
XML Infoset
Writing XML with Java
Reading XML through SAX2
Reading and Writing XML through the DOM
JDOM
XMLPull
XOM
TrAX
You need a JDK
You need some free class libraries
You need a text editor
You need some data to process
Are familiar with Java including I/O, classes, objects, polymorphism, etc.
Know XML including well-formedness, validity, namespaces, and so forth
I will briefly review proper terminology
Push: SAX, XNI
Tree: DOM, JDOM, XOM, ElectricXML, dom4j, Sparta
Data binding: Castor, Zeus, JAXB
Pull: XMLPULL, StAX, NekoPull
Transform: XSLT, TrAX, XQuery
SAX, the Simple API for XML
SAX1
SAX2
DOM, the Document Object Model
DOM Level 0
DOM Level 1
DOM Level 2
DOM Level 3
JDOM
dom4j
XOM
TrAX
XMLPULL
NekoPull
Proprietary APIs
Parser specific APIs
Sun's Java API for XML Parsing = SAX1 + DOM1 + a few factory classes
JSR-000031 XML Data Binding Specification from Bluestone, Sun, webMethods et al.
The proposed specification will define an XML data-binding facility for the JavaTM Platform. Such a facility compiles an XML schema into one or more Java classes. These automatically-generated classes handle the translation between XML documents that follow the schema and interrelated instances of the derived classes. They also ensure that the constraints expressed in the schema are maintained as instances of the classes are manipulated.
The Infoset is the unfortunate standard to which those in retreat from the radical and most useful implications of well-formedness have rallied. At its core the Infoset insists that there is 'more' to XML than the straightforward syntax of well-formedness. By imposing its canonical semantics the Infoset obviates the infinite other semantic outcomes which might be elaborated in particular unique circumstances from an instance of well-formed XML 1.0 syntax. The question we should be asking is not whether the Infoset has chosen the correct canonical semantics, but whether the syntactic possibilities of XML 1.0 should be curtailed in this way at all.--Walter Perry on the xml-dev mailing list
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="song.css"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<!-- You can tell what album I was
listening to when I wrote this example -->
Markup includes:
Tags
Entity References
Comments
Processing Instructions
Document Type Declarations
XML Declaration
CDATA Section Delimiters
Character data includes everything else
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="song.css"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<!-- You can tell what album I was
listening to when I wrote this example -->
Elements are delimited by a start-tag like
<LENGTH> and a matching end-tag
like </LENGTH>:
<LENGTH>6:20</LENGTH>
Elements contain content which can be text, child elements, or both:
<LENGTH>6:20</LENGTH>
<PRODUCER>
<NAME><GIVEN>Jacques</GIVEN> <FAMILY>Morali</FAMILY></NAME>
</PRODUCER>
<PARAGRAPH>
The <ARTIST>Village People</ARTIST>
were a popular <GENRE>Disco</GENRE> band in the 1970's
</PARAGRAPH>The element is the tags plus the content.
Empty-element tags both start and end an element:
<PHOTO/>
<PHOTO></PHOTO>
Elements can have attributes:
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
An XML document is made up of one or more physical storage units called entities
Entity references:
Parsed internal general entity references like &
Parsed external general entity references
Unparsed external general entity references
External parameter entity references
Internal parameter entity references
Reading an XML document is not the same thing as reading an XML file
The file contains entity references.
The document contains the entities' replacement text.
When you use a parser to read a document you'll get the text including characters like <. You will not see the entity references.
Character data left after entity references are replaced with their text
Given the element
<PUBLISHER>A & M Records</PUBLISHER>
The parsed character data is
A & M Records
Used to include large blocks of text with lots of normally
illegal literal characters like
< and &, typically XML or HTML.
<p>You can use a default <code>xmlns</code>
attribute to avoid having to add the svg prefix to all
your elements:</p>
<![CDATA[
<svg xmlns="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<ellipse rx="110" ry="130" />
<rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg>
]]>
CDATA is for human authors, not for programs!
<!-- Before posting this page, I need to double check the number
of pelicans in Lousiana in 1970 -->
Comments are for humans, not programs.
Divided into a target and data for the target
The target must be an XML name
The data can have an effectively arbitrary format
<?robots index="yes" follow="no"?>
<?xml-stylesheet href="pelicans.css" type="text/css"?>
<?php
mysql_connect("database.unc.edu", "clerk", "password");
$result = mysql("CYNW", "SELECT LastName, FirstName FROM Employees
ORDER BY LastName, FirstName");
$i = 0;
while ($i < mysql_numrows ($result)) {
$fields = mysql_fetch_row($result);
echo "<person>$fields[1] $fields[0] </person>\r\n";
$i++;
}
mysql_close();
?>
These are for programs
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
Looks like a processing instruction but isn't.
version attribute
required
always has the value 1.0
encoding attribute
UTF-8
ISO-8859-1
SJIS
etc.
standalone attribute
yes
no
<!DOCTYPE SONG SYSTEM "song.dtd">
<!ELEMENT SONG (TITLE, PHOTO?, COMPOSER+, PRODUCER*,
PUBLISHER*, LENGTH?, YEAR?, ARTIST+)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT ARTIST (#PCDATA)>
<!ELEMENT PHOTO EMPTY>
<!ATTLIST PHOTO xlink:type (simple) #FIXED "simple"
xlink:show (onLoad) #FIXED "onLoad"
xlink:href CDATA #REQUIRED
ALT CDATA #REQUIRED
WIDTH NMTOKEN #REQUIRED
HEIGHT NMTOKEN #REQUIRED
>
<!ATTLIST PUBLISHER xlink:type (simple) #FIXED "simple"
xlink:href CDATA #REQUIRED
>
<!ATTLIST SONG xmlns CDATA #FIXED "http://www.cafeconleche.org/namespace/song"
xmlns:xlink CDATA #FIXED "http://www.w3.org/1999/xlink"
>
Used for element, attribute, and entity names
Can contain any Unicode 2.0 alphabetic, ideographic, or numeric Unicode character
Can contain hyphen, underscore, or period
Can also contain colons but these are reserved for namespaces
Can begin with any Unicode 2.0 alphabetic or ideographic character or the underscore but not digits or other punctuation marks
Raison d'etre:
To distinguish between elements and attributes from different vocabularies with different meanings.
To group all related elements and attributes together so that a parser can easily recognize them.
Each element is given a prefix
Each prefix (as well as the empty prefix) is associated with a URI
Elements with the same URI are in the same namespace
URIs are purely formal. They do not necessarily point to a page.
Elements and attributes that are in namespaces have names that contain exactly one colon. They look like this:
rdf:description
xlink:type
xsl:template
Everything before the colon is called the prefix
Everything after the colon is called the local part or local name.
The complete name including the colon is called the qualified name or raw name.
Each prefix in a qualified name is associated with a URI.
For example, all elements in XSLT 1.0 style sheets are associated with the http://www.w3.org/1999/XSL/Transform URI.
The customary prefix xsl is a shorthand for the longer URI
http://www.w3.org/1999/XSL/Transform.
You can't use the URI in the element name directly.
Prefixes are bound to namespace URIs by attaching an xmlns:prefix
attribute to the prefixed element or one of its ancestors.
<svg:svg xmlns:svg="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<svg:ellipse rx="110" ry="130" />
<svg:rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg:svg>
Bindings have scope within the element where they're declared.
An SVG processor can recognize all three of these elements as SVG elements because they all have prefixes bound to the particular URI defined by the SVG specification.
Indicate that an unprefixed element and all its unprefixed descendant
elements belong to a particular namespace by attaching an xmlns
attribute with no prefix:
<DATASCHEMA xmlns="http://www.w3.org/2000/P3Pv1">
<DATA name="vehicle.make" type="text" short="Make"
category="preference" size="31"/>
<DATA name="vehicle.model" type="text" short="Model"
category="preference" size="31"/>
<DATA name="vehicle.year" type="number" short="Year"
category="preference" size="4"/>
<DATA name="vehicle.license.state." type="postal." short="State"
category="preference" size="2"/>
<DATA name="vehicle.license.number" type="text"
short="License Plate Number" category="preference" size="12"/>
</DATASCHEMA>
Both the DATASCHEMA and DATA elements are in the
http://www.w3.org/2000/P3Pv1 namespace.
Default namespaces apply only to elements, not to attributes.
Thus in the above example the name,
type, short, category, and size
attributes are not in any namespace.
Unprefixed attributes are never in any namespace.
You can change the default namespace within a particular
element by adding an xmlns attribute to the element.
Namespaces were added to XML 1.0 after the fact, but care was taken to ensure backwards compatibility.
An XML 1.0 parser that does not know about namespaces will most likely not have any troubles reading a document that uses namespaces.
A namespace aware parser also checks to see that all prefixes are mapped to URIs. Otherwise it behaves almost exactly like a non-namespace aware parser.
Other software that sits on top of the raw XML parser, an XSLT engine for example, may treat elements differently depending on what namespace they belong to. However, the XML parser itself mostly doesn't care as long as all well-formedness and namespace constraints are met.
A possible exception occurs in the unlikely event that elements with different prefixes belong to the same namespace or elements with the same prefix belong to different namespaces
Many parsers have the option of whether to report namespace violations so that you can turn namespace processing on or off as you see fit.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="song.css"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<!-- You can tell what album I was
listening to when I wrote this example -->
<?xml-stylesheet type="text/css" href="song.css"?>
<SONG xmlns="http://www.cafeonleche.org/namespace/song" xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO ALT="Victor Willis in Cop Outfit" HEIGHT="200" WIDTH="100" xlink:href="hotcop.jpg" xlink:show="onLoad" xlink:type="simple"></PHOTO>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER xlink:href="http://www.amrecords.com/" xlink:type="simple">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class DOMHotCop {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
try {
parser.parse("http://www.cafeconleche.org/examples/hotcop.xml");
Document d = parser.getDocument();
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
}
Three forms:
The customary form of an XML document
The canonical form of an XML document
The object form of an XML document
Do they contain the same information or not?
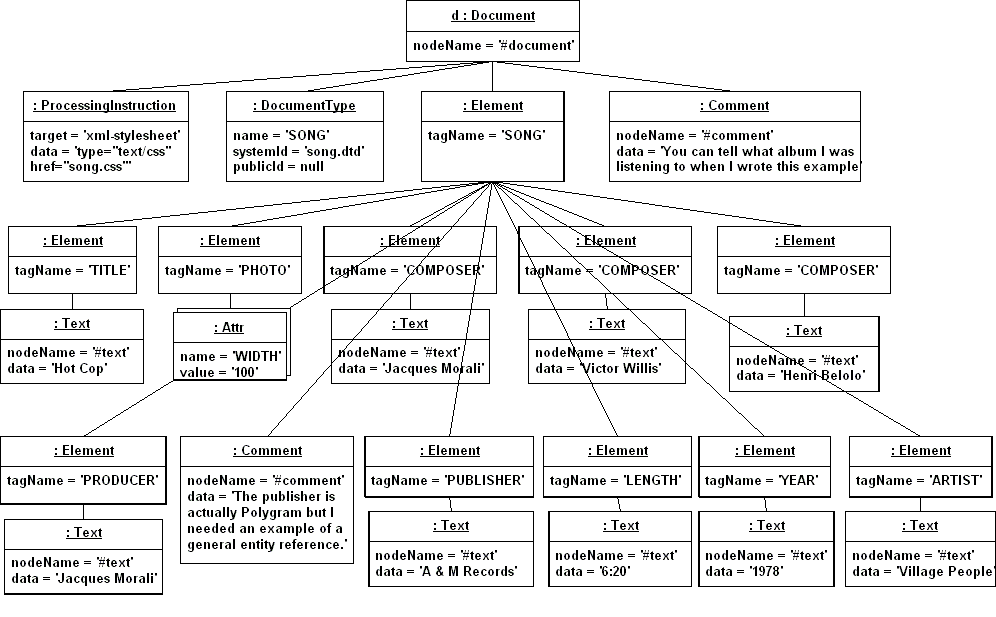
It started out as a A W3C standard for what is and is not significant in an XML document, a description of what information an XML parser must provide to the client application:
An XML processor conforms to the XML Information Set if it provides all the core information items and all their core properties corresponding to that part of the document that the processor has actually read. For instance, attributes are core information items; therefore, an XML processor that does not report the existence of attributes, as well as their names and values (which are core properties of attributes), does not conform to the XML Information Set.
It became a list of definitions for particular information items:
Since the purpose of the Information Set is to provide a set of definitions, conformance is a property of specifications that use those definitions, rather than of implementations.
Specifications referring to the Infoset must:
Indicate the information items and properties that are needed to implement the specification. (This indirectly imposes conformance requirements on processors used to implement the specification.)
Specify how other information items and properties are treated (for example, they might be passed through unchanged).
Note any information required from an XML document that is not defined by the Infoset.
Note any difference in the use of terms defined by the Infoset (this should be avoided).
The Document Information Item
Element Information Items
Attribute Information Items
Processing instruction Information Items
Unexpanded Entity Reference Information Items
Character Information Items
Comment Information Items
The Document Type Declaration Information Item
Unparsed Entity Information Items
Notation Information Items
Namespace Declaration Information Items
Not everyone agrees that this is a good thing! or that this is the right list!
Represents the entire document; not just the root element
Properties:
Children
One Element Information Item for the root element
One Comment Information Item for each Comment
One Processing Instruction Information Item for each Processing Instruction
Notation Declarations
Unparsed Entities
Base URI
Standalone Declaration
Version Declaration
All declarations processed
An Element Information Item Includes:
namespace name
local name
children: a list of element, processing instruction, unexpanded entity reference, character, and comment information items, one for each element, processing instruction, unexpanded entity reference, data character, and comment appearing immediately within the current element
attributes: an unordered set of attribute information items, one for each of the attributes
(specified or defaulted from the DTD) of this element. xmlns attributes
declarations are not include.
declared namespaces: an unordered set of namespace declaration information items, one for each of the namespaces declared either in the start-tag of this element or defaulted from the DTD.
in-scope namespaces: An unordered set of namespace declaration information items, one for each of the namespaces in effect for this element
base URI: The absolute URI of the external entity in which this element appears, as defined in XML Base. If this is not known, this property is null.
parent
xlink:type="simple"
xlink:href="http://www.amrecords.com/"
xlink:type = "simple"
xlink:show = "onLoad"
xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit"
WIDTH=" 100 "
HEIGHT=' 200 '
An Attribute Information Item Includes:
namespace name
local name
normalized value
specified: A flag indicating whether this attribute was actually specified in the start-tag of its element, or was defaulted from the DTD
default: An ordered list of character information items, one for each character appearing in the default value specified for this attribute in the DTD, if any.
attribute type:
ID
IDREF
IDREFS
ENTITY
ENTITIES
NMTOKEN
NMTOKENS
NOTATION
CDATA
ENUMERATED
unknown
undeclared
owner element
references: if the attribute type is IDREF, IDREFS, ENTITY, ENTITIES, or NOTATION, then the value of this property is an ordered list of the element, unparsed entity, or notation information items referred to in the attribute value
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<!-- <PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG> -->
<!-- You can tell what album I was
listening to when I wrote this example -->
A comment Information Item includes:
content
parent
<?robots index="yes" follow="no"?>
<?php
mysql_connect("database.unc.edu", "clerk", "password");
$result = mysql("CYNW", "SELECT LastName, FirstName FROM Employees
ORDER BY LastName, FirstName");
$i = 0;
while ($i < mysql_numrows ($result)) {
$fields = mysql_fetch_row($result);
echo "<person>$fields[1] $fields[0] </person>\r\n";
$i++;
}
mysql_close();
?>
target
content
base URI
parent
notation (named by the target)
A character is one Unicode character in the content of an element, attribute value, comment or processing instruction data.
A Character Information Item includes:
A Namespace Information Item includes:
prefix
namespace name (the namespace URI)
Namespace Information Items are attached to elements, one for each namespace in scope on the element
<!DOCTYPE SONG SYSTEM "song.dtd">
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
A Document Type Declaration Information Item includes:
Each unparsed entity information item includes
name
system identifier
public identifier
declaration base URI
notation name
notation
The internal and external DTD subsets; especially
ELEMENT
and ATTLIST declarations
Whether an empty element uses two tags or one
What kind of quotes surround attributes
Insignificant white space in attributes
White space that occurs between attributes
Attribute order
CDATA sections
Parsed entities
Comments in the DTD
XML InfoSet Specification: http://www.w3.org/TR/xml-infoset
I have learned to be even more skeptical than before about the slew of APIs doing the rounds in the XML development community. An XML instance is just a documents, guys; you need to understand the document structure and document interchange choreography of your systems. Don't let some API get in the way of your understanding of XML systems at the document level. If you do, you run the risk becoming a slave to the APIs and hitting a wall when the APIs fail you.
--Sean McGrath
Read the rest in ITworld.com - XML IN PRACTICE - APIs Considered Harmful
XML documents are text
Any Writer can produce an XML document
XML documents and APIs are Unicode
Unicode encodings:
UTF-8
UTF-16 big endian
UCS-4 big endian
UTF-16 little endian
UCS-4 little endian
Non-Unicode encodings:
ASCII (subset of UTF-8)
MacRoman
Windows ANSI
Latin 1 through Latin 15
SJIS Japanese
Big-5 Chinese
K0I8R Cyrillic
Many others...
