a Document Type Definition (DTD)
Must comply with the constraints specified in the DTD
<!ELEMENT SONG (TITLE, COMPOSER+, PRODUCER*, PUBLISHER*,
LENGTH?, YEAR?, ARTIST+)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT ARTIST (#PCDATA)><?xml version="1.0"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>To check validity you pass the document through a validating parser which should report any errors it finds. For example,
% java dom.Counter -v invalidhotcop.xml [Error] invalidhotcop.xml:10:8: The content of element type "SONG" must match "(TITLE,COMPOSER+,PRODUCER*,PUBLISHER*,LENGTH?,YEAR?,ARTIST+)". invalidhotcop.xml: 862;70;0 ms (7 elems, 0 attrs, 19 spaces, 59 chars)
A valid document:
% java dom.Counter -v validhotcop.xml validhotcop.xml: 671;70;0 ms (10 elems, 0 attrs, 28 spaces, 98 chars)
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="song.css"?>
<!DOCTYPE SONG SYSTEM "expanded_song.dtd">
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<!-- You can tell what album I was
listening to when I wrote this example -->
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200" />
name="value" same as in HTML
Generally used for meta-information
Attribute values are quoted with either single or double quotes:
Good:
<A HREF="http://www.cafeconleche.org/">
<DIV ALIGN='CENTER'>
<A HREF="http://www.cafeconleche.org/">
<EMBED SRC="minnesotaswale.aif" hidden="true">
Bad:
<A HREF=http://www.cafeconleche.org/>
<DIV ALIGN=CENTER>
<EMBED SRC=minnesotaswale.aif hidden=true>
<EMBED SRC="minnesotaswale.aif" hidden>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200" />
Ends with /> instead of >
<PHOTO/> is semantically the same as <PHOTO></PHOTO>
Just syntax sugar
<!-- You can tell what album I was
listening to when I wrote this example -->
Essentially the same as in HTML
Let you mix and match different XML vocabularies
URIs identify elements and attributes that belong to different XML applications
Prefixes can change if the URI stay the same
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<ARTIST>Village People</ARTIST>
</SONG>
A & M Records
< and & are only used to start tags and entities
Good:
<H1>O'Reilly & Associates</H1>
Bad:
<H1>O'Reilly & Associates</H1>
Good:
<CODE>for (int i = 0; i <= args.length; i++ ) { </CODE>
Bad:
<CODE>for (int i = 0; i <= args.length; i++ ) { </CODE>
Only the five predefined entity references are used
Good:
&
<
>
"
'
Bad:
©
®
&tm;
α
é
etc.
Entity references must end with a semicolon.
< is good
< is bad
<!ELEMENT SONG (TITLE, PHOTO?, COMPOSER+, PRODUCER*,
PUBLISHER*, LENGTH?, YEAR?, ARTIST+)>
<!ATTLIST SONG xmlns CDATA #REQUIRED
xmlns:xlink CDATA #REQUIRED>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT PHOTO EMPTY>
<!ATTLIST PHOTO xlink:type CDATA #FIXED "simple"
xlink:href CDATA #REQUIRED
xlink:show CDATA #IMPLIED
ALT CDATA #REQUIRED
WIDTH CDATA #REQUIRED
HEIGHT CDATA #REQUIRED
>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ATTLIST PUBLISHER xlink:type CDATA #IMPLIED
xlink:href CDATA #IMPLIED
>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT ARTIST (#PCDATA)>
Domain-Specific (Vertical) Markup Languages
Self-Describing Data
Interchange of Data Among Applications
Structured and Integrated Data
Markup language for a vertical market
Non-proprietary format
Don't pay for what you don't use
Much data is lost due to format problems
XML is very simple
XML is self-describing
XML is well documented
<PERSON ID="p1100" SEX="M">
<NAME>
<GIVEN>Judson</GIVEN>
<SURNAME>McDaniel</SURNAME>
</NAME>
<BIRTH>
<DATE>21 Feb 1834</DATE>
</BIRTH>
<DEATH>
<DATE>9 Dec 1905</DATE>
</DEATH>
</PERSON>
E-commerce
Syndication
EAI and EDI
A document can be assembled from multiple physical storage entities
These may be files, database queries, or anything that can be referred to by a URI
Can even include non-XML content
A specific markup language that uses the XML meta-syntax is called an XML application
Different XML applications have their own more constricted syntaxes and vocabularies within the broader XML syntax
Further syntax can be layered on top of this; e.g. data typing through schemas
Web Pages
Mathematical Equations
Music Notation
Vector Graphics
and more...