Java's InputStreamReader and OutputStreamWriter
classes are very helpful
URL u = new URL(
"http://www.ascc.net/xml/test/wfdtd/utf-8/application_xml/zh-utf8-8.xml");
InputStream in = u.openStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
int c;
while ((c = in.read()) != -1) System.out.write(c);
import java.math.BigInteger;
import java.io.*;
public class FibonacciText {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("fibonacci.txt");
Writer out = new OutputStreamWriter(fout, "8859_1");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
out.write(low.toString() + "\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write(high.toString() + "\r\n");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
1
1
2
3
5
8
13
21
34
55
89
144
233
377
610
987
1597
2584
4181
6765
10946
17711
28657
46368
75025
121393
317811
import java.math.BigInteger;
import java.io.*;
public class FibonacciXML {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("fibonacci.xml");
Writer out = new OutputStreamWriter(fout);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
out.write("<?xml version=\"1.0\"?>\r\n");
out.write("<Fibonacci_Numbers>\r\n");
for (int i = 1; i <= 25; i++) {
out.write(" <fibonacci index=\"" + i + "\">");
out.write(low.toString());
out.write("</fibonacci>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</Fibonacci_Numbers>");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0"?>
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>import java.math.BigInteger;
import java.io.*;
public class FibonacciLatin1 {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("fibonacci_8859_1.xml");
Writer out = new OutputStreamWriter(fout, "8859_1");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
out.write("<?xml version=\"1.0\" encoding=\"8859_1\"?>\r\n");
out.write("<Fibonacci_Numbers>\r\n");
for (int i = 1; i <= 25; i++) {
out.write(" <fibonacci index=\"" + i + "\">");
out.write(low.toString());
out.write("</fibonacci>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</Fibonacci_Numbers>");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0" encoding="8859_1"?>
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>import java.math.BigInteger;
import java.io.*;
public class FibonacciDTD {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("valid_fibonacci.xml");
Writer out = new OutputStreamWriter(fout, "UTF-8");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
out.write("<?xml version=\"1.0\"?>\r\n");
out.write("<!DOCTYPE Fibonacci_Numbers [\r\n");
out.write(" <!ELEMENT Fibonacci_Numbers (fibonacci*)>\r\n");
out.write(" <!ELEMENT fibonacci (#PCDATA)>\r\n");
out.write(" <!ATTLIST fibonacci index CDATA #IMPLIED>\r\n");
out.write("]>\r\n");
out.write("<Fibonacci_Numbers>\r\n");
for (int i = 1; i <= 25; i++) {
out.write(" <fibonacci index=\"" + i + "\">");
out.write(low.toString());
out.write("</fibonacci>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</Fibonacci_Numbers>");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0"?>
<!DOCTYPE Fibonacci_Numbers [
<!ELEMENT Fibonacci_Numbers (fibonacci*)>
<!ELEMENT fibonacci (#PCDATA)>
<!ATTLIST fibonacci index CDATA #IMPLIED>
]>
<Fibonacci_Numbers>
<fibonacci index="0">0</fibonacci>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
</Fibonacci_Numbers>
Surname FirstName Team Position Games Played Games Started AtBats Runs Hits Doubles Triples Home runs RBI Stolen Bases Caught Stealing Sacrifice Hits Sacrifice Flies Errors PB Walks Strike outs Hit by pitch Anderson Garret ANA Outfield 156 151 622 62 183 41 7 15 79 8 3 3 3 6 0 29 80 1 Baughman Justin ANA Second Base 62 54 196 24 50 9 1 1 20 10 4 5 3 8 0 6 36 1 Bolick Frank ANA Third Base 21 11 45 3 7 2 0 1 2 0 0 0 0 0 0 11 8 0 Disarcina Gary ANA Shortstop 157 155 551 73 158 39 3 3 56 12 7 12 3 14 0 21 51 8 Edmonds Jim ANA Outfield 154 150 599 115 184 42 1 25 91 7 5 1 1 5 0 57 114 1 Erstad Darin ANA Outfield 133 129 537 84 159 39 3 19 82 20 6 1 3 3 0 43 77 6 Garcia Carlos ANA Second Base 19 10 35 4 5 1 0 0 0 2 0 1 0 1 0 3 11 1 Glaus Troy ANA Third Base 48 45 165 19 36 9 0 1 23 1 0 0 2 7 0 15 51 0 Greene Todd ANA Outfield 29 15 71 3 18 4 0 1 7 0 0 0 0 0 0 2 20 0 Helfand Eric ANA Catcher 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Hollins Dave ANA Third Base 101 98 363 60 88 16 2 11 39 11 3 2 2 17 0 44 69 7 Jefferies Gregg ANA Outfield 19 18 72 7 25 6 0 1 10 1 0 0 0 0 0 0 5 0 Johnson Mark ANA First Base 10 2 14 1 1 0 0 0 0 0 0 0 0 0 0 0 6 0 Kreuter Chad ANA Catcher 96 74 252 27 63 10 1 2 33 1 0 5 1 9 5 33 49 3 Martin Norberto ANA Second Base 79 50 195 20 42 2 0 1 13 3 1 3 2 4 0 6 29 0 Mashore Damon ANA Outfield 43 24 98 13 23 6 0 2 11 1 0 1 0 0 0 9 22 3 Molina Ben ANA Catcher 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Nevin Phil ANA Catcher 75 65 237 27 54 8 1 8 27 0 0 0 2 5 20 17 67 5 Obrien Charlie ANA Catcher 62 58 175 13 45 9 0 4 18 0 0 3 3 4 1 10 33 2 Palmeiro Orlando ANA Outfield 74 34 165 28 53 7 2 0 21 5 4 7 0 0 0 20 11 0 Pritchett Chris ANA First Base 31 19 80 12 23 2 1 2 8 2 0 0 0 1 0 4 16 0 Salmon Tim ANA Designated Hitter 136 130 463 84 139 28 1 26 88 0 1 0 10 2 0 90 100 3 Shipley Craig ANA Third Base 77 32 147 18 38 7 1 2 17 0 4 4 1 3 0 5 22 5 Velarde Randy ANA Second Base 51 50 188 29 49 13 1 4 26 7 2 0 1 4 0 34 42 1 Walbeck Matt ANA Catcher 108 91 338 41 87 15 2 6 46 1 1 5 5 7 8 30 68 2 Williams Reggie ANA Outfield 29 7 36 7 13 1 0 1 5 3 3 1 0 0 0 7 11 1
import java.io.*;
public class BaseballTabToXML {
public static void main(String[] args) {
try {
FileInputStream fin = new FileInputStream(args[0]);
BufferedReader in
= new BufferedReader(new InputStreamReader(fin));
FileOutputStream fout
= new FileOutputStream("baseballstats.xml");
Writer out = new OutputStreamWriter(fout, "UTF-8");
out.write("<?xml version=\"1.0\"?>\r\n");
out.write("<players>\r\n");
String playerStats;
while ((playerStats = in.readLine()) != null) {
String[] stats = splitLine(playerStats);
out.write(" <player>\r\n");
out.write(" <first_name>" + stats[1] + "</first_name>\r\n");
out.write(" <surname>" + stats[0] + "</surname>\r\n");
out.write(" <games_played>" + stats[4] + "</games_played>\r\n");
out.write(" <at_bats>" + stats[6] + "</at_bats>\r\n");
out.write(" <runs>" + stats[7] + "</runs>\r\n");
out.write(" <hits>" + stats[8] + "</hits>\r\n");
out.write(" <doubles>" + stats[9] + "</doubles>\r\n");
out.write(" <triples>" + stats[10] + "</triples>\r\n");
out.write(" <home_runs>" + stats[11] + "</home_runs>\r\n");
out.write(" <stolen_bases>" + stats[12] + "</stolen_bases>\r\n");
out.write(" <caught_stealing>" + stats[14] + "</caught_stealing>\r\n");
out.write(" <sacrifice_hits>" + stats[15] + "</sacrifice_hits>\r\n");
out.write(" <sacrifice_flies>" + stats[16] + "</sacrifice_flies>\r\n");
out.write(" <errors>" + stats[17] + "</errors>\r\n");
out.write(" <passed_by_ball>" + stats[18] + "</passed_by_ball>\r\n");
out.write(" <walks>" + stats[19] + "</walks>\r\n");
out.write(" <strike_outs>" + stats[20] + "</strike_outs>\r\n");
out.write(" <hit_by_pitch>" + stats[21] + "</hit_by_pitch>\r\n");
out.write(" </player>\r\n");
}
out.write("</players>\r\n");
out.close();
in.close();
}
catch (IOException e) {
System.err.println(e);
}
catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Usage: java BaseballTabToXML input_file.tab");
}
}
public static String[] splitLine(String playerStats) {
// count the number of tabs
int numTabs = 0;
for (int i = 0; i < playerStats.length(); i++) {
if (playerStats.charAt(i) == '\t') numTabs++;
}
int numFields = numTabs + 1;
String[] fields = new String[numFields];
int position = 0;
for (int i = 0; i < numFields; i++) {
StringBuffer field = new StringBuffer();
while (position < playerStats.length()
&& playerStats.charAt(position++) != '\t') {
field.append(playerStats.charAt(position-1));
}
fields[i] = field.toString();
}
return fields;
}
}
<?xml version="1.0"?>
<players>
<player>
<first_name>FirstName</first_name>
<surname>Surname</surname>
<games_played>Games Played</games_played>
<at_bats>AtBats</at_bats>
<runs>Runs</runs>
<hits>Hits</hits>
<doubles>Doubles</doubles>
<triples>Triples</triples>
<home_runs>Home runs</home_runs>
<stolen_bases>RBI</stolen_bases>
<caught_stealing>Caught Stealing</caught_stealing>
<sacrifice_hits>Sacrifice Hits</sacrifice_hits>
<sacrifice_flies>Sacrifice Flies</sacrifice_flies>
<errors>Errors</errors>
<passed_by_ball>PB</passed_by_ball>
<walks>Walks</walks>
<strike_outs>Strike outs</strike_outs>
<hit_by_pitch>Hit by pitch</hit_by_pitch>
</player>
<player>
<first_name>Garret </first_name>
<surname>Anderson</surname>
<games_played>156</games_played>
<at_bats>622</at_bats>
<runs>62</runs>
<hits>183</hits>
<doubles>41</doubles>
<triples>7</triples>
<home_runs>15</home_runs>
<stolen_bases>79</stolen_bases>
<caught_stealing>3</caught_stealing>
<sacrifice_hits>3</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>6</errors>
<passed_by_ball>0</passed_by_ball>
<walks>29</walks>
<strike_outs>80</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Justin </first_name>
<surname>Baughman</surname>
<games_played>62</games_played>
<at_bats>196</at_bats>
<runs>24</runs>
<hits>50</hits>
<doubles>9</doubles>
<triples>1</triples>
<home_runs>1</home_runs>
<stolen_bases>20</stolen_bases>
<caught_stealing>4</caught_stealing>
<sacrifice_hits>5</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>8</errors>
<passed_by_ball>0</passed_by_ball>
<walks>6</walks>
<strike_outs>36</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Frank </first_name>
<surname>Bolick</surname>
<games_played>21</games_played>
<at_bats>45</at_bats>
<runs>3</runs>
<hits>7</hits>
<doubles>2</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>2</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>11</walks>
<strike_outs>8</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Gary </first_name>
<surname>Disarcina</surname>
<games_played>157</games_played>
<at_bats>551</at_bats>
<runs>73</runs>
<hits>158</hits>
<doubles>39</doubles>
<triples>3</triples>
<home_runs>3</home_runs>
<stolen_bases>56</stolen_bases>
<caught_stealing>7</caught_stealing>
<sacrifice_hits>12</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>14</errors>
<passed_by_ball>0</passed_by_ball>
<walks>21</walks>
<strike_outs>51</strike_outs>
<hit_by_pitch>8</hit_by_pitch>
</player>
<player>
<first_name>Jim </first_name>
<surname>Edmonds</surname>
<games_played>154</games_played>
<at_bats>599</at_bats>
<runs>115</runs>
<hits>184</hits>
<doubles>42</doubles>
<triples>1</triples>
<home_runs>25</home_runs>
<stolen_bases>91</stolen_bases>
<caught_stealing>5</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>5</errors>
<passed_by_ball>0</passed_by_ball>
<walks>57</walks>
<strike_outs>114</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Darin </first_name>
<surname>Erstad</surname>
<games_played>133</games_played>
<at_bats>537</at_bats>
<runs>84</runs>
<hits>159</hits>
<doubles>39</doubles>
<triples>3</triples>
<home_runs>19</home_runs>
<stolen_bases>82</stolen_bases>
<caught_stealing>6</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>3</errors>
<passed_by_ball>0</passed_by_ball>
<walks>43</walks>
<strike_outs>77</strike_outs>
<hit_by_pitch>6</hit_by_pitch>
</player>
<player>
<first_name>Carlos </first_name>
<surname>Garcia</surname>
<games_played>19</games_played>
<at_bats>35</at_bats>
<runs>4</runs>
<hits>5</hits>
<doubles>1</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>1</errors>
<passed_by_ball>0</passed_by_ball>
<walks>3</walks>
<strike_outs>11</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Troy </first_name>
<surname>Glaus</surname>
<games_played>48</games_played>
<at_bats>165</at_bats>
<runs>19</runs>
<hits>36</hits>
<doubles>9</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>23</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>7</errors>
<passed_by_ball>0</passed_by_ball>
<walks>15</walks>
<strike_outs>51</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Todd </first_name>
<surname>Greene</surname>
<games_played>29</games_played>
<at_bats>71</at_bats>
<runs>3</runs>
<hits>18</hits>
<doubles>4</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>7</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>2</walks>
<strike_outs>20</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Eric </first_name>
<surname>Helfand</surname>
<games_played>0</games_played>
<at_bats>0</at_bats>
<runs>0</runs>
<hits>0</hits>
<doubles>0</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>0</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Dave </first_name>
<surname>Hollins</surname>
<games_played>101</games_played>
<at_bats>363</at_bats>
<runs>60</runs>
<hits>88</hits>
<doubles>16</doubles>
<triples>2</triples>
<home_runs>11</home_runs>
<stolen_bases>39</stolen_bases>
<caught_stealing>3</caught_stealing>
<sacrifice_hits>2</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>17</errors>
<passed_by_ball>0</passed_by_ball>
<walks>44</walks>
<strike_outs>69</strike_outs>
<hit_by_pitch>7</hit_by_pitch>
</player>
<player>
<first_name>Gregg </first_name>
<surname>Jefferies</surname>
<games_played>19</games_played>
<at_bats>72</at_bats>
<runs>7</runs>
<hits>25</hits>
<doubles>6</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>10</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>5</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Mark </first_name>
<surname>Johnson</surname>
<games_played>10</games_played>
<at_bats>14</at_bats>
<runs>1</runs>
<hits>1</hits>
<doubles>0</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>6</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Chad </first_name>
<surname>Kreuter</surname>
<games_played>96</games_played>
<at_bats>252</at_bats>
<runs>27</runs>
<hits>63</hits>
<doubles>10</doubles>
<triples>1</triples>
<home_runs>2</home_runs>
<stolen_bases>33</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>5</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>9</errors>
<passed_by_ball>5</passed_by_ball>
<walks>33</walks>
<strike_outs>49</strike_outs>
<hit_by_pitch>3</hit_by_pitch>
</player>
<player>
<first_name>Norberto </first_name>
<surname>Martin</surname>
<games_played>79</games_played>
<at_bats>195</at_bats>
<runs>20</runs>
<hits>42</hits>
<doubles>2</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>13</stolen_bases>
<caught_stealing>1</caught_stealing>
<sacrifice_hits>3</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>4</errors>
<passed_by_ball>0</passed_by_ball>
<walks>6</walks>
<strike_outs>29</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Damon </first_name>
<surname>Mashore</surname>
<games_played>43</games_played>
<at_bats>98</at_bats>
<runs>13</runs>
<hits>23</hits>
<doubles>6</doubles>
<triples>0</triples>
<home_runs>2</home_runs>
<stolen_bases>11</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>9</walks>
<strike_outs>22</strike_outs>
<hit_by_pitch>3</hit_by_pitch>
</player>
<player>
<first_name>Ben </first_name>
<surname>Molina</surname>
<games_played>2</games_played>
<at_bats>1</at_bats>
<runs>0</runs>
<hits>0</hits>
<doubles>0</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>0</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Phil </first_name>
<surname>Nevin</surname>
<games_played>75</games_played>
<at_bats>237</at_bats>
<runs>27</runs>
<hits>54</hits>
<doubles>8</doubles>
<triples>1</triples>
<home_runs>8</home_runs>
<stolen_bases>27</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>5</errors>
<passed_by_ball>20</passed_by_ball>
<walks>17</walks>
<strike_outs>67</strike_outs>
<hit_by_pitch>5</hit_by_pitch>
</player>
<player>
<first_name>Charlie </first_name>
<surname>Obrien</surname>
<games_played>62</games_played>
<at_bats>175</at_bats>
<runs>13</runs>
<hits>45</hits>
<doubles>9</doubles>
<triples>0</triples>
<home_runs>4</home_runs>
<stolen_bases>18</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>3</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>4</errors>
<passed_by_ball>1</passed_by_ball>
<walks>10</walks>
<strike_outs>33</strike_outs>
<hit_by_pitch>2</hit_by_pitch>
</player>
<player>
<first_name>Orlando </first_name>
<surname>Palmeiro</surname>
<games_played>74</games_played>
<at_bats>165</at_bats>
<runs>28</runs>
<hits>53</hits>
<doubles>7</doubles>
<triples>2</triples>
<home_runs>0</home_runs>
<stolen_bases>21</stolen_bases>
<caught_stealing>4</caught_stealing>
<sacrifice_hits>7</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>20</walks>
<strike_outs>11</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Chris </first_name>
<surname>Pritchett</surname>
<games_played>31</games_played>
<at_bats>80</at_bats>
<runs>12</runs>
<hits>23</hits>
<doubles>2</doubles>
<triples>1</triples>
<home_runs>2</home_runs>
<stolen_bases>8</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>1</errors>
<passed_by_ball>0</passed_by_ball>
<walks>4</walks>
<strike_outs>16</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Tim </first_name>
<surname>Salmon</surname>
<games_played>136</games_played>
<at_bats>463</at_bats>
<runs>84</runs>
<hits>139</hits>
<doubles>28</doubles>
<triples>1</triples>
<home_runs>26</home_runs>
<stolen_bases>88</stolen_bases>
<caught_stealing>1</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>10</sacrifice_flies>
<errors>2</errors>
<passed_by_ball>0</passed_by_ball>
<walks>90</walks>
<strike_outs>100</strike_outs>
<hit_by_pitch>3</hit_by_pitch>
</player>
<player>
<first_name>Craig </first_name>
<surname>Shipley</surname>
<games_played>77</games_played>
<at_bats>147</at_bats>
<runs>18</runs>
<hits>38</hits>
<doubles>7</doubles>
<triples>1</triples>
<home_runs>2</home_runs>
<stolen_bases>17</stolen_bases>
<caught_stealing>4</caught_stealing>
<sacrifice_hits>4</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>3</errors>
<passed_by_ball>0</passed_by_ball>
<walks>5</walks>
<strike_outs>22</strike_outs>
<hit_by_pitch>5</hit_by_pitch>
</player>
<player>
<first_name>Randy </first_name>
<surname>Velarde</surname>
<games_played>51</games_played>
<at_bats>188</at_bats>
<runs>29</runs>
<hits>49</hits>
<doubles>13</doubles>
<triples>1</triples>
<home_runs>4</home_runs>
<stolen_bases>26</stolen_bases>
<caught_stealing>2</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>4</errors>
<passed_by_ball>0</passed_by_ball>
<walks>34</walks>
<strike_outs>42</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Matt </first_name>
<surname>Walbeck</surname>
<games_played>108</games_played>
<at_bats>338</at_bats>
<runs>41</runs>
<hits>87</hits>
<doubles>15</doubles>
<triples>2</triples>
<home_runs>6</home_runs>
<stolen_bases>46</stolen_bases>
<caught_stealing>1</caught_stealing>
<sacrifice_hits>5</sacrifice_hits>
<sacrifice_flies>5</sacrifice_flies>
<errors>7</errors>
<passed_by_ball>8</passed_by_ball>
<walks>30</walks>
<strike_outs>68</strike_outs>
<hit_by_pitch>2</hit_by_pitch>
</player>
<player>
<first_name>Reggie </first_name>
<surname>Williams</surname>
<games_played>29</games_played>
<at_bats>36</at_bats>
<runs>7</runs>
<hits>13</hits>
<doubles>1</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>5</stolen_bases>
<caught_stealing>3</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>7</walks>
<strike_outs>11</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
</players>
import java.io.*;
import java.text.*;
import java.util.*;
public class BattingAverage {
public static void main(String[] args) {
try {
FileInputStream fin = new FileInputStream(args[0]);
BufferedReader in
= new BufferedReader(new InputStreamReader(fin));
FileOutputStream fout
= new FileOutputStream("battingaverages.xml");
Writer out = new OutputStreamWriter(fout, "UTF-8");
out.write("<?xml version=\"1.0\"?>\r\n");
out.write("<players>\r\n");
String playerStats;
// for formatting batting averages
DecimalFormat averages = (DecimalFormat)
NumberFormat.getNumberInstance(Locale.US);
averages.setMaximumFractionDigits(3);
averages.setMinimumFractionDigits(3);
averages.setMinimumIntegerDigits(0);
while ((playerStats = in.readLine()) != null) {
String[] stats = splitLine(playerStats);
String formattedAverage;
try {
int atBats = Integer.parseInt(stats[6]);
int hits = Integer.parseInt(stats[8]);
if (atBats <= 0) formattedAverage = "N/A";
else {
double average = hits / (double) atBats;
formattedAverage = averages.format(average);
}
}
catch (Exception e) {
// skip this player
continue;
}
out.write(" <player>\r\n");
out.write(" <first_name>" + stats[1] + "</first_name>\r\n");
out.write(" <surname>" + stats[0] + "</surname>\r\n");
out.write(" <batting_average>" + formattedAverage
+ "</batting_average>\r\n");
out.write(" </player>\r\n");
}
out.write("</players>\r\n");
out.close();
in.close();
}
catch (IOException e) {
System.err.println(e);
}
catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Usage: java BattingAverage input_file.tab");
}
}
public static String[] splitLine(String playerStats) {
// count the number of tabs
int numTabs = 0;
for (int i = 0; i < playerStats.length(); i++) {
if (playerStats.charAt(i) == '\t') numTabs++;
}
int numFields = numTabs + 1;
String[] fields = new String[numFields];
int position = 0;
for (int i = 0; i < numFields; i++) {
StringBuffer field = new StringBuffer();
while (position < playerStats.length()
&& playerStats.charAt(position++) != '\t') {
field.append(playerStats.charAt(position-1));
}
fields[i] = field.toString();
}
return fields;
}
}
<?xml version="1.0"?>
<players>
<player>
<first_name>Garret </first_name>
<surname>Anderson</surname>
<batting_average>.294</batting_average>
</player>
<player>
<first_name>Justin </first_name>
<surname>Baughman</surname>
<batting_average>.255</batting_average>
</player>
<player>
<first_name>Frank </first_name>
<surname>Bolick</surname>
<batting_average>.156</batting_average>
</player>
<player>
<first_name>Gary </first_name>
<surname>Disarcina</surname>
<batting_average>.287</batting_average>
</player>
<player>
<first_name>Jim </first_name>
<surname>Edmonds</surname>
<batting_average>.307</batting_average>
</player>
<player>
<first_name>Darin </first_name>
<surname>Erstad</surname>
<batting_average>.296</batting_average>
</player>
<player>
<first_name>Carlos </first_name>
<surname>Garcia</surname>
<batting_average>.143</batting_average>
</player>
<player>
<first_name>Troy </first_name>
<surname>Glaus</surname>
<batting_average>.218</batting_average>
</player>
<player>
<first_name>Todd </first_name>
<surname>Greene</surname>
<batting_average>.254</batting_average>
</player>
<player>
<first_name>Eric </first_name>
<surname>Helfand</surname>
<batting_average>N/A</batting_average>
</player>
<player>
<first_name>Dave </first_name>
<surname>Hollins</surname>
<batting_average>.242</batting_average>
</player>
<player>
<first_name>Gregg </first_name>
<surname>Jefferies</surname>
<batting_average>.347</batting_average>
</player>
<player>
<first_name>Mark </first_name>
<surname>Johnson</surname>
<batting_average>.071</batting_average>
</player>
<player>
<first_name>Chad </first_name>
<surname>Kreuter</surname>
<batting_average>.250</batting_average>
</player>
<player>
<first_name>Norberto </first_name>
<surname>Martin</surname>
<batting_average>.215</batting_average>
</player>
<player>
<first_name>Damon </first_name>
<surname>Mashore</surname>
<batting_average>.235</batting_average>
</player>
<player>
<first_name>Ben </first_name>
<surname>Molina</surname>
<batting_average>.000</batting_average>
</player>
<player>
<first_name>Phil </first_name>
<surname>Nevin</surname>
<batting_average>.228</batting_average>
</player>
<player>
<first_name>Charlie </first_name>
<surname>Obrien</surname>
<batting_average>.257</batting_average>
</player>
<player>
<first_name>Orlando </first_name>
<surname>Palmeiro</surname>
<batting_average>.321</batting_average>
</player>
<player>
<first_name>Chris </first_name>
<surname>Pritchett</surname>
<batting_average>.288</batting_average>
</player>
<player>
<first_name>Tim </first_name>
<surname>Salmon</surname>
<batting_average>.300</batting_average>
</player>
<player>
<first_name>Craig </first_name>
<surname>Shipley</surname>
<batting_average>.259</batting_average>
</player>
<player>
<first_name>Randy </first_name>
<surname>Velarde</surname>
<batting_average>.261</batting_average>
</player>
<player>
<first_name>Matt </first_name>
<surname>Walbeck</surname>
<batting_average>.257</batting_average>
</player>
<player>
<first_name>Reggie </first_name>
<surname>Williams</surname>
<batting_average>.361</batting_average>
</player>
</players>
XML files are text files.