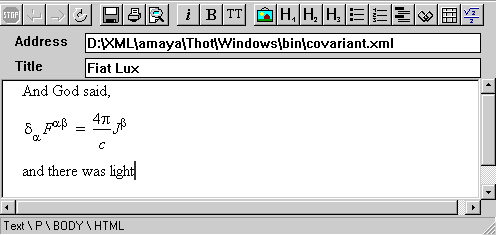
<?xml version="1.0"?>
<html>
<head>
<title>Fiat Lux</title>
<meta name="GENERATOR" content="amaya V1.3b" />
</head>
<body>
<p>
And God said,
</p>
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mrow>
<msub>
<mi>δ</mi>
<mi>α</mi>
</msub>
<msup>
<mi>F</mi>
<mi>αβ</mi>
</msup>
<mo>=</mo>
<mfrac>
<mrow>
<mn>4</mn>
<mi>π</mi>
</mrow>
<mi>c</mi>
</mfrac>
<msup>
<mi>J</mi>
<mrow>
<mi>β</mi>
</mrow>
</msup>
</mrow>
</math>
<p>
and there was light.
</p>
</body>
</html>
<?xml version="1.0"?>
<CHANNEL HREF="http://www.cafeconleche.org/index.html">
<TITLE>Cafe con Leche</TITLE>
<ITEM HREF="http://www.cafeconleche.org/books.html">
<TITLE>Books about XML</TITLE>
</ITEM>
<ITEM HREF="http://www.cafeconleche.org/tradeshows.html">
<TITLE>Trade shows and conferences about XML</TITLE>
</ITEM>
<ITEM HREF="http://www.cafeconleche.org/lists.htm">
<TITLE>Mailing Lists dedicated to XML</TITLE>
</ITEM>
</CHANNEL>
Joseph Conrad's Heart of Darkness
The entire Project Gutenberg corpus
Vector Markup Language (VML)
Internet Explorer 5.0, 5.5
Microsoft Office 2000
Scalable Vector Graphics (SVG)
Adobe SVG Plug-In
Apache Batik
XSL: The Extensible Stylesheet Language
XLink: The Extensible Linking Language
Data typing in XML is weak
DTDs use a strange non-XML syntax
Limited compatibility with namespaces
Limited extensibility
Schemas fix all these problems
There are multiple schema languages including:
Rick Jelliffe's Schematron
Murato Makoto's and James Clark's RELAX NG
The W3C XML Schema Language
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="SONG" type="SongType"/>
<xsd:complexType name="SongType">
<xsd:sequence>
<xsd:element name="TITLE" type="xsd:string"
minOccurs="1" maxOccurs="1"/>
<xsd:element name="COMPOSER" type="xsd:string"
minOccurs="1" maxOccurs="unbounded"/>
<xsd:element name="PRODUCER" type="xsd:string"
minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="PUBLISHER" type="xsd:string"
minOccurs="0" maxOccurs="1"/>
<xsd:element name="LENGTH" type="xsd:duration"
minOccurs="0" maxOccurs="1"/>
<xsd:element name="YEAR" type="xsd:gYear"
minOccurs="1" maxOccurs="1"/>
<xsd:element name="ARTIST" type="xsd:string"
minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>Any element can be a link
Links can be bi-directional
Links can be separated from the documents they connect
<footnote xlink:type="simple" xlink:href="footnote7.xml">7</footnote>
Microsoft Office 2000
Netscape What's Related
Java works best
C#, C++, C, Perl, Python etc. can also be used
Unicode support is the biggest issue
SAX
DOM
JDOM
Parser specific APIs
Public domain, developed on xml-dev mailing list
Currently maintained by David Brownwell
org.xml.sax package
Parser independent; programs can plug in different parsers
Event based; the parser pushes data to your handler
Read-only
SAX omits DTD declarations
Adds:
Namespace support
Optional Validation
Optional Lexical events for comments, CDATA sections, entity references
A lot more configurable
Deprecates a lot of SAX1
Adapter classes convert between SAX2 and SAX1 parsers.
Build a parser-specific implementation of the
XMLReader interface using XMLReaderFactory
Your code registers a ContentHandler with the parser
An InputSource feeds the document into the parser
As the document is read, the parser calls back to the
methods of the methods of the ContentHandler to tell it
what it's seeing in the document.
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.io.*;
public class SAX2Checker {
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java SAX2Checker URL1 URL2...");
}
// set up the parser
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
try {
parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e2) {
System.err.println("Error: could not locate a parser.");
return;
}
}
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.parse(args[i]);
// If there are no well-formedness errors
// then no exception is thrown
System.out.println(args[i] + " is well formed.");
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not check " + args[i]
+ " because of the IOException " + e);
}
}
}
}package org.xml.sax;
public interface ContentHandler {
public void setDocumentLocator(Locator locator);
public void startDocument() throws SAXException;
public void endDocument() throws SAXException;
public void startPrefixMapping(String prefix, String uri)
throws SAXException;
public void endPrefixMapping(String prefix) throws SAXException;
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException;
public void endElement(String namespaceURI, String localName,
String rawName) throws SAXException;
public void characters(char[] text, int start, int length)
throws SAXException;
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException;
public void processingInstruction(String target, String data)
throws SAXException;
public void skippedEntity(String name) throws SAXException;
}import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.IOException;
import java.util.StringTokenizer;
public class SAXWordCount implements ContentHandler {
private int numWords;
public void startDocument() throws SAXException {
this.numWords = 0;
}
public void endDocument() throws SAXException {
System.out.println(numWords + " words");
System.out.flush();
}
private StringBuffer sb = new StringBuffer();
public void characters(char[] text, int start, int length)
throws SAXException {
sb.append(text, start, length);
}
private void flush() {
numWords += countWords(sb.toString());
sb = new StringBuffer();
}
// methods that signify a word break
public void startElement(String namespaceURI, String localName,
String rawName, Attributes atts) throws SAXException {
this.flush();
}
public void endElement(String namespaceURI, String localName,
String rawName) throws SAXException {
this.flush();
}
public void processingInstruction(String target, String data)
throws SAXException {
this.flush();
}
// methods that aren't necessary in this example
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
// ignore;
}
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException {
// ignore;
}
public void endPrefixMapping(String prefix) throws SAXException {
// ignore;
}
public void skippedEntity(String name) throws SAXException {
// ignore;
}
public void setDocumentLocator(Locator locator) {}
private static int countWords(String s) {
if (s == null) return 0;
s = s.trim();
if (s.length() == 0) return 0;
StringTokenizer st = new StringTokenizer(s);
return st.countTokens();
}
public static void main(String[] args) {
SAXParser parser = new SAXParser();
SAXWordCount counter = new SAXWordCount();
parser.setContentHandler(counter);
for (int i = 0; i < args.length; i++) {
try {
parser.parse(args[i]);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}% java SAXWordCount hotcop.xml 16 words
You do not always have all the information you need at the time of a given callback
You may need to store information in various data structures (stacks, queues,vectors, arrays, etc.) and act on it at a later point
For example, the characters() method is not guaranteed
to give you the maximum number of contiguous characters. It may
split a single run of characters over multiple method calls.
Defines how XML and HTML documents are represented as objects in programs
Defined in IDL; thus language independent
HTML as well as XML
Writing as well as reading
More complete than SAX or JDOM; covers everything except internal and external DTD subsets
DOM focuses more on the document; SAX focuses more on the parser.
Parser independent interfaces; parser dependent implementation classes. Most programs must use the parser dependent classes. JAXP helps solve this, but so far only for DOM Level 1.
Everything's a Node:
Extensive use of polymorphism
Lots of casting
Language independence means there's very limited use of the Java class library; Various features are reinvented
Language independence requires no method overloading because not all languages support it.
Several features are poor design in Java, if not in other languages:
Named constants are often shorts
Only one kind of exception; details provided by constants
No Java-specific utility methods
like equals(), hashCode(), clone(), or
toString()
DOM Level 0
DOM Level 1, a W3C Standard
DOM Level 2, a W3C Standard
DOM Level 3, several W3C Working Drafts
Eight Modules:
Core: org.w3c.dom *
HTML: org.w3c.dom.html
Views: org.w3c.dom.views
StyleSheets: org.w3c.dom.stylesheets
CSS: org.w3c.dom.css
Events: org.w3c.dom.events *
Traversal: org.w3c.dom.traversal *
Range: org.w3c.dom.range
Only the core and traversal modules really apply to XML. The other six are for HTML.
* indicates Xerces support
Each XML document is a tree.
A tree contains nodes.
Some nodes may contain other nodes (depending on node type).
Each document node contains:
zero or one doctype nodes
one root element node
zero or more comment and processing instruction nodes
17 interfaces:
Attr
CDATASection
CharacterData
Comment
Document
DocumentFragment
DocumentType
DOMImplementation
Element
Entity
EntityReference
NamedNodeMap
Node
NodeList
Notation
ProcessingInstruction
Text
plus one exception:
DOMException
Plus a bunch of HTML stuff in org.w3c.dom.html
and other packages
Library specific code creates a parser
The parser parses the document and returns an
org.w3c.dom.Document object.
The entire document is stored in memory.
DOM methods and interfaces are used to extract data from this object
import org.apache.xerces.parsers.DOMParser;
import org.xml.sax.SAXException;
import java.io.IOException;
import org.w3c.dom.*;
public class DOMChecker {
public static void main(String[] args) {
// This is simpler but less flexible than the SAX approach.