You can write XML files any way you can write a text file in Java or any other language for that matter.
You have to follow well-formedness rules.
You do have to use UTF-8 or specify a different encoding in the XML declaration.
Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 3-4
For streams and readers and writers:

Java I/O
Elliotte Rusty Harold
O'Reilly & Associates, 1999
ISBN: 1-56592-485-1
 For well-formedness rules and such:
XML in a Nutshell, 2nd Edition
For well-formedness rules and such:
XML in a Nutshell, 2nd Edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2002
ISBN 0-596-00292-0
Actually, SAX2 has ** MUCH ** better infoset support than DOM does. Yes, I've done the detailed analysis.
--David Brownell on the xml-dev mailing list
The stereotypical "Desperate Perl Hacker" (DPH) is supposed to be able to write an XML parser in a weekend.
The parser does the hard work for you.
Your code reads the document through the parser's API.
Public domain, developed on xml-dev mailing list
Originally maintained by David Megginson
Currently maintained by David Brownell
org.xml.sax package
Event based
| Parser | URL | Validating | Namespaces | DOM1 | DOM2 | SAX1 | SAX2 | License |
|---|---|---|---|---|---|---|---|---|
| Yuval Oren's Piccolo | http://piccolo.sourceforge.net/ | X | X | X | LGPL | |||
| Apache XML Project's Xerces Java | http://xml.apache.org/xerces2-j/index.html | X | X | X | X | X | X | Apache Software License, Version 1.1 |
| IBM's XML for Java | http://www.alphaworks.ibm.com/formula/xml | X | X | X | X | X | X | Apache Software License, Version 1.1 |
| Microstar/David Brownell's Ælfred | http://www.gnu.org/software/classpathx/jaxp/jaxp.html | X | X | X | X | X | GPL with library exception | |
| Silfide's SXP | http://www.loria.fr/projets/XSilfide/EN/sxp/ | X | X | Non-GPL viral open source license | ||||
| Sun's Crimson | http://xml.apache.org/crimson/ | X | X | X | X | Apache | ||
| Oracle's XML Parser for Java | http://technet.oracle.com/ | X | X | X | X | free beer |
SAX1 omits:
Comments
Lexical Information (CDATA sections, entity references, etc.)
DTD declarations
Validation
Namespaces
Adds:
Namespace support
Optional validation
Optional lexical events for comments, CDATA sections, entity references
A lot more configurable
Deprecates a lot of SAX1
Adapter classes convert between parsers.
Use the factory method
XMLReaderFactory.createXMLReader()
to retrieve a parser-specific implementation of the
XMLReader interface
Your code registers a ContentHandler with the parser
An InputSource feeds the document into the parser
As the document is read, the parser calls back to the
methods of the ContentHandler to tell it
what it's seeing in the document.
The XMLReaderFactory.createXMLReader() method
instantiates an XMLReader subclass named by
the org.xml.sax.driver system property:
try {
XMLReader parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
System.err.println(e);
}
The XMLReaderFactory.createXMLReader(String className) method
instantiates an XMLReader subclass named by
its argument:
try {
XMLReader parser
= XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e) {
System.err.println(e);
}
Or you can use the constructor in the package-specific class:
XMLReader parser = new SAXParser();
Or all three:
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException ex2) {
parser = new SAXParser();
}
}
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.io.*;
public class SAX2Checker {
public static void main(String[] args) {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException ex2) {
System.out.println("Could not locate a parser."
+ "Please set the the org.xml.sax.driver property.");
return;
}
}
if (args.length == 0) {
System.out.println("Usage: java SAX2Checker URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.parse(args[i]);
// If there are no well-formedness errors
// then no exception is thrown
System.out.println(args[i] + " is well formed.");
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not check " + args[i]
+ " because of the IOException " + e);
}
}
}
}C:\>java SAX2Checker http://www.cafeconleche.org/
http://www.cafeconleche.org/ is not well formed.
The element type "dt" must be terminated by the
matching end-tag "</dt>".
at line 186, column 5
package org.xml.sax;
public interface ContentHandler {
public void setDocumentLocator(Locator locator);
public void startDocument() throws SAXException;
public void endDocument() throws SAXException;
public void startPrefixMapping(String prefix, String uri)
throws SAXException;
public void endPrefixMapping(String prefix) throws SAXException;
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException;
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException;
public void characters(char[] text, int start, int length)
throws SAXException;
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException;
public void processingInstruction(String target, String data)
throws SAXException;
public void skippedEntity(String name) throws SAXException;
}import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.io.*;
public class EventReporter implements ContentHandler {
public void setDocumentLocator(Locator locator) {
System.out.println("setDocumentLocator(" + locator + ")");
}
public void startDocument() throws SAXException {
System.out.println("startDocument()");
}
public void endDocument() throws SAXException {
System.out.println("endDocument()");
}
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts)
throws SAXException {
namespaceURI = '"' + namespaceURI + '"';
localName = '"' + localName + '"';
qualifiedName = '"' + qualifiedName + '"';
String attributeString = "{";
for (int i = 0; i < atts.getLength(); i++) {
attributeString += atts.getQName(i) + "=\""
+ atts.getValue(i) + "\"";
if (i != atts.getLength()-1) attributeString += ", ";
}
attributeString += "}";
System.out.println("startElement(" + namespaceURI + ", "
+ localName + ", " + qualifiedName + ", " + attributeString + ")");
}
public void endElement(String namespaceURI, String localName,
String qualifiedName)
throws SAXException {
namespaceURI = '"' + namespaceURI + '"';
localName = '"' + localName + '"';
qualifiedName = '"' + qualifiedName + '"';
System.out.println("endElement(" + namespaceURI + ", "
+ localName + ", " + qualifiedName + ")");
}
public void characters(char[] text, int start, int length)
throws SAXException {
String textString = "[" + new String(text) + "]";
System.out.println("characters(" + textString + ", "
+ start + ", " + length + ")");
}
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException {
System.out.println("ignorableWhitespace()");
}
public void processingInstruction(String target, String data)
throws SAXException {
System.out.println("processingInstruction(" + target + ", "
+ data + ")");
}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
System.out.println("startPrefixMapping(\"" + prefix + "\", \""
+ uri + "\")");
}
public void endPrefixMapping(String prefix) throws SAXException {
System.out.println("endPrefixMapping(\"" + prefix + "\")");
}
public void skippedEntity(String name) throws SAXException {
System.out.println("skippedEntity(" + name + ")");
}
// Could easily have put main() method in a separate class
public static void main(String[] args) {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (Exception e) {
// fall back on Xerces parser by name
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (Exception ee) {
System.err.println("Couldn't locate a SAX parser");
return;
}
}
if (args.length == 0) {
System.out.println(
"Usage: java EventReporter URL1 URL2...");
}
// Install the content handler
parser.setContentHandler(new EventReporter());
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.parse(args[i]);
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not report on " + args[i]
+ " because of the IOException " + e);
}
}
}
}
UserLand's RSS based list of Web logs at http://static.userland.com/weblogMonitor/logs.xml:
<?xml version="1.0"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl></imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description></description>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
Design Decisions
Should we return an array, an Enumeration,
a List, or what?
Perhaps we should use multiple threads?
We do not know how many URLs there will be when we start parsing
so let's use a Vector
Single threaded for simplicity but a real program would use multiple threads
One to load and parse the data
Another thread (probably the main thread) to serve the data
Early data could be provided before the entire document had been read
The character data of each url element needs to be stored.
Everything else can be ignored.
A startElement() with the name
url indicates that we need to start
storing this data.
A stopElement() with the name url indicates that we need to stop
storing this data, convert it to a URL and put it in the
Vector
Should we hide the XML parsing inside a non-public class to avoid accidentally calling the methods from unexpected places or threads?
import org.xml.sax.*;
import org.xml.sax.helpers.XMLReaderFactory;
import java.util.*;
import java.io.*;
public class WeblogsSAX {
public static List listChannels()
throws IOException, SAXException {
return listChannels(
"http://static.userland.com/weblogMonitor/logs.xml");
}
public static List listChannels(String uri)
throws IOException, SAXException {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
}
Vector urls = new Vector(1000);
ContentHandler handler = new URIGrabber(urls);
parser.setContentHandler(handler);
parser.parse(uri);
return urls;
}
public static void main(String[] args) {
try {
List urls;
if (args.length > 0) urls = listChannels(args[0]);
else urls = listChannels();
Iterator iterator = urls.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
catch (IOException e) {
System.err.println(e);
}
catch (SAXParseException e) {
System.err.println(e);
System.err.println("at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) {
System.err.println(e);
}
catch (/* Unexpected */ Exception e) {
e.printStackTrace();
}
}
}
import org.xml.sax.*;
import java.net.*;
import java.util.Vector;
// conflicts with java.net.ContentHandler
class URIGrabber implements org.xml.sax.ContentHandler {
private Vector urls;
URIGrabber(Vector urls) {
this.urls = urls;
}
// do nothing methods
public void setDocumentLocator(Locator locator) {}
public void startDocument() throws SAXException {}
public void endDocument() throws SAXException {}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {}
public void endPrefixMapping(String prefix) throws SAXException {}
public void skippedEntity(String name) throws SAXException {}
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException {}
public void processingInstruction(String target, String data)
throws SAXException {}
// Remember, there's no guarantee all the text of the
// url element will be returned in a single call to characters
private StringBuffer urlBuffer;
private boolean collecting = false;
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
if (qualifiedName.equals("url")) {
collecting = true;
urlBuffer = new StringBuffer();
}
}
public void characters(char[] text, int start, int length)
throws SAXException {
if (collecting) {
urlBuffer.append(text, start, length);
}
}
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
if (qualifiedName.equals("url")) {
collecting = false;
String url = urlBuffer.toString();
try {
urls.addElement(new URL(url));
}
catch (MalformedURLException e) {
// skip this url
}
}
}
}% java Weblogs shortlogs.xml
http://www.mozillazine.org
http://www.salonherringwiredfool.com/
http://www.slashdot.org/
SAX2 parsers--that is XMLReaders--are configured by features and properties
Feature and property names are absolute URIs
A feature is boolean, on or off, true or false; a property is an object
public boolean getFeature(String name)
throws SAXNotRecognizedException, SAXNotSupportedException
public void setFeature(String name, boolean value)
throws SAXNotRecognizedException, SAXNotSupportedException
public Object getProperty(String name)
throws SAXNotRecognizedException, SAXNotSupportedException
public void setProperty(String name, Object value)
throws SAXNotRecognizedException, SAXNotSupportedException
Features can be read-only or read/write.
Some features may be modifiable while parsing; others only before parsing starts
For example,
try {
if (xmlReader.getFeature("http://xml.org/sax/features/validation")) {
System.out.println("Parser is validating.");
}
else {
System.out.println("Parser is not validating.");
}
}
catch (SAXException e) {
System.out.println("Do not know if parser validates");
}
SAXNotRecognizedExceptionSAXNotSupportedExceptionhttp://xml.org/sax/features/namespaces
If true, then perform namespace processing.
If false, then, at parser option, do not perform namespace processing
access: (parsing) read-only; (not parsing) read/write
true by default
http://xml.org/sax/features/namespace-prefixes
If true, then report the original prefixed names and attributes used for namespace declarations.
If false, then do not report attributes used for namespace declarations, and optionally do not report original prefixed names.
false by default
access: (parsing) read-only; (not parsing) read/write
http://xml.org/sax/features/namespaces
http://xml.org/sax/features/namespace-prefixes
http://xml.org/sax/features/string-interning
If true, then all element names, prefixes, attribute
names, namespace URIs, and local names are internalized using
java.lang.String.intern().
If false, then names are not necessarily internalized.
access: (parsing) read-only; (not parsing) read/write
http://xml.org/sax/features/validation
If true, then report all validation errors
If false, then do not report validation errors.
access: (parsing) read-only; (not parsing) read/write
http://xml.org/sax/features/external-general-entities
If true, then include all external general (text) entities.
false: Do not include external general entities.
access: (parsing) read-only; (not parsing) read/write
http://xml.org/sax/features/external-parameter-entities
If true, then include all external parameter entities, including the external DTD subset.
false: Do not include any external parameter entities, even the external DTD subset.
access: (parsing) read-only; (not parsing) read/write
adapted from SAX2 documentation by David Megginson
Not all parsers are validating but Xerces-J is.
Validity errors are not fatal; therefore they do not throw SAXParseExceptions
Must install an ErrorHandler as well as a
ContentHandler
Must set the feature http://xml.org/sax/features/validation
In increasing order of severity:
A warning; e.g. ambiguous content model, a constraint for compatibility
A recoverable error: typically a validity error
A fatal error: typically a well-formedness error
package org.xml.sax;
public interface ErrorHandler {
public void warning(SAXParseException exception)
throws SAXException;
public void error(SAXParseException exception)
throws SAXException;
public void fatalError(SAXParseException exception)
throws SAXException;
}
import org.xml.sax.*;
import java.io.*;
public class ValidityErrorReporter implements ErrorHandler {
private Writer out;
public ValidityErrorReporter(Writer out) {
this.out = out;
}
public ValidityErrorReporter() {
this(new OutputStreamWriter(System.out));
}
public void warning(SAXParseException ex)
throws SAXException {
try {
out.write(ex.getMessage() + "\r\n");
out.write(" at line " + ex.getLineNumber() + ", column "
+ ex.getColumnNumber() + "\r\n");
out.flush();
}
catch (IOException e) {
throw new SAXException(e);
}
}
public void error(SAXParseException ex)
throws SAXException {
try {
out.write(ex.getMessage() + "\r\n");
out.write(" at line " + ex.getLineNumber() + ", column "
+ ex.getColumnNumber() + "\r\n");
out.flush();
}
catch (IOException e) {
throw new SAXException(e);
}
}
public void fatalError(SAXParseException ex)
throws SAXException {
try {
out.write(ex.getMessage() + "\r\n");
out.write(" at line " + ex.getLineNumber() + ", column "
+ ex.getColumnNumber() + "\r\n");
out.flush();
}
catch (IOException e) {
throw new SAXException(e);
}
}
}
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.*;
import java.io.*;
public class SAX2Validator {
public static void main(String[] args) {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
}
catch (SAXException ex2) {
System.err.println("Could not locate a SAX2 Parser");
return;
}
}
// turn on validation
try {
parser.setFeature(
"http://xml.org/sax/features/validation", true);
parser.setErrorHandler(new ValidityErrorReporter());
}
catch (SAXNotRecognizedException e) {
System.err.println(
"Installed XML parser cannot validate;"
+ " checking for well-formedness instead...");
}
catch (SAXNotSupportedException e) {
System.err.println(
"Cannot turn on validation here; "
+ "checking for well-formedness instead...");
}
if (args.length == 0) {
System.out.println("Usage: java SAX2Validator URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.parse(args[i]);
// If there are no well-formedness errors,
// then no exception is thrown
System.out.println(args[i] + " is well formed.");
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not check " + args[i]
+ " because of the IOException " + e);
}
}
}
}http://xml.org/sax/properties/lexical-handler
data type:
org.xml.sax.ext.LexicalHandler
description: An optional extension handler for items like comments that are not part of the information set and may be omitted.
access: read/write
http://xml.org/sax/properties/declaration-handler
data type:
org.xml.sax.ext.DeclHandler
description: An optional extension handler for ATTLIST and ELEMENT declarations (but not notations and unparsed entities).
access: read/write
http://xml.org/sax/properties/dom-node
data type: org.w3c.dom.Node
description: When parsing, the current DOM node being visited if this is a DOM iterator; when not parsing, the root DOM node for iteration.
access: (parsing) read-only; (not parsing) read/write
http://xml.org/sax/properties/xml-string
data type: java.lang.String
description: The literal string of characters that was the source for the current event.
access: read-only
adapted from SAX2 documentation by David Megginson
http://apache.org/xml/features/validation/dynamic
True: The parser will validate the document
if a DTD is specified in a DOCTYPE
declaration or using the appropriate
schema attributes like xsi:noNamespaceSchemaLocation.
False: Validation is determined by the state of the http://xml.org/sax/features/validation feature.
Default is false
http://apache.org/xml/features/validation/warn-on-duplicate-attdef
True: Warn on duplicate attribute declaration.
False: Do not warn on duplicate attribute declaration.
Default: true
http://apache.org/xml/features/validation/warn-on-undeclared-elemdef
True: Warn if element referenced in content model is not declared.
False: Do not warn if element referenced in content model is not declared.
Default: true
http://apache.org/xml/features/allow-java-encodings
True: Allow Java encoding names like 8859_1 in XML and text declarations.
False: Do not allow Java encoding names in XML and text declarations.
Default: false
http://apache.org/xml/features/continue-after-fatal-error
True: Continue after fatal error.
False: Stops parse on first fatal error.
Default: false
http://apache.org/xml/features/validation/schema
True: validate against a schema
False: do not use any schemas
Default: false
http://apache.org/xml/features/validation/schema-full-checking
True: perform checking that may be time-consuming or memory intensive.
False: skip some checks
Default: false
http://apache.org/xml/features/validation/schema/normalized-value
True: Normalize element and attribute values according to their schema type
False: don't normalize
Default: false
http://apache.org/xml/features/validation/schema/element-default
True: Provide schema element default values
False: don't report element default values
Default: true
http://apache.org/xml/properties/schema/external-schemaLocationhttp://apache.org/xml/properties/schema/external-noNamespaceSchemaLocation
Extension handlers are non-required interfaces in the
org.xml.sax.ext package.
To set the
LexicalHandler
for an XML reader, set the property
http://xml.org/sax/handlers/LexicalHandler.
To set the
DeclHandler
for an XML reader, set the property
http://xml.org/sax/handlers/DeclHandler.
If the reader does not support the requested property, it will throw a
SAXNotRecognizedException or a SAXNotSupportedException.
The startElement() method in
ContentHandler receives as an argument an
Attributes object containing all attributes
on that tag.
public void startElement(String namespaceURI,
String localName, String qualifiedName, Attributes atts) throws SAXException
The Attributes interface:
package org.xml.sax;
public interface Attributes {
public int getLength();
public String getURI(int index);
public String getLocalName(int index);
public String getQName(int index);
public String getType(int index);
public String getValue(int index);
public int getIndex(String uri, String localName);
public int getIndex(String qualifiedName);
public String getType(String uri, String localName);
public String getType(String qualifiedName);
public String getValue(String uri, String localName);
public String getValue(String qualifiedName);
}import org.xml.sax.*;
import org.apache.xerces.parsers.*;
import java.io.*;
import java.util.*;
import org.xml.sax.helpers.*;
public class XLinkSpider extends DefaultHandler {
public static Enumeration listURIs(String systemId)
throws SAXException, IOException {
// set up the parser
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e2) {
System.err.println("Error: could not locate a parser.");
return null;
}
}
// Install the Content Handler
XLinkSpider spider = new XLinkSpider();
parser.setContentHandler(spider);
parser.parse(systemId);
return spider.uris.elements();
}
private Vector uris = new Vector();
public void startElement(String namespaceURI, String localName,
String rawName, Attributes atts) throws SAXException {
String uri = atts.getValue(
"http://www.w3.org/1999/xlink", "href");
if (uri != null) uris.addElement(uri);
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java XLinkSpider URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
try {
Enumeration uris = listURIs(args[i]);
while (uris.hasMoreElements()) {
String s = (String) uris.nextElement();
System.out.println(s);
}
}
catch (Exception e) {
System.err.println(e);
e.printStackTrace();
}
} // end for
} // end main
} // end XLinkSpiderThe EntityResolver allows you to substitute your own URI
lookup scheme for external entities
Especially useful for entities that use URL and URI schemes not supported by Java's protocol handlers; e.g. jdbc: or isbn:
The EntityResolver interface:
package org.xml.sax;
import java.io.IOException;
public interface EntityResolver {
public InputSource resolveEntity (String publicID,
String systemID) throws SAXException, IOException;
}import org.xml.sax.*;
public class RSSResolver implements EntityResolver {
public InputSource resolveEntity(String publicID, String systemID) {
if ( publicID.equals(
"-//Netscape Communications//DTD RSS 0.91//EN")
|| systemID.equals(
"http://my.netscape.com/publish/formats/rss-0.91.dtd")) {
return new InputSource(
"http://www.cafeconleche.org/dtds/rss.dtd");
}
else {
// use the default behaviour
return null;
}
}
}
The DTDHandler interface covers those aspects of DTDs
a non-validating parser may care about and
that are not handled by other interfaces:
Notation Declarations
Unparsed Entity Declarations
Attribute defaults are handled transparently by startElement() and
the Attributes interface
Parsed entities are handled transparently by ContentHandler
unless you install an EntityResolver
The DTDHandler interface:
package org.xml.sax;
public interface DTDHandler {
public void notationDecl(String name, String publicID,
String systemID) throws SAXException;
public void unparsedEntityDecl(String name, String publicID,
String systemID, String notationName) throws SAXException;
}Program to map unparsed entities with notation "text/plain" to CDATA sections
AttributeHandler will have to make actual replacements
Will finish with XMLFilter
import org.xml.sax.*;
import java.util.*;
import java.net.*;
import java.io.*;
public class TextEntityReplacer implements DTDHandler {
/* This class stores the notation and entity declarations
for a single document. It is not designed to be reused
for multiple parses, though that would be straightforward
extension. The public and system IDs of the document
being parsed are set in the constructor.
*/
private URL systemID;
private String publicID;
public TextEntityReplacer(String publicID, String systemID)
throws MalformedURLException {
this.publicID = publicID;
this.systemID = new URL(systemID);
}
// store all notations in a hashtable. We'll need them later
private Hashtable notations = new Hashtable();
// for the DTDHandler interface
public void notationDecl(String name, String publicID,
String systemID)
throws SAXException {
Notation n = new Notation(name, publicID, systemID);
notations.put(name, n);
}
private class Notation {
String name;
String publicID;
String systemID;
Notation(String name, String publicID, String systemID) {
this.name = name;
this.publicID = publicID;
this.systemID = systemID;
}
}
// store all unparsed entities in a hashtable. We'll need them later
private Hashtable unparsedEntities = new Hashtable();
// for the DTDHandler interface
public void unparsedEntityDecl(String name, String publicID,
String systemID, String notationName) throws SAXException {
UnparsedEntity e = new UnparsedEntity(name, publicID,
systemID, notationName);
unparsedEntities.put(name, e);
}
private class UnparsedEntity {
String name;
String publicID;
String systemID;
String notationName;
UnparsedEntity(String name, String publicID,
String systemID, String notationName) {
this.name = name;
this.notationName = notationName;
this.publicID = publicID;
this.systemID = systemID;
}
}
public boolean isText(String notationName) {
Object o = notations.get(notationName);
if (o == null) return false;
Notation n = (Notation) o;
if (n.systemID.startsWith("text/")) return true;
return false;
}
public String getText(String entityName) throws IOException {
Object o = unparsedEntities.get(entityName);
if (o == null) return "";
UnparsedEntity entity = (UnparsedEntity) o;
if (!isText(entity.notationName)) {
return " binary data "; // could throw an exception instead
}
URL source;
try {
source = new URL(systemID, entity.systemID);
}
catch (Exception e) {
return " unresolvable entity "; // could throw an exception instead
}
// I'm not really handling character encodings here.
// A more detailed look at the MIME media type would allow that.
Reader in = new BufferedReader(
new InputStreamReader(source.openStream())
);
StringBuffer result = new StringBuffer();
int c;
while ((c = in.read()) != -1) {
result.append((char) c);
}
return result.toString();
}
}
The optional
DeclHandler interface covers those aspects of DTDs
only a validating parser cares about:
Element declarations
Attribute declarations
Internal entity declarations
External entity declarations
An optional extension that not all parsers (particularly non-validating parsers) support
To set the DeclHandler for a parser,
set the
"http://xml.org/sax/handlers/DeclHandler" property.
A SAXNotRecognizedException or SAXNotSupportedException will be thrown if the parser
doesn't support DeclHandler
package org.xml.sax.ext;
import org.xml.sax.SAXException;
public interface DeclHandler {
public void elementDecl(String name, String model)
throws SAXException;
public void attributeDecl(String elementName, String attributeName,
String type, String defaultValue, String value)
throws SAXException;
public void internalEntityDecl(String name, String value)
throws SAXException;
public void externalEntityDecl(String name, String publicID,
String systemID) throws SAXException;
}import org.xml.sax.*;
import org.xml.sax.ext.DeclHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.IOException;
public class DTDMerger implements DeclHandler {
public void elementDecl(String name, String model)
throws SAXException {
System.out.println("<!ELEMENT " + name + " " + model + " >");
}
public void attributeDecl(String elementName,
String attributeName, String type, String mode,
String defaultValue) throws SAXException {
System.out.print("<!ATTLIST ");
System.out.print(elementName);
System.out.print(" ");
System.out.print(attributeName);
System.out.print(" ");
System.out.print(type);
System.out.print(" ");
if (mode != null) {
System.out.print(mode + " ");
}
if (defaultValue != null) {
System.out.print('"' + defaultValue + "\" ");
}
System.out.println(">");
}
public void internalEntityDecl(String name,
String value) throws SAXException {
if (!name.startsWith("%")) { // ignore parameter entities
System.out.println("<!ENTITY " + name + " \""
+ value + "\">");
}
}
public void externalEntityDecl(String name,
String publicID, String systemID) throws SAXException {
if (!name.startsWith("%")) { // ignore parameter entities
if (publicID != null) {
System.out.println("<!ENTITY " + name + " PUBLIC \""
+ publicID + "\" \"" + systemID + "\">");
}
else {
System.out.println("<!ENTITY " + name + " SYSTEM \""
+ systemID + "\">");
}
}
}
public static void main(String[] args) {
if (args.length <= 0) {
System.out.println("Usage: java DTDMerger URL");
return;
}
String document = args[0];
XMLReader parser = null;
try {
parser = XMLReaderFactory.createXMLReader();
DeclHandler handler = new DTDMerger();
parser.setProperty(
"http://xml.org/sax/properties/declaration-handler",
handler);
parser.parse(document);
}
catch (SAXNotRecognizedException e) {
System.err.println(parser.getClass()
+ " does not support declaration handlers.");
}
catch (SAXNotSupportedException e) {
System.err.println(parser.getClass()
+ " does not support declaration handlers.");
}
catch (SAXException e) {
System.err.println(e);
// As long as we finished with the DTD we really don't care
}
catch (IOException e) {
System.out.println(
"Due to an IOException, the parser could not check "
+ document
);
}
}
}
The
LexicalHandler interface reports:
Comments
CDATA sections
Document type declaration
Entities
An optional extension that not all parsers support
To set the LexicalHandler for a parser,
set the
"http://xml.org/sax/handlers/LexicalHandler" property.
A SAXNotRecognizedException will be thrown if the parser
doesn't report lexical events.
A SAXNotSupportedException will be thrown if
you pass the wrong object type at the wrong time.
package org.xml.sax.ext;
import org.xml.sax.SAXException;
public interface LexicalHandler {
public void startDTD(String name, String publicID, String systemID)
throws SAXException;
public void endDTD() throws SAXException;
public void startEntity(String name) throws SAXException;
public void endEntity(String name) throws SAXException;
public void startCDATA() throws SAXException;
public void endCDATA() throws SAXException;
public void comment (char[] text, int start, int length)
throws SAXException;
}import org.xml.sax.*;
import org.xml.sax.ext.*;
import org.xml.sax.helpers.*;
import java.io.IOException;
public class SAXCommentReader implements LexicalHandler {
public void startDTD(String name, String publicId, String systemId)
throws SAXException {}
public void endDTD() throws SAXException {}
public void startEntity(String name) throws SAXException {}
public void endEntity(String name) throws SAXException {}
public void startCDATA() throws SAXException {}
public void endCDATA() throws SAXException {}
public void comment (char[] text, int start, int length)
throws SAXException {
String comment = new String(text, start, length);
System.out.println(comment);
}
public static void main(String[] args) {
// set up the parser
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e2) {
System.err.println("Error: could not locate a parser.");
return;
}
}
// turn on comment handling
try {
parser.setProperty(
"http://xml.org/sax/properties/lexical-handler",
new SAXCommentReader()
);
}
catch (SAXNotRecognizedException e) {
System.err.println(
"Installed XML parser does not provide lexical events...");
return;
}
catch (SAXNotSupportedException e) {
System.err.println(
"Cannot turn on comment processing here");
return;
}
if (args.length == 0) {
System.out.println("Usage: java SAXCommentReader URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
try {
parser.parse(args[i]);
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not check " + args[i]
+ " because of the IOException " + e);
}
}
}
}C:\EXAMPLES>java SAXCommentReader hotcop.xml
This should be a four digit year like "1999",
not a two-digit year like "99"
The publisher is actually Polygram but I needed
an example of a general entity reference.
You can tell what album I was
listening to when I wrote this example
Or try http://www.w3.org/TR/2000/REC-xml-20001006.xml
Tells the callback class where in the document (line number, column number) a particular event took place
Optional but recommended
Parsers give the callback class a Locator
by passing it to the setDocumentLocator()
method of ContentHandler
The Locator interface:
package org.xml.sax;
public interface Locator {
public String getPublicId();
public String getSystemId();
public int getLineNumber();
public int getColumnNumber();
}import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.*;
import java.io.*;
public class LocationReporter implements ContentHandler {
private Locator locator = null;
public void setDocumentLocator(Locator locator) {
this.locator = locator;
}
private String reportPosition() {
if (locator != null) {
String publicID = locator.getPublicId();
String systemID = locator.getSystemId();
int line = locator.getLineNumber();
int column = locator.getColumnNumber();
String name;
if (publicID != null) name = publicID;
else name = systemID;
return " in " + name + " at line " + line
+ ", column " + column;
}
return "";
}
public void startDocument() throws SAXException {
System.out.println("Document started" + reportPosition());
}
public void endDocument() throws SAXException {
System.out.println("Document ended" + reportPosition());
}
public void characters(char[] text, int start, int length)
throws SAXException {
System.out.println("Got some characters" + reportPosition());
}
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException {
System.out.println("Got some ignorable white space"
+ reportPosition());
}
public void processingInstruction(String target, String data)
throws SAXException {
System.out.println("Got a processing instruction"
+ reportPosition());
}
// Changed methods for SAX2
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
System.out.println("Element " + qualifiedName + " started"
+ reportPosition());
}
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
System.out.println("Element " + qualifiedName + " ended"
+ reportPosition());
}
// new methods for SAX2
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
System.out.println("Started mapping prefix " + prefix
+ " to URI " + uri + reportPosition());
}
public void endPrefixMapping(String prefix) throws SAXException {
System.out.println("Stopped mapping prefix "
+ prefix + reportPosition());
}
public void skippedEntity(String name) throws SAXException {
System.out.println("Skipped entity " + name + reportPosition());
}
// Could easily have put main() method in a separate class
public static void main(String[] args) {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e2) {
System.err.println("Error: no parser found!");
return;
}
}
if (args.length == 0) {
System.out.println(
"Usage: java LocationReporter URL1 URL2...");
}
// Install the Content Handler
parser.setContentHandler(new LocationReporter());
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.parse(args[i]);
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not report on " + args[i]
+ " because of the IOException " + e);
}
}
}
}
Document started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 1, column 1
Got a processing instruction in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 2, column 51
Started mapping prefix to URI http://metalab.unc.edu/xml/namespace/song in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 5, column 50
Started mapping prefix xlink to URI http://www.w3.org/1999/xlink in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 5, column 50
Element SONG started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 5, column 50
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 6, column 3
Element TITLE started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 6, column 10
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 6, column 17
Element TITLE ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 6, column 26
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 7, column 3
Element PHOTO started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 9, column 65
Element PHOTO ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 9, column 65
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 10, column 3
Element COMPOSER started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 10, column 13
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 10, column 27
Element COMPOSER ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 10, column 39
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 11, column 3
Element COMPOSER started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 11, column 13
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 11, column 25
Element COMPOSER ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 11, column 37
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 12, column 3
Element COMPOSER started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 12, column 13
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 12, column 26
Element COMPOSER ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 12, column 38
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 13, column 3
Element PRODUCER started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 13, column 13
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 13, column 27
Element PRODUCER ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 13, column 39
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 14, column 3
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 16, column 3
Element PUBLISHER started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 16, column 73
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 17, column 7
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 17, column 12
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 18, column 3
Element PUBLISHER ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 18, column 16
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 19, column 3
Element LENGTH started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 19, column 11
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 19, column 15
Element LENGTH ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 19, column 25
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 20, column 3
Element YEAR started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 20, column 9
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 20, column 13
Element YEAR ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 20, column 21
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 21, column 3
Element ARTIST started in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 21, column 11
Got some characters in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 21, column 25
Element ARTIST ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 21, column 35
Got some ignorable white space in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 22, column 1
Element SONG ended in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 22, column 9
Stopped mapping prefix xlink in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 22, column 9
Stopped mapping prefix in file:///J:/KENTUCKY/xmlandjava/EXAMPLES/hotcop.xml at line 22, column 9
Document ended in Null Entity at line -1, column -1
Implements the main interfaces with do-nothing methods
EntityResolver
DTDHandler
ContentHandler
ErrorHandler
Keeps track of namespace bindings on a stack
Allows you to determine what UYRI a prefix is mapped to at any point in the document
The NamespaceSupport class:
package org.xml.sax.helpers;
public class NamespaceSupport {
public final static String XMLNS = "http://www.w3.org/XML/1998/namespace";
public NamespaceSupport();
public void reset();
public void pushContext();
public void popContext();
public boolean declarePrefix(String prefix, String uri);
public String getURI(String prefix);
public Enumeration getPrefixes();
public Enumeration getDeclaredPrefixes();
public String[] processName(String qualifiedName,
String[] parts, boolean isAttribute);
}The XMLFilter interface is like an XML reader,
"except that it obtains its events from another XML reader
rather than a primary source like an XML document or database.
Filters can modify a stream of
events as they pass on to the final application."
The parent is the parser the filter gets the data from.