// Perhaps a good creational design pattern is needed here?
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document d = parser.getDocument();
// work with the document...
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
}
}import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.IOException;
import java.util.StringTokenizer;
public class DOMWordCount {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
DOMWordCount counter = new DOMWordCount();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document d = parser.getDocument();
int numWords = countWordsInNode(d);
System.out.println(numWords + " words");
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
// note use of recursion
public static int countWordsInNode(Node node) {
int numWords = 0;
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
numWords += countWordsInNode(children.item(i));
}
}
int type = node.getNodeType();
if (type == Node.TEXT_NODE) {
String s = node.getNodeValue();
numWords += countWordsInString(s);
}
return numWords;
}
private static int countWordsInString(String s) {
if (s == null) return 0;
s = s.trim();
if (s.length() == 0) return 0;
StringTokenizer st = new StringTokenizer(s);
return st.countTokens();
}
}% java DOMWordCount hotcop.xml 16 words
More Java like tree-based API
Parser independent classes sit on top of parsers and other APIs
Construct an org.jdom.input.SAXBuilder or an
org.jdom.input.DOMBuilder
Invoke the builder's build() method to
build a Document object from a
Reader
InputStream
URL
File
SYSTEM ID String
If there's a problem building the document, a JDOMException is thrown
Work with the resulting Document object
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import java.io.IOException;
public class JDOMChecker {
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java JDOMChecker URL1 URL2...");
}
SAXBuilder builder = new SAXBuilder();
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
builder.build(args[i]);
// If there are no well-formedness errors,
// then no exception is thrown
System.out.println(args[i] + " is well formed.");
}
catch (JDOMException ex) { // indicates a well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(ex.getMessage());
}
catch (IOException ex) { // indicates an I/O error
System.out.println("Could not read " + args[i] + " due to an I/O error.");
System.out.println(ex.getMessage());
}
}
}
}% java JDOMChecker shortlogs.xml HelloJDOM.java shortlogs.xml is well formed. HelloJDOM.java is not well formed. The markup in the document preceding the root element must be well-formed.: Error on line 1 of XML document: The markup in the document preceding the root element must be well-formed.
import org.jdom.*;
import org.jdom.input.SAXBuilder;
import java.util.*;
import java.io.IOException;
public class JDOMWordCount {
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java JDOMWordCount URL");
}
SAXBuilder builder = new SAXBuilder();
// command line should offer URIs or file names
try {
Document doc = builder.build(args[0]);
Element root = doc.getRootElement();
int numWords = countWordsInElement(root);
System.out.println(numWords + " words");
}
catch (JDOMException ex) { // indicates a well-formedness error
System.out.println(args[0] + " is not well formed.");
System.out.println(ex.getMessage());
}
catch (IOException ex) { // indicates an I/O error
System.out.println("Could not read " + args[0] + " due to an I/O error.");
System.out.println(ex.getMessage());
}
}
public static int countWordsInElement(Element element) {
int numWords = 0;
List children = element.getContent();
Iterator iterator = children.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Text) {
numWords += countWordsInString((Text) o);
}
else if (o instanceof Element) {
// note use of recursion
numWords += countWordsInElement((Element) o);
}
}
return numWords;
}
private static int countWordsInString(Text text) {
String s = text.getText();
if (s == null) return 0;
s = s.trim();
if (s.length() == 0) return 0;
StringTokenizer st = new StringTokenizer(s);
return st.countTokens();
}
}% java JDOMWordCount hotcop.xml 16 words
XML is not a database, or a replacement for one.
Out of the box, XML doesn't know anything SQL; SQL doesn't know anything aobut XML.
But XML works very well with databases
You generally have to provide the integration code yourself, but this is not hard.
There are some third-party products and database add-ons that will do a lot of the work for you.
Two approaches:
Store the document as a field
Store pieces of the document as fields
There are a lot of products that will pull data out of a database and format it as XML:
Stonebroom's ASP2XML
Transparency's Beanstalk
IBM's DatabaseDom
infoteria's iConnector
IBM's DB2 XML Extender
FileMaker Web Companion
Oracle XML SQL Utility for Java
etc.
Or roll your own:
Java + JDBC
PHP
ASP
Visual Basic
etc.
XML is a very convenient format to move data between systems
It's all text; very platform independent.
Field and record boundaries are very clear
Schemas and DTDs can prevent you from accepting bad data
XML in a Nutshell, second edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2002
ISBN 0-596-00292-0
XML Bible, second edition
Elliotte Rusty Harold
Hungry Minds, 2001
ISBN 0-7645-4760-7