Only two methods in the interface:
public void setParent(XMLReader parent)
public XMLReader getParent()
XMLFilterImpl is a default filter that simply passes along
all events it receives:
public class XMLFilterImpl implements XMLFilter, EntityResolver, DTDHandler,
ContentHandler, ErrorHandler
Only new methods are constructors:
public XMLFilterImpl()
public XMLFilterImpl(XMLReader parent)
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.util.*;
import java.io.IOException;
public class UnparsedTextFilter extends XMLFilterImpl {
private TextEntityReplacer replacer;
public UnparsedTextFilter(XMLReader parent) {
super(parent);
}
public void parse(InputSource input)
throws IOException, SAXException {
System.out.println("parsing");
replacer = new TextEntityReplacer(input.getPublicId(),
input.getSystemId());
this.setDTDHandler(replacer);
this.setContentHandler(this);
}
// The other parse() method just calls this one
public void parse(String systemId)
throws IOException, SAXException {
parse(new InputSource(systemId));
}
public void startElement(String uri, String localName,
String qualifiedName, Attributes attributes) throws SAXException {
System.out.println("startElement");
Vector extraText = new Vector();
// Are there any unparsed entities in the attributes?
for (int i = 0; i < attributes.getLength(); i++) {
if (attributes.getType(i).equals("ENTITY")) {
try {
System.out.println("replacing");
String s = replacer.getText(attributes.getValue(i));
if (s != null) extraText.addElement(s);
}
catch (IOException e) {
System.err.println(e);
}
}
}
super.startElement(uri, localName, qualifiedName, attributes);
// Now spew out the values of the unparsed entities:
Enumeration e = extraText.elements();
while (e.hasMoreElements()) {
Object o = e.nextElement();
String s = (String) o;
super.characters(s.toCharArray(), 0, s.length());
}
}
}
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.util.*;
import java.io.IOException;
import org.apache.xml.serialize.*;
public class TextMerger {
public static void main(String[] args) {
XMLReader base;
try {
base = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (Exception e) {
// fall back on default parser
try {
base = XMLReaderFactory.createXMLReader();
}
catch (Exception ee) {
System.err.println("Couldn't locate a SAX parser");
return;
}
}
XMLReader parser = new UnparsedTextFilter(base);
//essentially a pretty printer
XMLSerializer printer
= new XMLSerializer(System.out, new OutputFormat());
base.setContentHandler(printer);
for (int i = 0; i < args.length; i++) {
try {
System.out.println("Parsing " + args[i]);
parser.parse(args[i]);
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not report on " + args[i]
+ " because of the IOException " + e);
}
} // end for
System.out.flush();
}
}
Encapsulates access to data so that it looks the same whether it's coming from a
URL
file
stream
reader
database
something else
Used in SAX1 and SAX2
Allows the source to be changed
package org.xml.sax;
import java.io.*;
public class InputSource {
public InputSource()
public InputSource(String systemID)
public InputSource(InputStream in)
public InputSource(Reader in)
public void setPublicId(String publicID)
public String getPublicId()
public void setSystemId(String systemID)
public String getSystemId()
public void setByteStream(InputStream byteStream)
public InputStream getByteStream()
public void setEncoding(String encoding)
public String getEncoding()
public void setCharacterStream(Reader characterStream)
public Reader getCharacterStream()
}
import org.xml.sax;
import java.io.*;
import java.net.*;
import java.util.zip.*;
...
try {
URL u = new URL(
"http://www.cafeconleche.org/examples/1998validstats.xml.gz");
InputStream raw = u.openStream();
InputStream decompressed = new GZIPInputStream(raw);
InputSource in = new InputSource(decompressed);
// read the document...
}
catch (IOException e) {
System.err.println(e);
}
catch (SAXException e) {
System.err.println(e);
}
ELEMENT, ATTLIST, ENTITY declarations are only optionally reported
Schema declarations aren't reported at all
Lexical events are only optionally reported
SAX2 can be configured on top of a lot of different parsers with different capabilities. What the parser does is more important than what SAX2 does.
You do not always have all the information you need at the time of a given callback
You may need to store information in various data structures (stacks, queues,vectors, arrays, etc.) and act on it at a later point
For example the characters() method is not guaranteed
to give you the maximum number of contiguous characters. It may
split a single run of characters over multiple method calls.
Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 6-8
XML in a Nutshell, 2nd Edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2002
ISBN 0-596-00292-0
SAX website: http://www.saxproject.org/
The DOM (like XML) is not a triumph of elegance; it's a triumph of "if we do not hang together, we shall hang separately." At least the Browser Wars were not followed by API Wars. Better a common API that we all love to hate than a bazillion contending APIs that carve the Web up into contending enclaves of True Believers.
--Mike Champion on the xml-dev mailing list, Thursday, September 27, 2001
Writing with DOM
Reading with DOM
An XML document can be represented as a tree.
It has a root.
It has nodes.
It is amenable to recursive processing.
Not all applications agree on what the root is.
Not all applications agree on what is and isn't a node.
Defines how XML and HTML documents are represented as objects in programs
Defined in IDL; thus language independent
HTML as well as XML
Writing as well as reading
Covers everything except internal and external DTD subsets
DOM focuses more on the document; SAX focuses more on the parser.
DOM Level 0:
DOM Level 1, a W3C Standard
DOM Level 2, a W3C Standard
DOM Level 3: Several Working Drafts:
Apache XML Project's Xerces Java: http://xml.apache.org/xerces-j/index.html
IBM's XML for Java: http://www.alphaworks.ibm.com/formula/xml
Sun's Java API for XML http://java.sun.com/products/xml
GNU JAXP: http://www.gnu.org/software/classpathx/jaxp/jaxp.html
Eight Modules:
Core: org.w3c.dom *
HTML: org.w3c.dom.html
Views: org.w3c.dom.views
StyleSheets: org.w3c.dom.stylesheets
CSS: org.w3c.dom.css
Events: org.w3c.dom.events *
Traversal: org.w3c.dom.traversal *
Range: org.w3c.dom.range
Only the core and traversal modules really apply to XML. The other six are for HTML.
* indicates Xerces support
Entire document is represented as a tree.
A tree contains nodes.
Some nodes may contain other nodes (depending on node type).
Each document node contains:
zero or one doctype nodes
one root element node
zero or more comment and processing instruction nodes
17 interfaces:
Attr
CDATASection
CharacterData
Comment
Document
DocumentFragment
DocumentType
DOMImplementation
Element
Entity
EntityReference
NamedNodeMap
Node
NodeList
Notation
ProcessingInstruction
Text
plus one exception:
DOMException
Plus a bunch of HTML stuff in org.w3c.dom.html
and other packages
we will ignore
Library specific code creates a parser
The parser parses the document and returns a DOM
org.w3c.dom.Document object.
The entire document is stored in memory.
DOM methods and interfaces are used to extract data from this object
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class DOMParserMaker {
public static void main(String[] args) {
// This is simpler but less flexible than the SAX approach.
// Perhaps a good creational design pattern is needed here?
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document d = parser.getDocument();
// work with the document...
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
}
}javax.xml.parsers.DocumentBuilderFactory.newInstance()
creates a DocumentBuilderFactory
The factory's newBuilder() method
creates a DocumentBuilder
The builder parses the document and returns a DOM
org.w3c.dom.Document object.
The entire document is stored in memory.
DOM methods and interfaces are used to extract data from this object
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class JAXPParserMaker {
public static void main(String[] args) {
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
DocumentBuilder parser
= builderFactory.newDocumentBuilder();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
Document d = parser.parse(args[i]);
// work with the document...
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
} // end for
}
catch (ParserConfigurationException e) {
System.err.println("You need to install a JAXP aware parser.");
}
}
}
package org.w3c.dom;
public interface Node {
// NodeType
public static final short ELEMENT_NODE = 1;
public static final short ATTRIBUTE_NODE = 2;
public static final short TEXT_NODE = 3;
public static final short CDATA_SECTION_NODE = 4;
public static final short ENTITY_REFERENCE_NODE = 5;
public static final short ENTITY_NODE = 6;
public static final short PROCESSING_INSTRUCTION_NODE = 7;
public static final short COMMENT_NODE = 8;
public static final short DOCUMENT_NODE = 9;
public static final short DOCUMENT_TYPE_NODE = 10;
public static final short DOCUMENT_FRAGMENT_NODE = 11;
public static final short NOTATION_NODE = 12;
public String getNodeName();
public String getNodeValue() throws DOMException;
public void setNodeValue(String nodeValue) throws DOMException;
public short getNodeType();
public Node getParentNode();
public NodeList getChildNodes();
public Node getFirstChild();
public Node getLastChild();
public Node getPreviousSibling();
public Node getNextSibling();
public NamedNodeMap getAttributes();
public Document getOwnerDocument();
public Node insertBefore(Node newChild, Node refChild) throws DOMException;
public Node replaceChild(Node newChild, Node oldChild) throws DOMException;
public Node removeChild(Node oldChild) throws DOMException;
public Node appendChild(Node newChild) throws DOMException;
public boolean hasChildNodes();
public Node cloneNode(boolean deep);
public void normalize();
public boolean supports(String feature, String version);
public String getNamespaceURI();
public String getPrefix();
public void setPrefix(String prefix) throws DOMException;
public String getLocalName();
}package org.w3c.dom;
public interface NodeList {
public Node item(int index);
public int getLength();
}
Now we're really ready to read a document
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class NodeReporter {
public static void main(String[] args) {
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
DocumentBuilder parser
= builderFactory.newDocumentBuilder();
NodeReporter iterator = new NodeReporter();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
Document doc = parser.parse(args[i]);
iterator.followNode(doc);
}
catch (SAXException ex) {
System.err.println(args[i] + " is not well-formed.");
}
catch (IOException ex) {
System.err.println(ex);
}
}
}
catch (ParserConfigurationException ex) {
System.err.println("You need to install a JAXP aware parser.");
}
} // end main
// note use of recursion
public void followNode(Node node) {
processNode(node);
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
followNode(children.item(i));
}
}
}
public void processNode(Node node) {
String name = node.getNodeName();
String type = getTypeName(node.getNodeType());
System.out.println("Type " + type + ": " + name);
}
public static String getTypeName(int type) {
switch (type) {
case Node.ELEMENT_NODE:
return "Element";
case Node.ATTRIBUTE_NODE:
return "Attribute";
case Node.TEXT_NODE:
return "Text";
case Node.CDATA_SECTION_NODE:
return "CDATA Section";
case Node.ENTITY_REFERENCE_NODE:
return "Entity Reference";
case Node.ENTITY_NODE:
return "Entity";
case Node.PROCESSING_INSTRUCTION_NODE:
return "Processing Instruction";
case Node.COMMENT_NODE :
return "Comment";
case Node.DOCUMENT_NODE:
return "Document";
case Node.DOCUMENT_TYPE_NODE:
return "Document Type Declaration";
case Node.DOCUMENT_FRAGMENT_NODE:
return "Document Fragment";
case Node.NOTATION_NODE:
return "Notation";
default:
return "Unknown Type";
}
}
}% java NodeReporter hotcop.xml Type Document: #document Type Processing Instruction: xml-stylesheet Type Document Type Declaration: SONG Type Element: SONG Type Text: #text Type Element: TITLE Type Text: #text Type Text: #text Type Element: PHOTO Type Text: #text Type Element: COMPOSER Type Text: #text Type Text: #text Type Element: COMPOSER Type Text: #text Type Text: #text Type Element: COMPOSER Type Text: #text Type Text: #text Type Element: PRODUCER Type Text: #text Type Text: #text Type Comment: #comment Type Text: #text Type Element: PUBLISHER Type Text: #text Type Text: #text Type Element: LENGTH Type Text: #text Type Text: #text Type Element: YEAR Type Text: #text Type Text: #text Type Element: ARTIST Type Text: #text Type Text: #text Type Comment: #comment
Attributes are missing from this output. They are not nodes. They are properties of nodes.
| Node Type | Node Value |
|---|---|
| element node | null |
| attribute node | attribute value |
| text node | text of the node |
| CDATA section node | text of the section |
| entity reference node | null |
| entity node | null |
| processing instruction node | content of the processing instruction, not including the target |
| comment node | text of the comment |
| document node | null |
| document type declaration node | null |
| document fragment node | null |
| notation node | null |
The root node representing the entire document; not the same as the root element
Contains:
one element node
zero or more processing instruction nodes
zero or more comment nodes
zero or one document type nodes
package org.w3c.dom;
public interface Document extends Node {
public DocumentType getDoctype();
public DOMImplementation getImplementation();
public Element getDocumentElement();
public Element createElement(String tagName) throws DOMException;
public Element createElementNS(String namespaceURI, String qualifiedName) throws DOMException;
public DocumentFragment createDocumentFragment();
public Text createTextNode(String data);
public Comment createComment(String data);
public CDATASection createCDATASection(String data) throws DOMException;
public ProcessingInstruction createProcessingInstruction(String target, String data)
throws DOMException;
public Attr createAttribute(String name) throws DOMException;
public Attr createAttributeNS(String namespaceURI, String qualifiedName) throws DOMException;
public EntityReference createEntityReference(String name) throws DOMException;
public NodeList getElementsByTagName(String tagname);
public NodeList getElementsByTagNameNS(String namespaceURI, String localName);
public Element getElementById(String elementId);
public Node importNode(Node importedNode, boolean deep) throws DOMException;
}
UserLand's RSS based list of Web logs at http://static.userland.com/weblogMonitor/logs.xml:
<?xml version="1.0"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl></imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description></description>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
We can easily find out how many URLs there will be when we start parsing, since they're all in memory.
Single threaded by nature; no benefit to multiple threads since no data will be available until the entire document has been read and parsed.
The character data of each url
element needs to be read.
Everything else can be ignored.
The getElementsByTagName() method in
Document gives us a quick list of all the
url
elements.
The XML parsing is so straight-forward it can be done inside one method. No extra class is required.
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import java.io.IOException;
import java.util.*;
import java.net.*;
public class WeblogsDOM {
public static String DEFAULT_URL
= "http://static.userland.com/weblogMonitor/logs.xml";
public static List listChannels() throws DOMException {
return listChannels(DEFAULT_URL);
}
public static List listChannels(String uri) throws DOMException {
if (uri == null) {
throw new NullPointerException("URL must be non-null");
}
org.apache.xerces.parsers.DOMParser parser
= new org.apache.xerces.parsers.DOMParser();
Vector urls = null;
try {
// Read the entire document into memory
parser.parse(uri);
Document doc = parser.getDocument();
NodeList logs = doc.getElementsByTagName("url");
urls = new Vector(logs.getLength());
for (int i = 0; i < logs.getLength(); i++) {
try {
Node element = logs.item(i);
Node text = element.getFirstChild();
String content = text.getNodeValue();
URL u = new URL(content);
urls.addElement(u);
}
catch (MalformedURLException e) {
// bad input data from one third party; just ignore it
}
}
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
return urls;
}
public static void main(String[] args) {
try {
List urls;
if (args.length > 0) {
try {
URL url = new URL(args[0]);
urls = listChannels(args[0]);
}
catch (MalformedURLException e) {
System.err.println("Usage: java WeblogsDOM url");
return;
}
}
else {
urls = listChannels();
}
Iterator iterator = urls.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
catch (/* Unexpected */ Exception e) {
e.printStackTrace();
}
} // end main
}% java WeblogsDOM
http://2020Hindsight.editthispage.com/
http://www.sff.net/people/mitchw/weblog/weblog.htp
http://nate.weblogs.com/
http://plugins.launchpoint.net
http://404.psistorm.net
http://home.att.net/~geek9000
http://daubnet.tzo.com/weblog
several hundred more...
Represents a complete element including its start-tag, end-tag, and content
Contains:
Element nodes
ProcessingInstruction nodes
Comment nodes
Text nodes
CDATASection nodes
EntityReference nodes
package org.w3c.dom;
public interface Element extends Node {
public String getTagName();
public NodeList getElementsByTagName(String name);
public NodeList getElementsByTagNameNS(String namespaceURI,
String localName);
public String getAttribute(String name);
public String getAttributeNS(String namespaceURI,
String localName);
public void setAttribute(String name, String value)
throws DOMException;
public void setAttributeNS(String namespaceURI,
String qualifiedName, String value) throws DOMException;
public void removeAttribute(String name) throws DOMException;
public void removeAttributeNS(String namespaceURI,
String localName) throws DOMException;
public Attr getAttributeNode(String name);
public Attr getAttributeNodeNS(String namespaceURI, String localName);
public Attr setAttributeNode(Attr newAttr) throws DOMException;
public Attr setAttributeNodeNS(Attr newAttr) throws DOMException;
public Attr removeAttributeNode(Attr oldAttr) throws DOMException;
}
import org.apache.xerces.parsers.DOMParser;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.IOException;
import org.apache.xml.serialize.*;
public class IDTagger {
int id = 1;
public void processNode(Node node) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
String currentID = element.getAttribute("ID");
if (currentID == null || currentID.equals("")) {
element.setAttribute("ID", "_" + id);
id = id + 1;
}
}
}
// note use of recursion
public void followNode(Node node) {
processNode(node);
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
followNode(children.item(i));
}
}
}
public static void main(String[] args) {
DOMParser parser = new DOMParser();
IDTagger iterator = new IDTagger();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document document = parser.getDocument();
iterator.followNode(document);
// now we serialize the document...
OutputFormat format = new OutputFormat(document);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(document);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<?xml-stylesheet type="text/css" href="song.css"?><!-- This should be a four digit year like "1999",
not a two-digit year like "99" --><SONG xmlns="http://www.cafeconleche.org/namespace/song" ID="_1" xmlns:xlink="http://www.w3.org/1999/xlink"> <TITLE ID="_2">Hot Cop</TITLE> <PHOTO ALT="Victor Willis in Cop Outfit" HEIGHT="200" ID="_3" WIDTH="100" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="hotcop.jpg" xlink:show="onLoad" xlink:type="simple"/> <COMPOSER ID="_4">Jacques Morali</COMPOSER> <COMPOSER ID="_5">Henri Belolo</COMPOSER> <COMPOSER ID="_6">Victor Willis</COMPOSER> <PRODUCER ID="_7">Jacques Morali</PRODUCER> <!-- The publisher is actually Polygram but I needed
an example of a general entity reference. --> <PUBLISHER ID="_8" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="http://www.amrecords.com/" xlink:type="simple"> A & M Records </PUBLISHER> <LENGTH ID="_9">6:20</LENGTH> <YEAR ID="_10">1978</YEAR> <ARTIST ID="_11">Village People</ARTIST> </SONG><!-- You can tell what album I was
listening to when I wrote this example -->Represents things that are basically text holders
Super interface of Text, Comment,
and CDATASection
package org.w3c.dom;
public interface CharacterData extends Node {
public String getData() throws DOMException;
public void setData(String data) throws DOMException;
public int getLength();
public String substringData(int offset, int count)
throws DOMException;
public void appendData(String arg)
throws DOMException;
public void insertData(int offset, String arg)
throws DOMException;
public void deleteData(int offset, int count)
throws DOMException;
public void replaceData(int offset, int count, String arg)
throws DOMException;
}
import org.apache.xerces.parsers.DOMParser;
import org.apache.xml.serialize.*;
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import java.io.IOException;
public class ROT13XML {
public void processNode(Node node) {
if (node.getNodeType() == Node.TEXT_NODE
|| node.getNodeType() == Node.COMMENT_NODE
|| node.getNodeType() == Node.CDATA_SECTION_NODE) {
CharacterData text = (CharacterData) node;
String data = text.getData();
text.setData(rot13(data));
}
}
// note use of recursion
public void followNode(Node node) {
processNode(node);
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
followNode(children.item(i));
}
}
}
public static String rot13(String s) {
StringBuffer result = new StringBuffer(s.length());
for (int i = 0; i < s.length(); i++) {
int c = s.charAt(i);
if (c >= 'A' && c <= 'M') result.append((char) (c+13));
else if (c >= 'N' && c <= 'Z') result.append((char) (c-13));
else if (c >= 'a' && c <= 'm') result.append((char) (c+13));
else if (c >= 'n' && c <= 'z') result.append((char) (c-13));
else result.append((char) c);
}
return result.toString();
}
public static void main(String[] args) {
DOMParser parser = new DOMParser();
ROT13XML iterator = new ROT13XML();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document document = parser.getDocument();
iterator.followNode(document);
// now we serialize the document...
OutputFormat format = new OutputFormat(document);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(document);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<?xml-stylesheet type="text/css" href="song.css"?>
<SONG xmlns="http://metalab.unc.edu/xml/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink"> <TITLE>Ubg Pbc</TITLE>
<PHOTO ALT="Victor Willis in Cop Outfit" HEIGHT="200" WIDTH="100"
xlink:href="hotcop.jpg" xlink:show="onLoad" xlink:type="simple"/>
<COMPOSER>Wnpdhrf Zbenyv</COMPOSER> <COMPOSER>Uraev Orybyb</COMPOSER>
<COMPOSER>Ivpgbe Jvyyvf</COMPOSER> <PRODUCER>Wnpdhrf Zbenyv</PRODUCER>
<!-- Gur choyvfure vf npghnyyl Cbyltenz ohg V arrqrq na rknzcyr
bs n trareny ragvgl ersrerapr. --> <PUBLISHER
xlink:href="http://www.amrecords.com/" xlink:type="simple"> N &
Z Erpbeqf </PUBLISHER> <LENGTH>6:20</LENGTH> <YEAR>1978</YEAR>
<ARTIST>Ivyyntr Crbcyr</ARTIST> </SONG>
<!-- Lbh pna gryy jung nyohz V jnf
yvfgravat gb jura V jebgr guvf rknzcyr -->
Represents the text content of an element or attribute
Contains only pure text, no markup
Parsers will return a single maximal text node for each contiguous run of pure text
Editing may change this
package org.w3c.dom;
public interface Text extends CharacterData {
public Text splitText(int offset) throws DOMException;
}
Represents a CDATA section like this example from a hypothetical SVG tutorial:
<p>You can use a default <code>xmlns</code> attribute to avoid
having to add the svg prefix to all your elements:</p>
<![CDATA[
<svg xmlns="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<ellipse rx="110" ry="130" />
<rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg>
]]>
No children
package org.w3c.dom;
public interface CDATASection extends Text {
}
Represents a document type declaration
Has no children
package org.w3c.dom;
public interface DocumentType extends Node {
public String getName();
public NamedNodeMap getEntities();
public NamedNodeMap getNotations();
public String getPublicId();
public String getSystemId();
public String getInternalSubset();
}
Verify that a document is correct XHTML
From the XHTML 1.0 spec:
It must validate against one of the three DTDs found in Appendix A.
The root element of the document must be
<html>.
The root element of the document must designate the XHTML namespace using the
xmlnsattribute [XMLNAMES]. The namespace for XHTML is defined to behttp://www.w3.org/1999/xhtml.
There must be a DOCTYPE declaration in the document prior to the root element. The public identifier included in the DOCTYPE declaration must reference one of the three DTDs found in Appendix A using the respective Formal Public Identifier. The system identifier may be changed to reflect local system conventions.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "DTD/xhtml1-frameset.dtd">
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;
import org.xml.sax.*;
public class XHTMLValidator {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java XHTMLValidator URL");
return;
}
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
builderFactory.setNamespaceAware(true);
builderFactory.setValidating(true);
DocumentBuilder parser
= builderFactory.newDocumentBuilder();
parser.setErrorHandler(new ValidityErrorReporter());
Document document;
try {
document = parser.parse(args[0]);
// ValidityErrorReporter prints any validity errors detected
}
catch (SAXException e) {
System.out.println(args[0] + " is not valid.");
return;
}
// If we get this far, then the document is valid XML.
// Check to see whether the document is actually XHTML
DocumentType doctype = document.getDoctype();
if (doctype == null) {
System.out.println("No DOCTYPE");
return;
}
String name = doctype.getName();
String systemID = doctype.getSystemId();
String publicID = doctype.getPublicId();
if (!name.equals("html")) {
System.out.println("Incorrect root element name " + name);
}
if (publicID == null
|| (!publicID.equals("-//W3C//DTD XHTML 1.0 Strict//EN")
&& !publicID.equals(
"-//W3C//DTD XHTML 1.0 Transitional//EN")
&& !publicID.equals(
"-//W3C//DTD XHTML 1.0 Frameset//EN"))) {
System.out.println(args[0]
+ " does not seem to use an XHTML 1.0 DTD");
}
// Check the namespace on the root element
Element root = document.getDocumentElement();
String xmlnsValue = root.getAttribute("xmlns");
if (!xmlnsValue.equals("http://www.w3.org/1999/xhtml")) {
System.out.println(args[0]
+ " does not properly declare the"
+ " http://www.w3.org/1999/xhtml"
+ " namespace on the root element");
}
System.out.println(args[0] + " is valid XHTML.");
}
catch (IOException e) {
System.err.println("Could not read " + args[0]);
}
catch (Exception e) {
System.err.println(e);
e.printStackTrace();
}
}
}Represents an entity reference like &
or &signature;
Optional: some parsers (including Xerces) just expand entities
Contains:
Element nodes
ProcessingInstruction nodes
Comment nodes
Text nodes
CDATASection nodes
EntityReference nodes
package org.w3c.dom;
public interface EntityReference extends Node {
}
Represents an attribute
Contains:
Text nodes
Entity reference nodes
package org.w3c.dom;
public interface Attr extends Node {
public String getName();
public boolean getSpecified();
public String getValue();
public void setValue(String value) throws DOMException;
public Element getOwnerElement();
}
import org.xml.sax.*;
import java.io.*;
import java.util.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class DOMSpider {
private static DocumentBuilder parser;
// namespace support is turned off by default in JAXP
static {
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
builderFactory.setNamespaceAware(true);
parser = builderFactory.newDocumentBuilder();
}
catch (Exception ex) {
throw new RuntimeException("Couldn't build a parser!");
}
}
private static Vector visited = new Vector();
private static int maxDepth = 5;
private static int currentDepth = 0;
public static void listURIs(String systemId) {
currentDepth++;
try {
if (currentDepth < maxDepth) {
Document document = parser.parse(systemId);
Vector uris = new Vector();
// search the document for uris,
// store them in vector, and print them
searchForURIs(document.getDocumentElement(), uris);
Enumeration e = uris.elements();
while (e.hasMoreElements()) {
String uri = (String) e.nextElement();
visited.addElement(uri);
listURIs(uri);
}
}
}
catch (SAXException e) {
// couldn't load the document,
// probably not well-formed XML, skip it
}
catch (IOException e) {
// couldn't load the document,
// likely network failure, skip it
}
finally {
currentDepth--;
System.out.flush();
}
}
// use recursion
public static void searchForURIs(Element element, Vector uris) {
// look for XLinks in this element
String uri = element.getAttributeNS("http://www.w3.org/1999/xlink", "href");
if (uri != null && !uri.equals("")
&& !visited.contains(uri)
&& !uris.contains(uri)) {
System.out.println(uri);
uris.addElement(uri);
}
// process child elements recursively
NodeList children = element.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n instanceof Element) {
searchForURIs((Element) n, uris);
}
}
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java DOMSpider URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
try {
listURIs(args[i]);
}
catch (Exception e) {
System.err.println(e);
e.printStackTrace();
}
} // end for
} // end main
} // end DOMSpider
Represents a processing instruction like
<?robots index="yes" follow="no"?>
No children
package org.w3c.dom;
public interface ProcessingInstruction extends Node {
public String getTarget();
public String getData();
public void setData(String data) throws DOMException;
}import org.xml.sax.*;
import java.io.*;
import java.util.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class PoliteDOMSpider {
private static DocumentBuilder parser;
// namespace support is turned off by default in JAXP
static {
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
builderFactory.setNamespaceAware(true);
parser = builderFactory.newDocumentBuilder();
}
catch (Exception ex) {
throw new RuntimeException("Couldn't build a parser!");
}
}
private static Vector visited = new Vector();
private static int maxDepth = 5;
private static int currentDepth = 0;
public static boolean robotsAllowed(Document document) {
NodeList children = document.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n instanceof ProcessingInstruction) {
ProcessingInstruction pi = (ProcessingInstruction) n;
if (pi.getTarget().equals("robots")) {
String data = pi.getData();
if (data.indexOf("follow=\"no\"") >= 0) {
return false;
}
}
}
}
return true;
}
public static void listURIs(String systemId) {
currentDepth++;
try {
if (currentDepth < maxDepth) {
Document document = parser.parse(systemId);
if (robotsAllowed(document)) {
Vector uris = new Vector();
// search the document for uris,
// store them in vector, print them
searchForURIs(document.getDocumentElement(), uris);
Enumeration e = uris.elements();
while (e.hasMoreElements()) {
String uri = (String) e.nextElement();
visited.addElement(uri);
listURIs(uri);
}
}
}
}
catch (SAXException e) {
// couldn't load the document,
// probably not well-formed XML, skip it
}
catch (IOException e) {
// couldn't load the document,
// likely network failure, skip it
}
finally {
currentDepth--;
System.out.flush();
}
}
// use recursion
public static void searchForURIs(Element element, Vector uris) {
// look for XLinks in this element
String uri = element.getAttributeNS("http://www.w3.org/1999/xlink", "href");
if (uri != null && !uri.equals("")
&& !visited.contains(uri)
&& !uris.contains(uri)) {
System.out.println(uri);
uris.addElement(uri);
}
// process child elements recursively
NodeList children = element.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n instanceof Element) {
searchForURIs((Element) n, uris);
}
}
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java PoliteDOMSpider URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
try {
listURIs(args[i]);
}
catch (Exception e) {
System.err.println(e);
e.printStackTrace();
}
} // end for
} // end main
} // end PoliteDOMSpider
Represents a comment like this example from the XML 1.0 spec:
<!--* N.B. some readers (notably JC) find the following
paragraph awkward and redundant. I agree it's logically redundant:
it *says* it is summarizing the logical implications of
matching the grammar, and that means by definition it's
logically redundant. I don't think it's rhetorically
redundant or unnecessary, though, so I'm keeping it. It
could however use some recasting when the editors are feeling
stronger. -MSM *-->
No children
package org.w3c.dom;
public interface Comment extends CharacterData {
}
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class DOMCommentReader {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document d = parser.getDocument();
processNode(d);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
// note use of recursion
public static void processNode(Node node) {
int type = node.getNodeType();
if (type == Node.COMMENT_NODE) {
System.out.println(node.getNodeValue());
System.out.println();
}
else {
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
processNode(children.item(i));
}
}
}
}
}% java DOMCommentReader hotcop.xml
The publisher is actually Polygram but I needed
an example of a general entity reference.
You can tell what album I was
listening to when I wrote this example
Or try http://www.w3.org/TR/1998/REC-xml-19980210.xml for more interesting output
Represents an actual entity, not an entity reference!
Contains:
Element nodes
ProcessingInstruction nodes
Comment nodes
Text nodes
CDATASection nodes
EntityReference nodes
package org.w3c.dom;
public interface Entity extends Node {
public String getPublicId();
public String getSystemId();
public String getNotationName();
}
A runtime exception but you should catch it
Error code gives more detailed information:
DOMException.INDEX_SIZE_ERRDOMException.DOMSTRING_SIZE_ERRStringDOMException.HIERARCHY_REQUEST_ERRDOMException.WRONG_DOCUMENT_ERRDOMException.INVALID_CHARACTER_ERRDOMException.NO_DATA_ALLOWED_ERRDOMException.NO_MODIFICATION_ALLOWED_ERRDOMException.NOT_FOUND_ERRDOMException.NOT_SUPPORTED_ERRDOMException.INUSE_ATTRIBUTE_ERRDOMException.INVALID_STATE_ERRDOMException.SYNTAX_ERRDOMException.INVALID_MODIFICATION_ERRDOMException.NAMESPACE_ERRDOMException.INVALID_ACCESS_ERRCurrent value accessible from the public code field
Four interfaces:
DocumentTraversal
NodeFilter
NodeIterator
TreeWalker
package org.w3c.dom.traversal;
public interface NodeIterator {
public int getWhatToShow();
public NodeFilter getFilter();
public boolean getExpandEntityReferences();
public Node nextNode() throws DOMException;
public Node previousNode() throws DOMException;
public void detach();
}
import org.apache.xerces.parsers.*;
import org.apache.xerces.dom.*;
import org.w3c.dom.*;
import org.w3c.dom.traversal.*;
import org.xml.sax.*;
import java.io.*;
public class ValueReporter {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document doc = parser.getDocument();
DocumentImpl impl = (DocumentImpl) doc;
NodeIterator iterator = impl.createNodeIterator(
doc.getDocumentElement(), NodeFilter.SHOW_ALL, null, true
);
Node node;
while ((node = iterator.nextNode()) != null) {
processNode(node);
}
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
public static void processNode(Node node) {
String name = node.getNodeName();
String type = getTypeName(node.getNodeType());
String value = node.getNodeValue();
System.out.println("Type " + type + ": " + name
+ " \"" + value + "\"");
}
public static String getTypeName(int type) {
switch (type) {
case Node.ELEMENT_NODE:
return "Element";
case Node.ATTRIBUTE_NODE:
return "Attribute";
case Node.TEXT_NODE:
return "Text";
case Node.CDATA_SECTION_NODE:
return "CDATA Section";
case Node.ENTITY_REFERENCE_NODE:
return "Entity Reference";
case Node.ENTITY_NODE:
return "Entity";
case Node.PROCESSING_INSTRUCTION_NODE:
return "Processing Instruction";
case Node.COMMENT_NODE:
return "Comment";
case Node.DOCUMENT_NODE:
return "Document";
case Node.DOCUMENT_TYPE_NODE:
return "Document Type Declaration";
case Node.DOCUMENT_FRAGMENT_NODE:
return "Document Fragment";
case Node.NOTATION_NODE:
return "Notation";
default:
return "Unknown Type";
}
}
}% java ValueReporter hotcop.xml
Type Element: SONG "null"
Type Text: #text "
"
Type Element: TITLE "null"
Type Text: #text "Hot Cop"
Type Text: #text "
"
Type Element: PHOTO "null"
Type Text: #text "
"
Type Element: COMPOSER "null"
Type Text: #text "Jacques Morali"
Type Text: #text "
"
Type Element: COMPOSER "null"
Type Text: #text "Henri Belolo"
Type Text: #text "
"
Type Element: COMPOSER "null"
Type Text: #text "Victor Willis"
Type Text: #text "
"
Type Element: PRODUCER "null"
Type Text: #text "Jacques Morali"
Type Text: #text "
"
Type Comment: #comment " The publisher is actually Polygram but I needed
an example of a general entity reference. "
Type Text: #text "
"
Type Element: PUBLISHER "null"
Type Text: #text "
A & M Records
"
Type Text: #text "
"
Type Element: LENGTH "null"
Type Text: #text "6:20"
Type Text: #text "
"
Type Element: YEAR "null"
Type Text: #text "1978"
Type Text: #text "
"
Type Element: ARTIST "null"
Type Text: #text "Village People"
Type Text: #text "
"
Attributes are missing from this output. They are not children. They are properties of nodes.
package org.w3c.dom.traversal;
public interface NodeFilter {
// Constants returned by acceptNode
public static final short FILTER_ACCEPT = 1;
public static final short FILTER_REJECT = 2;
public static final short FILTER_SKIP = 3;
// Constants for whatToShow
public static final int SHOW_ALL = 0x0000FFFF;
public static final int SHOW_ELEMENT = 0x00000001;
public static final int SHOW_ATTRIBUTE = 0x00000002;
public static final int SHOW_TEXT = 0x00000004;
public static final int SHOW_CDATA_SECTION = 0x00000008;
public static final int SHOW_ENTITY_REFERENCE = 0x00000010;
public static final int SHOW_ENTITY = 0x00000020;
public static final int SHOW_PROCESSING_INSTRUCTION = 0x00000040;
public static final int SHOW_COMMENT = 0x00000080;
public static final int SHOW_DOCUMENT = 0x00000100;
public static final int SHOW_DOCUMENT_TYPE = 0x00000200;
public static final int SHOW_DOCUMENT_FRAGMENT = 0x00000400;
public static final int SHOW_NOTATION = 0x00000800;
public short acceptNode(Node n);
}
import org.apache.xerces.parsers.*;
import org.apache.xerces.dom.*;
import org.w3c.dom.*;
import org.w3c.dom.traversal.*;
import org.xml.sax.SAXException;
import java.io.IOException;
public class DOMTagStripper {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document doc = parser.getDocument();
DocumentImpl impl = (DocumentImpl) doc;
NodeIterator iterator = impl.createNodeIterator(
doc.getDocumentElement(), NodeFilter.SHOW_TEXT, null, true
);
Node node;
while ((node = iterator.nextNode()) != null) {
System.out.print(node.getNodeValue());
}
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}% java DOMTagStripper hotcop.xml Hot Cop Jacques Morali Henri Belolo Victor Willis Jacques Morali A & M Records 6:20 1978 Village People
DOM is for both input and output
New documents are created with a parser-specific API or JAXP
A serializer + output format converts the DOM to a byte stream
A Xerces-specific class used to create new DOM documents
package org.apache.xerces.dom;
public class DOMImplementationImpl implements DOMImplementation {
public boolean hasFeature(String feature, String version)
public static DOMImplementation getDOMImplementation()
public DocumentType createDocumentType(String qualifiedName,
String publicID, String systemID, String internalSubset)
public Document createDocument(String namespaceURI,
String qualifiedName, DocumentType doctype)
throws DOMException
}
import java.math.BigInteger;
import java.io.*;
import org.w3c.dom.*;
import org.apache.xerces.dom.*;
public class FibonacciDOM {
public static void main(String[] args) {
try {
DOMImplementation impl
= DOMImplementationImpl.getDOMImplementation();
Document fibonacci
= impl.createDocument(null, "Fibonacci_Numbers", null);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
Element root = fibonacci.getDocumentElement();
for (int i = 1; i <= 25; i++) {
Element number = fibonacci.createElement("fibonacci");
number.setAttribute("index", Integer.toString(i));
Text text = fibonacci.createTextNode(low.toString());
number.appendChild(text);
root.appendChild(number);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
// Now the document has been created and exists in memory
}
catch (DOMException e) {
e.printStackTrace();
}
}
}
import java.math.BigInteger;
import java.io.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class FibonacciJAXP {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory
= DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
DOMImplementation impl = builder.getDOMImplementation();
Document fibonacci
= impl.createDocument(null, "Fibonacci_Numbers", null);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
Element root = fibonacci.getDocumentElement();
for (int i = 1; i <= 25; i++) {
Element number = fibonacci.createElement("fibonacci");
number.setAttribute("index", Integer.toString(i));
Text text = fibonacci.createTextNode(low.toString());
number.appendChild(text);
root.appendChild(number);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
// Now the document has been created and exists in memory
}
catch (DOMException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
System.err.println("You need to install a JAXP aware DOM implementation.");
}
}
}
The process of taking an in-memory DOM tree and converting it to a stream of characters that can be written onto an output stream
Not a standard part of DOM Level 2
The public interface DOMSerializer public interface Serializer public abstract class BaseMarkupSerializer
extends Object
implements DocumentHandler, org.xml.sax.misc.LexicalHandler, DTDHandler,
org.xml.sax.misc.DeclHandler, DOMSerializer, Serializer public class HTMLSerializer
extends BaseMarkupSerializer public final class TextSerializer
extends BaseMarkupSerializer public final class XHTMLSerializer
extends HTMLSerializer public final class XMLSerializer
extends BaseMarkupSerializerorg.apache.xml.serialize package:
import java.math.BigInteger;
import java.io.*;
import org.w3c.dom.*;
import org.apache.xerces.dom.*;
import org.apache.xml.serialize.*;
public class FibonacciDOMSerializer {
public static void main(String[] args) {
try {
DOMImplementation impl
= DOMImplementationImpl.getDOMImplementation();
Document fibonacci
= impl.createDocument(null, "Fibonacci_Numbers", null);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
Element root = fibonacci.getDocumentElement();
for (int i = 1; i <= 25; i++) {
Element number = fibonacci.createElement("fibonacci");
number.setAttribute("index", Integer.toString(i));
Text text = fibonacci.createTextNode(low.toString());
number.appendChild(text);
root.appendChild(number);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
try {
// Now that the document is created we need to *serialize* it
OutputFormat format = new OutputFormat(fibonacci);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(fibonacci);
}
catch (IOException e) {
System.err.println(e);
}
}
catch (DOMException e) {
e.printStackTrace();
}
}
}
<?xml version="1.0" encoding="UTF-8"?>
<Fibonacci_Numbers><fibonacci index="0">0</fibonacci><fibonacci index="1">1</fibonacci><fibonacci index="2">1</fibonacci><fibonacci index="3">2</fibonacci><fibonacci index="4">3</fibonacci><fibonacci index="5">5</fibonacci><fibonacci index="6">8</fibonacci><fibonacci index="7">13</fibonacci><fibonacci index="8">21</fibonacci><fibonacci index="9">34</fibonacci><fibonacci index="10">55</fibonacci><fibonacci index="11">89</fibonacci><fibonacci index="12">144</fibonacci><fibonacci index="13">233</fibonacci><fibonacci index="14">377</fibonacci><fibonacci index="15">610</fibonacci><fibonacci index="16">987</fibonacci><fibonacci index="17">1597</fibonacci><fibonacci index="18">2584</fibonacci><fibonacci index="19">4181</fibonacci><fibonacci index="20">6765</fibonacci><fibonacci index="21">10946</fibonacci><fibonacci index="22">17711</fibonacci><fibonacci index="23">28657</fibonacci><fibonacci index="24">46368</fibonacci><fibonacci index="25">75025</fibonacci></Fibonacci_Numbers>package org.apache.xml.serialize;
public class OutputFormat extends Object {
public OutputFormat()
public OutputFormat(String method,
String encoding, boolean indenting)
public OutputFormat(Document doc)
public OutputFormat(Document doc,
String encoding, boolean indenting)
public String getMethod()
public void setMethod(String method)
public String getVersion()
public void setVersion(String version)
public int getIndent()
public boolean getIndenting()
public void setIndent(int indent)
public void setIndenting(boolean on)
public String getEncoding()
public void setEncoding(String encoding)
public String getMediaType()
public void setMediaType(String mediaType)
public void setDoctype(String publicID, String systemID)
public String getDoctypePublic()
public String getDoctypeSystem()
public boolean getOmitXMLDeclaration()
public void setOmitXMLDeclaration(boolean omit)
public boolean getStandalone()
public void setStandalone(boolean standalone)
public String[] getCDataElements()
public boolean isCDataElement(String tagName)
public void setCDataElements(String[] cdataElements)
public String[] getNonEscapingElements()
public boolean isNonEscapingElement(String tagName)
public void setNonEscapingElements(String[] nonEscapingElements)
public String getLineSeparator()
public void setLineSeparator(String lineSeparator)
public boolean getPreserveSpace()
public void setPreserveSpace(boolean preserve)
public int getLineWidth()
public void setLineWidth(int lineWidth)
public char getLastPrintable()
public static String whichMethod(Document doc)
public static String whichDoctypePublic(Document doc)
public static String whichDoctypeSystem(Document doc)
public static String whichMediaType(String method)
}
Latin-1 encoding
Indentation
Word wrapping
Document type declaration
try {
// Now that the document is created we need to *serialize* it
OutputFormat format = new OutputFormat(fibonacci, "8859_1", true);
format.setLineSeparator("\r\n");
format.setLineWidth(72);
format.setDoctype(null, "fibonacci.dtd");
XMLSerializer serializer = new XMLSerializer(System.out, format);
serializer.serialize(root);
}
catch (IOException e) {
System.err.println(e);
}
Question: Why won't this let us add an xml-stylesheet directive?
<?xml version="1.0" encoding="8859_1"?>
<!DOCTYPE Fibonacci_Numbers SYSTEM "fibonacci.dtd">
<Fibonacci_Numbers>
<fibonacci index="0">0</fibonacci>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
import org.apache.xerces.dom.*;
import org.apache.xml.serialize.*;
public class DOMPrettyPrinter {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document document = parser.getDocument();
OutputFormat format
= new OutputFormat(document, "UTF-8", true);
format.setLineSeparator("\r\n");
format.setIndenting(true);
format.setIndent(2);
format.setLineWidth(72);
format.setPreserveSpace(false);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(document);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}<?xml version="1.0" encoding="UTF-8"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization.
DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl/>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description/>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
Using the DOM to write documents automatically maintains well-formedness constraints
Validity is not automatically maintained.
This presentation: http://www.cafeconleche.org/slides/oop2003/xmlandjava
Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 9-13
XML in a Nutshell, 2nd Edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2002
ISBN 0-596-00292-0
DOM Level 2 Core Specification: http://www.w3.org/TR/DOM-Level-2-Core/
DOM Level 2 Traversal and Range Specification: http://www.w3.org/TR/DOM-Level-2-Traversal-Range/
There is no compelling reason for a Java API to manipulate XML to be complex, tricky, unintuitive, or a pain in the neck.--JDOM Mission Statement
Writing XML with JDOM
Reading XML through JDOM
The JDOM Classes
A Pure Java API for reading and writing XML Documents
A Java-oriented API for reading and writing XML Documents
A tree-oriented API for reading and writing XML Documents
A parser independent API for reading and writing XML Documents
Created by Brett McLaughlin and Jason Hunter. (James Duncan Davidson is an unindicted coconspirator.)
Alex Chafee, Alex Rosen, Bradley S. Huffman, Jools Enticknap, and Philip Nelson are also major contributors.
Open source with an Apache-like license
1.0 Beta 8 is current tarball from March 2002
Last ten months have fixed some implementation details, and made one major change to the API
This presentation is based on the current CVS version
org.jdomorg.jdom.inputorg.jdom.outputorg.jdom.adaptersorg.jdom.filterorg.jdom.transformThe classes that represent an XML document and its parts
Attribute
Comment
DocType
Document
Element
Text
CDATA (may be going away)
EntityRef
ProcessingInstruction
plus Verifier
plus assorted exceptions
Classes for reading a document into memory from a file or other source
DOMBuilder
SAXBuilder
BuilderErrorHandler
DefaultJDOMFactory
SAXHandler
The classes for writing a document to a file or other target
XMLOutputter
SAXOutputter
DOMOutputter
Classes and interfaces for masking out parts of a JDOM tree before navigating it:
Filter
ContentFilter
ElementFilter
Classes for hooking up JDOM to DOM implementations:
AbstractDOMAdapter
OracleV1DOMAdapter
OracleV2DOMAdapter
ProjectXDOMAdapter
XercesDOMAdapter
JAXPDOMAdapter
CrimsonDOMAdapter
XML4JDOMAdapter
You rarely need to access these directly.
Classes for XSLT support:
JDOMResult
JDOMSource
JDOM is for both input and output
New documents can be read from a stream or constructed in memory
An org.jdom.output.XMLOutputter sends
a document from memory to an
OutputStream or Writer
A JDOM document can also be sent to a
SAX ContentHandler or DOM org.w3c.dom.Document
for further processing with a different API
<?xml version="1.0"?>
<GREETING>
Hello JDOM!
</GREETING>import org.jdom.*;
import org.jdom.output.XMLOutputter;
import java.io.IOException;
public class HelloJDOM {
public static void main(String[] args) {
Element root = new Element("GREETING");
root.setText("Hello JDOM!");
Document doc = new Document(root);
// At this point the document only exists in memory.
// We still need to serialize it
XMLOutputter outputter = new XMLOutputter();
try {
outputter.output(doc, System.out);
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0" encoding="UTF-8"?>
<GREETING>Hello JDOM!</GREETING>
This is more or less what we wanted, modulo white space.
Here's the same program using DOM instead of JDOM. Which is simpler?
import java.io.*;
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.apache.xerces.dom.*;
import org.apache.xml.serialize.*;
public class HelloDOM {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory
= DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
DOMImplementation impl = builder.getDOMImplementation();
Document hello = impl.createDocument(null, "GREETING", null);
// ^^^^ ^^^^
// Namespace URI DocType
Element root = hello.getDocumentElement();
// We can't use a raw string. Instead we must first create
// a text node.
Text text = hello.createTextNode("Hello DOM!");
root.appendChild(text);
// Now that the document is created we need to *serialize* it
try {
OutputFormat format = new OutputFormat(hello);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(root);
}
catch (IOException e) {
System.err.println(e);
}
}
catch (DOMException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
System.out.println(e);
}
}
}
White space is significant in XML and therefore in JDOM.
import org.jdom.*;
import org.jdom.output.XMLOutputter;
import java.io.IOException;
public class PrettyHelloJDOM {
public static void main(String[] args) {
Element root = new Element("GREETING");
root.setText("\n Hello JDOM!\n");
Document doc = new Document(root);
// At this point the document only exists in memory.
// We still need to serialize it
XMLOutputter outputter = new XMLOutputter();
try {
outputter.output(doc, System.out);
}
catch (IOException e) {
System.err.println(e);
}
}
}
If white space is not significant in your application, you can instruct the outputter to clean it up for you.
<?xml version="1.0" encoding="UTF-8"?>
<GREETING>
Hello JDOM!
</GREETING>
Suppose we want data in an XML document that looks something like this:
<?xml version="1.0" encoding="UTF-8"?>
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>
import org.jdom.*;
import org.jdom.output.XMLOutputter;
import java.math.BigInteger;
import java.io.*;
public class FibonacciJDOM {
public static void main(String[] args) {
Element root = new Element("Fibonacci_Numbers");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
Element fibonacci = new Element("fibonacci");
Attribute index = new Attribute("index", String.valueOf(i));
fibonacci.setAttribute(index);
fibonacci.setText(low.toString());
root.addContent(fibonacci);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
Document doc = new Document(root);
// serialize it into a file
try {
FileOutputStream out
= new FileOutputStream("fibonacci_jdom.xml");
XMLOutputter serializer = new XMLOutputter();
serializer.output(doc, out);
out.flush();
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
Again, modulo white space this is correct
<?xml version="1.0" encoding="UTF-8"?>
<Fibonacci_Numbers><fibonacci index="1">1</fibonacci><fibonacci index="2">1</fibonacci><fibonacci index="3">2</fibonacci><fibonacci index="4">3</fibonacci><fibonacci index="5">5</fibonacci><fibonacci index="6">8</fibonacci><fibonacci index="7">13</fibonacci><fibonacci index="8">21</fibonacci><fibonacci index="9">34</fibonacci><fibonacci index="10">55</fibonacci><fibonacci index="11">89</fibonacci><fibonacci index="12">144</fibonacci><fibonacci index="13">233</fibonacci><fibonacci index="14">377</fibonacci><fibonacci index="15">610</fibonacci><fibonacci index="16">987</fibonacci><fibonacci index="17">1597</fibonacci><fibonacci index="18">2584</fibonacci><fibonacci index="19">4181</fibonacci><fibonacci index="20">6765</fibonacci><fibonacci index="21">10946</fibonacci><fibonacci index="22">17711</fibonacci><fibonacci index="23">28657</fibonacci><fibonacci index="24">46368</fibonacci><fibonacci index="25">75025</fibonacci></Fibonacci_Numbers>
Pass an indent string and whether or not to add newlines to the
XMLSerializer constructor.
import org.jdom.*;
import org.jdom.output.XMLOutputter;
import java.math.BigInteger;
import java.io.*;
public class PrettyFibonacciJDOM {
public static void main(String[] args) {
Element root = new Element("Fibonacci_Numbers");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
Element fibonacci = new Element("fibonacci");
Attribute index = new Attribute("index", String.valueOf(i));
fibonacci.setAttribute(index);
fibonacci.setText(low.toString());
root.addContent(fibonacci);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
Document doc = new Document(root);
// serialize it into a file
try {
FileOutputStream out
= new FileOutputStream("pretty_fibonacci_jdom.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, out);
out.flush();
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
Again, modulo white space this is correct
<?xml version="1.0" encoding="UTF-8"?>
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>
Suppose we have this DTD at the relative URL fibonacci.dtd:
<!ELEMENT Fibonacci_Numbers (fibonacci*)>
<!ELEMENT fibonacci (#PCDATA)>
<!ATTLIST fibonacci index CDATA #IMPLIED>We need this DOCTYPE declaration:
<!DOCTYPE Fibonacci_Numbers SYSTEM "fibonacci.dtd">Use the DocType class to insert a document type declaration
import java.math.BigInteger;
import java.io.*;
import org.jdom.*;
import org.jdom.output.XMLOutputter;
public class ValidFibonacci {
public static void main(String[] args) {
Element root = new Element("Fibonacci_Numbers");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
Element fibonacci = new Element("fibonacci");
Attribute index = new Attribute("index", String.valueOf(i));
fibonacci.setAttribute(index);
fibonacci.setText(low.toString());
BigInteger temp = high;
high = high.add(low);
low = temp;
root.addContent(fibonacci);
}
DocType type = new DocType("Fibonacci_Numbers", "fibonacci.dtd");
Document doc = new Document(root, type);
// serialize it into a file
try {
FileOutputStream out = new FileOutputStream("validfibonacci.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, out);
out.flush();
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE Fibonacci_Numbers SYSTEM "fibonacci.dtd">
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>
Supported as strings only
import java.math.BigInteger;
import java.io.*;
import org.jdom.*;
import org.jdom.output.XMLOutputter;
public class InternalValidFibonacci {
public static void main(String[] args) {
Element root = new Element("Fibonacci_Numbers");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
Element fibonacci = new Element("fibonacci");
Attribute index = new Attribute("index", String.valueOf(i));
fibonacci.setAttribute(index);
fibonacci.setText(low.toString());
BigInteger temp = high;
high = high.add(low);
low = temp;
root.addContent(fibonacci);
}
String dtd = "<!ELEMENT Fibonacci_Numbers (fibonacci*)>\r\n";
dtd += "<!ELEMENT fibonacci (#PCDATA)>\r\n";
dtd += "<!ATTLIST fibonacci index CDATA #IMPLIED>\r\n";
DocType type = new DocType("Fibonacci_Numbers");
type.setInternalSubset(dtd);
Document doc = new Document(root, type);
// serialize it into a file
try {
FileOutputStream out = new FileOutputStream("internalvalidfibonacci.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, out);
out.flush();
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE Fibonacci_Numbers [
<!ELEMENT Fibonacci_Numbers (fibonacci*)>
<!ELEMENT fibonacci (#PCDATA)>
<!ATTLIST fibonacci index CDATA #IMPLIED>
]>
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>
Suppose we want some MathML like this:
<?xml version="1.0" encoding="UTF-8"?>
<mathml:math xmlns:mathml="http://www.w3.org/1998/Math/MathML">
<mathml:mrow>
<mathml:mi>f(1)</mathml:mi>
<mathml:mo>=</mathml:mo>
<mathml:mn>1</mathml:mn>
</mathml:mrow>
<mathml:mrow>
<mathml:mi>f(2)</mathml:mi>
<mathml:mo>=</mathml:mo>
<mathml:mn>1</mathml:mn>
</mathml:mrow>
<mathml:mrow>
<mathml:mi>f(3)</mathml:mi>
<mathml:mo>=</mathml:mo>
<mathml:mn>2</mathml:mn>
</mathml:mrow>
</mathml:math>Do not use the qualified names like mathml:mn.
Instead use the prefixes mathml, local names like mn,
and URIs like http://www.w3.org/1998/Math/MathML
to create the elements.
Do not include xmlns attributes
like xmlns:mathml="http://www.w3.org/1998/Math/MathML".
XMLOutputter will
decide where to put the xmlns attributes
when the document is serialized.
import org.jdom.Element;
import org.jdom.Document;
import org.jdom.output.XMLOutputter;
import java.math.BigInteger;
import java.io.*;
public class PrefixedFibonacci {
public static void main(String[] args) {
Element root = new Element("math", "mathml",
"http://www.w3.org/1998/Math/MathML");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
Element mrow = new Element("mrow", "mathml",
"http://www.w3.org/1998/Math/MathML");
Element mi = new Element("mi", "mathml",
"http://www.w3.org/1998/Math/MathML");
mi.setText("f(" + i + ")");
mrow.addContent(mi);
Element mo = new Element("mo", "mathml",
"http://www.w3.org/1998/Math/MathML");
mo.setText("=");
mrow.addContent(mo);
Element mn = new Element("mn", "mathml",
"http://www.w3.org/1998/Math/MathML");
mn.setText(low.toString());
mrow.addContent(mn);
BigInteger temp = high;
high = high.add(low);
low = temp;
root.addContent(mrow);
}
Document doc = new Document(root);
// serialize it into a file
try {
FileOutputStream out
= new FileOutputStream("prefixed_fibonacci.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, out);
out.flush();
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
Suppose you want some MathML like this:
<?xml version="1.0" encoding="UTF-8"?>
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mrow>
<mi>f(1)</mi>
<mo>=</mo>
<mn>1</mn>
</mrow>
<mrow>
<mi>f(2)</mi>
<mo>=</mo>
<mn>1</mn>
</mrow>
<mrow>
<mi>f(3)</mi>
<mo>=</mo>
<mn>2</mn>
</mrow>
</math>
Do not use the local names like mn.
Instead use the local names like mn,
and URIs like http://www.w3.org/1998/Math/MathML
to create the elements.
Do not include xmlns attributes
like xmlns="http://www.w3.org/1998/Math/MathML".
XMLOutputter will
decide where to put the xmlns attribute
when the document is serialized.
import org.jdom.Element;
import org.jdom.Document;
import org.jdom.output.XMLOutputter;
import java.math.BigInteger;
import java.io.*;
public class UnprefixedFibonacci {
public static void main(String[] args) {
Element root = new Element("math",
"http://www.w3.org/1998/Math/MathML");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
Element mrow = new Element("mrow",
"http://www.w3.org/1998/Math/MathML");
Element mi = new Element("mi",
"http://www.w3.org/1998/Math/MathML");
mi.setText("f(" + i + ")");
mrow.addContent(mi);
Element mo = new Element("mo",
"http://www.w3.org/1998/Math/MathML");
mo.setText("=");
mrow.addContent(mo);
Element mn = new Element("mn",
"http://www.w3.org/1998/Math/MathML");
mn.setText(low.toString());
mrow.addContent(mn);
BigInteger temp = high;
high = high.add(low);
low = temp;
root.addContent(mrow);
}
Document doc = new Document(root);
// serialize it into a file
try {
FileOutputStream out
= new FileOutputStream("unprefixed_fibonacci.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, out);
out.flush();
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
Surname FirstName Team Position Games Played Games Started AtBats Runs Hits Doubles Triples Home runs RBI Stolen Bases Caught Stealing Sacrifice Hits Sacrifice Flies Errors PB Walks Strike outs Hit by pitch Anderson Garret ANA Outfield 156 151 622 62 183 41 7 15 79 8 3 3 3 6 0 29 80 1 Baughman Justin ANA Second Base 62 54 196 24 50 9 1 1 20 10 4 5 3 8 0 6 36 1 Bolick Frank ANA Third Base 21 11 45 3 7 2 0 1 2 0 0 0 0 0 0 11 8 0 Disarcina Gary ANA Shortstop 157 155 551 73 158 39 3 3 56 12 7 12 3 14 0 21 51 8 Edmonds Jim ANA Outfield 154 150 599 115 184 42 1 25 91 7 5 1 1 5 0 57 114 1 Erstad Darin ANA Outfield 133 129 537 84 159 39 3 19 82 20 6 1 3 3 0 43 77 6 Garcia Carlos ANA Second Base 19 10 35 4 5 1 0 0 0 2 0 1 0 1 0 3 11 1 Glaus Troy ANA Third Base 48 45 165 19 36 9 0 1 23 1 0 0 2 7 0 15 51 0 Greene Todd ANA Outfield 29 15 71 3 18 4 0 1 7 0 0 0 0 0 0 2 20 0 Helfand Eric ANA Catcher 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Hollins Dave ANA Third Base 101 98 363 60 88 16 2 11 39 11 3 2 2 17 0 44 69 7 Jefferies Gregg ANA Outfield 19 18 72 7 25 6 0 1 10 1 0 0 0 0 0 0 5 0 Johnson Mark ANA First Base 10 2 14 1 1 0 0 0 0 0 0 0 0 0 0 0 6 0 Kreuter Chad ANA Catcher 96 74 252 27 63 10 1 2 33 1 0 5 1 9 5 33 49 3 Martin Norberto ANA Second Base 79 50 195 20 42 2 0 1 13 3 1 3 2 4 0 6 29 0 Mashore Damon ANA Outfield 43 24 98 13 23 6 0 2 11 1 0 1 0 0 0 9 22 3 Molina Ben ANA Catcher 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Nevin Phil ANA Catcher 75 65 237 27 54 8 1 8 27 0 0 0 2 5 20 17 67 5 O'Brien Charlie ANA Catcher 62 58 175 13 45 9 0 4 18 0 0 3 3 4 1 10 33 2 Palmeiro Orlando ANA Outfield 74 34 165 28 53 7 2 0 21 5 4 7 0 0 0 20 11 0 Pritchett Chris ANA First Base 31 19 80 12 23 2 1 2 8 2 0 0 0 1 0 4 16 0 Salmon Tim ANA Designated Hitter 136 130 463 84 139 28 1 26 88 0 1 0 10 2 0 90 100 3 Shipley Craig ANA Third Base 77 32 147 18 38 7 1 2 17 0 4 4 1 3 0 5 22 5 Velarde Randy ANA Second Base 51 50 188 29 49 13 1 4 26 7 2 0 1 4 0 34 42 1 Walbeck Matt ANA Catcher 108 91 338 41 87 15 2 6 46 1 1 5 5 7 8 30 68 2 Williams Reggie ANA Outfield 29 7 36 7 13 1 0 1 5 3 3 1 0 0 0 7 11 1
import java.io.*;
import org.jdom.*;
import org.jdom.output.XMLOutputter;
public class JDOMBaseballTabToXML {
public static void main(String[] args) {
Element root = new Element("players");
try {
FileInputStream fin = new FileInputStream(args[0]);
BufferedReader in
= new BufferedReader(new InputStreamReader(fin));
String playerStats;
while ((playerStats = in.readLine()) != null) {
String[] stats = splitLine(playerStats);
Element player = new Element("player");
Element first_name = new Element("first_name");
first_name.setText(stats[1]);
player.addContent(first_name);
Element surname = new Element("surname");
surname.setText(stats[0]);
player.addContent(surname);
Element games_played = new Element("games_played");
games_played.setText(stats[4]);
player.addContent(games_played);
Element at_bats = new Element("at_bats");
at_bats.setText(stats[6]);
player.addContent(at_bats);
Element runs = new Element("runs");
runs.setText(stats[7]);
player.addContent(runs);
Element hits = new Element("hits");
hits.setText(stats[8]);
player.addContent(hits);
Element doubles = new Element("doubles");
doubles.setText(stats[9]);
player.addContent(doubles);
Element triples = new Element("triples");
triples.setText(stats[10]);
player.addContent(triples);
Element home_runs = new Element("home_runs");
home_runs.setText(stats[11]);
player.addContent(home_runs);
Element runs_batted_in = new Element("runs_batted_in");
runs_batted_in.setText(stats[12]);
player.addContent(runs_batted_in);
Element stolen_bases = new Element("stolen_bases");
stolen_bases.setText(stats[13]);
player.addContent(stolen_bases);
Element caught_stealing = new Element("caught_stealing");
caught_stealing.setText(stats[14]);
player.addContent(caught_stealing);
Element sacrifice_hits = new Element("sacrifice_hits");
sacrifice_hits.setText(stats[15]);
player.addContent(sacrifice_hits);
Element sacrifice_flies = new Element("sacrifice_flies");
sacrifice_flies.setText(stats[16]);
player.addContent(sacrifice_flies);
Element errors = new Element("errors");
errors.setText(stats[17]);
player.addContent(errors);
Element passed_by_ball = new Element("passed_by_ball");
passed_by_ball.setText(stats[18]);
player.addContent(passed_by_ball);
Element walks = new Element("walks");
walks.setText(stats[19]);
player.addContent(walks);
Element strike_outs = new Element("strike_outs");
strike_outs.setText(stats[20]);
player.addContent(strike_outs);
Element hit_by_pitch = new Element("hit_by_pitch");
hit_by_pitch.setText(stats[21]);
player.addContent(hit_by_pitch);
root.addContent(player);
}
Document doc = new Document(root);
// serialize it into a file
FileOutputStream fout
= new FileOutputStream("baseballstats.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, fout);
fout.flush();
fout.close();
in.close();
}
catch (IOException e) {
System.err.println(e);
}
catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Usage: java BaseballTabToXML input_file.tab");
}
}
public static String[] splitLine(String playerStats) {
// count the number of tabs
int numTabs = 0;
for (int i = 0; i < playerStats.length(); i++) {
if (playerStats.charAt(i) == '\t') numTabs++;
}
int numFields = numTabs + 1;
String[] fields = new String[numFields];
int position = 0;
for (int i = 0; i < numFields; i++) {
StringBuffer field = new StringBuffer();
while (position < playerStats.length()
&& playerStats.charAt(position++) != '\t') {
field.append(playerStats.charAt(position-1));
}
fields[i] = field.toString();
}
return fields;
}
}<?xml version="1.0"?>
<players>
<player>
<first_name>FirstName</first_name>
<surname>Surname</surname>
<games_played>Games Played</games_played>
<at_bats>AtBats</at_bats>
<runs>Runs</runs>
<hits>Hits</hits>
<doubles>Doubles</doubles>
<triples>Triples</triples>
<home_runs>Home runs</home_runs>
<stolen_bases>RBI</stolen_bases>
<caught_stealing>Caught Stealing</caught_stealing>
<sacrifice_hits>Sacrifice Hits</sacrifice_hits>
<sacrifice_flies>Sacrifice Flies</sacrifice_flies>
<errors>Errors</errors>
<passed_by_ball>PB</passed_by_ball>
<walks>Walks</walks>
<strike_outs>Strike outs</strike_outs>
<hit_by_pitch>Hit by pitch</hit_by_pitch>
</player>
<player>
<first_name>Garret </first_name>
<surname>Anderson</surname>
<games_played>156</games_played>
<at_bats>622</at_bats>
<runs>62</runs>
<hits>183</hits>
<doubles>41</doubles>
<triples>7</triples>
<home_runs>15</home_runs>
<stolen_bases>79</stolen_bases>
<caught_stealing>3</caught_stealing>
<sacrifice_hits>3</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>6</errors>
<passed_by_ball>0</passed_by_ball>
<walks>29</walks>
<strike_outs>80</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Justin </first_name>
<surname>Baughman</surname>
<games_played>62</games_played>
<at_bats>196</at_bats>
<runs>24</runs>
<hits>50</hits>
<doubles>9</doubles>
<triples>1</triples>
<home_runs>1</home_runs>
<stolen_bases>20</stolen_bases>
<caught_stealing>4</caught_stealing>
<sacrifice_hits>5</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>8</errors>
<passed_by_ball>0</passed_by_ball>
<walks>6</walks>
<strike_outs>36</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Frank </first_name>
<surname>Bolick</surname>
<games_played>21</games_played>
<at_bats>45</at_bats>
<runs>3</runs>
<hits>7</hits>
<doubles>2</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>2</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>11</walks>
<strike_outs>8</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Gary </first_name>
<surname>Disarcina</surname>
<games_played>157</games_played>
<at_bats>551</at_bats>
<runs>73</runs>
<hits>158</hits>
<doubles>39</doubles>
<triples>3</triples>
<home_runs>3</home_runs>
<stolen_bases>56</stolen_bases>
<caught_stealing>7</caught_stealing>
<sacrifice_hits>12</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>14</errors>
<passed_by_ball>0</passed_by_ball>
<walks>21</walks>
<strike_outs>51</strike_outs>
<hit_by_pitch>8</hit_by_pitch>
</player>
<player>
<first_name>Jim </first_name>
<surname>Edmonds</surname>
<games_played>154</games_played>
<at_bats>599</at_bats>
<runs>115</runs>
<hits>184</hits>
<doubles>42</doubles>
<triples>1</triples>
<home_runs>25</home_runs>
<stolen_bases>91</stolen_bases>
<caught_stealing>5</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>5</errors>
<passed_by_ball>0</passed_by_ball>
<walks>57</walks>
<strike_outs>114</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Darin </first_name>
<surname>Erstad</surname>
<games_played>133</games_played>
<at_bats>537</at_bats>
<runs>84</runs>
<hits>159</hits>
<doubles>39</doubles>
<triples>3</triples>
<home_runs>19</home_runs>
<stolen_bases>82</stolen_bases>
<caught_stealing>6</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>3</errors>
<passed_by_ball>0</passed_by_ball>
<walks>43</walks>
<strike_outs>77</strike_outs>
<hit_by_pitch>6</hit_by_pitch>
</player>
<player>
<first_name>Carlos </first_name>
<surname>Garcia</surname>
<games_played>19</games_played>
<at_bats>35</at_bats>
<runs>4</runs>
<hits>5</hits>
<doubles>1</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>1</errors>
<passed_by_ball>0</passed_by_ball>
<walks>3</walks>
<strike_outs>11</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Troy </first_name>
<surname>Glaus</surname>
<games_played>48</games_played>
<at_bats>165</at_bats>
<runs>19</runs>
<hits>36</hits>
<doubles>9</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>23</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>7</errors>
<passed_by_ball>0</passed_by_ball>
<walks>15</walks>
<strike_outs>51</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Todd </first_name>
<surname>Greene</surname>
<games_played>29</games_played>
<at_bats>71</at_bats>
<runs>3</runs>
<hits>18</hits>
<doubles>4</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>7</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>2</walks>
<strike_outs>20</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Eric </first_name>
<surname>Helfand</surname>
<games_played>0</games_played>
<at_bats>0</at_bats>
<runs>0</runs>
<hits>0</hits>
<doubles>0</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>0</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Dave </first_name>
<surname>Hollins</surname>
<games_played>101</games_played>
<at_bats>363</at_bats>
<runs>60</runs>
<hits>88</hits>
<doubles>16</doubles>
<triples>2</triples>
<home_runs>11</home_runs>
<stolen_bases>39</stolen_bases>
<caught_stealing>3</caught_stealing>
<sacrifice_hits>2</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>17</errors>
<passed_by_ball>0</passed_by_ball>
<walks>44</walks>
<strike_outs>69</strike_outs>
<hit_by_pitch>7</hit_by_pitch>
</player>
<player>
<first_name>Gregg </first_name>
<surname>Jefferies</surname>
<games_played>19</games_played>
<at_bats>72</at_bats>
<runs>7</runs>
<hits>25</hits>
<doubles>6</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>10</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>5</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Mark </first_name>
<surname>Johnson</surname>
<games_played>10</games_played>
<at_bats>14</at_bats>
<runs>1</runs>
<hits>1</hits>
<doubles>0</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>6</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Chad </first_name>
<surname>Kreuter</surname>
<games_played>96</games_played>
<at_bats>252</at_bats>
<runs>27</runs>
<hits>63</hits>
<doubles>10</doubles>
<triples>1</triples>
<home_runs>2</home_runs>
<stolen_bases>33</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>5</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>9</errors>
<passed_by_ball>5</passed_by_ball>
<walks>33</walks>
<strike_outs>49</strike_outs>
<hit_by_pitch>3</hit_by_pitch>
</player>
<player>
<first_name>Norberto </first_name>
<surname>Martin</surname>
<games_played>79</games_played>
<at_bats>195</at_bats>
<runs>20</runs>
<hits>42</hits>
<doubles>2</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>13</stolen_bases>
<caught_stealing>1</caught_stealing>
<sacrifice_hits>3</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>4</errors>
<passed_by_ball>0</passed_by_ball>
<walks>6</walks>
<strike_outs>29</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Damon </first_name>
<surname>Mashore</surname>
<games_played>43</games_played>
<at_bats>98</at_bats>
<runs>13</runs>
<hits>23</hits>
<doubles>6</doubles>
<triples>0</triples>
<home_runs>2</home_runs>
<stolen_bases>11</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>9</walks>
<strike_outs>22</strike_outs>
<hit_by_pitch>3</hit_by_pitch>
</player>
<player>
<first_name>Ben </first_name>
<surname>Molina</surname>
<games_played>2</games_played>
<at_bats>1</at_bats>
<runs>0</runs>
<hits>0</hits>
<doubles>0</doubles>
<triples>0</triples>
<home_runs>0</home_runs>
<stolen_bases>0</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>0</walks>
<strike_outs>0</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Phil </first_name>
<surname>Nevin</surname>
<games_played>75</games_played>
<at_bats>237</at_bats>
<runs>27</runs>
<hits>54</hits>
<doubles>8</doubles>
<triples>1</triples>
<home_runs>8</home_runs>
<stolen_bases>27</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>2</sacrifice_flies>
<errors>5</errors>
<passed_by_ball>20</passed_by_ball>
<walks>17</walks>
<strike_outs>67</strike_outs>
<hit_by_pitch>5</hit_by_pitch>
</player>
<player>
<first_name>Charlie </first_name>
<surname>Obrien</surname>
<games_played>62</games_played>
<at_bats>175</at_bats>
<runs>13</runs>
<hits>45</hits>
<doubles>9</doubles>
<triples>0</triples>
<home_runs>4</home_runs>
<stolen_bases>18</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>3</sacrifice_hits>
<sacrifice_flies>3</sacrifice_flies>
<errors>4</errors>
<passed_by_ball>1</passed_by_ball>
<walks>10</walks>
<strike_outs>33</strike_outs>
<hit_by_pitch>2</hit_by_pitch>
</player>
<player>
<first_name>Orlando </first_name>
<surname>Palmeiro</surname>
<games_played>74</games_played>
<at_bats>165</at_bats>
<runs>28</runs>
<hits>53</hits>
<doubles>7</doubles>
<triples>2</triples>
<home_runs>0</home_runs>
<stolen_bases>21</stolen_bases>
<caught_stealing>4</caught_stealing>
<sacrifice_hits>7</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>20</walks>
<strike_outs>11</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Chris </first_name>
<surname>Pritchett</surname>
<games_played>31</games_played>
<at_bats>80</at_bats>
<runs>12</runs>
<hits>23</hits>
<doubles>2</doubles>
<triples>1</triples>
<home_runs>2</home_runs>
<stolen_bases>8</stolen_bases>
<caught_stealing>0</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>1</errors>
<passed_by_ball>0</passed_by_ball>
<walks>4</walks>
<strike_outs>16</strike_outs>
<hit_by_pitch>0</hit_by_pitch>
</player>
<player>
<first_name>Tim </first_name>
<surname>Salmon</surname>
<games_played>136</games_played>
<at_bats>463</at_bats>
<runs>84</runs>
<hits>139</hits>
<doubles>28</doubles>
<triples>1</triples>
<home_runs>26</home_runs>
<stolen_bases>88</stolen_bases>
<caught_stealing>1</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>10</sacrifice_flies>
<errors>2</errors>
<passed_by_ball>0</passed_by_ball>
<walks>90</walks>
<strike_outs>100</strike_outs>
<hit_by_pitch>3</hit_by_pitch>
</player>
<player>
<first_name>Craig </first_name>
<surname>Shipley</surname>
<games_played>77</games_played>
<at_bats>147</at_bats>
<runs>18</runs>
<hits>38</hits>
<doubles>7</doubles>
<triples>1</triples>
<home_runs>2</home_runs>
<stolen_bases>17</stolen_bases>
<caught_stealing>4</caught_stealing>
<sacrifice_hits>4</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>3</errors>
<passed_by_ball>0</passed_by_ball>
<walks>5</walks>
<strike_outs>22</strike_outs>
<hit_by_pitch>5</hit_by_pitch>
</player>
<player>
<first_name>Randy </first_name>
<surname>Velarde</surname>
<games_played>51</games_played>
<at_bats>188</at_bats>
<runs>29</runs>
<hits>49</hits>
<doubles>13</doubles>
<triples>1</triples>
<home_runs>4</home_runs>
<stolen_bases>26</stolen_bases>
<caught_stealing>2</caught_stealing>
<sacrifice_hits>0</sacrifice_hits>
<sacrifice_flies>1</sacrifice_flies>
<errors>4</errors>
<passed_by_ball>0</passed_by_ball>
<walks>34</walks>
<strike_outs>42</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
<player>
<first_name>Matt </first_name>
<surname>Walbeck</surname>
<games_played>108</games_played>
<at_bats>338</at_bats>
<runs>41</runs>
<hits>87</hits>
<doubles>15</doubles>
<triples>2</triples>
<home_runs>6</home_runs>
<stolen_bases>46</stolen_bases>
<caught_stealing>1</caught_stealing>
<sacrifice_hits>5</sacrifice_hits>
<sacrifice_flies>5</sacrifice_flies>
<errors>7</errors>
<passed_by_ball>8</passed_by_ball>
<walks>30</walks>
<strike_outs>68</strike_outs>
<hit_by_pitch>2</hit_by_pitch>
</player>
<player>
<first_name>Reggie </first_name>
<surname>Williams</surname>
<games_played>29</games_played>
<at_bats>36</at_bats>
<runs>7</runs>
<hits>13</hits>
<doubles>1</doubles>
<triples>0</triples>
<home_runs>1</home_runs>
<stolen_bases>5</stolen_bases>
<caught_stealing>3</caught_stealing>
<sacrifice_hits>1</sacrifice_hits>
<sacrifice_flies>0</sacrifice_flies>
<errors>0</errors>
<passed_by_ball>0</passed_by_ball>
<walks>7</walks>
<strike_outs>11</strike_outs>
<hit_by_pitch>1</hit_by_pitch>
</player>
</players>
import java.io.*;
import org.jdom.*;
import org.jdom.output.XMLOutputter;
public class BaseballTabToXMLShortcut {
public static void main(String[] args) {
Element root = new Element("players");
try {
FileInputStream fin = new FileInputStream(args[0]);
BufferedReader in
= new BufferedReader(new InputStreamReader(fin));
String playerStats;
while ((playerStats = in.readLine()) != null) {
String[] stats = splitLine(playerStats);
Element player = new Element("player");
player.addContent((new Element("first_name")).setText(stats[1]));
player.addContent((new Element("surname")).setText(stats[0]));
player.addContent((new Element("games_played")).setText(stats[4]));
player.addContent((new Element("at_bats")).setText(stats[6]));
player.addContent((new Element("runs")).setText(stats[7]));
player.addContent((new Element("hits")).setText(stats[8]));
player.addContent((new Element("doubles")).setText(stats[9]));
player.addContent((new Element("triples")).setText(stats[10]));
player.addContent((new Element("home_runs")).setText(stats[11]));
player.addContent((new Element("runs_batted_in")).setText(stats[12]));
player.addContent((new Element("stolen_bases")).setText(stats[13]));
player.addContent((new Element("caught_stealing")).setText(stats[14]));
player.addContent((new Element("sacrifice_hits")).setText(stats[15]));
player.addContent((new Element("sacrifice_flies")).setText(stats[16]));
player.addContent((new Element("errors")).setText(stats[17]));
player.addContent((new Element("passed_by_ball")).setText(stats[18]));
player.addContent((new Element("walks")).setText(stats[19]));
player.addContent((new Element("strike_outs")).setText(stats[20]));
player.addContent((new Element("hit_by_pitch")).setText(stats[21]));
root.addContent(player);
}
Document doc = new Document(root);
// serialize it into a file
FileOutputStream fout
= new FileOutputStream("baseballstats.xml");
XMLOutputter serializer = new XMLOutputter();
serializer.output(doc, fout);
fout.flush();
fout.close();
in.close();
}
catch (IOException e) {
System.err.println(e);
}
catch (ArrayIndexOutOfBoundsException e) {
System.out.println(
"Usage: java BaseballTabToXML input_file.tab");
}
}
public static String[] splitLine(String playerStats) {
// count the number of tabs
int numTabs = 0;
for (int i = 0; i < playerStats.length(); i++) {
if (playerStats.charAt(i) == '\t') numTabs++;
}
int numFields = numTabs + 1;
String[] fields = new String[numFields];
int position = 0;
for (int i = 0; i < numFields; i++) {
StringBuffer field = new StringBuffer();
while (position < playerStats.length()
&& playerStats.charAt(position++) != '\t') {
field.append(playerStats.charAt(position-1));
}
fields[i] = field.toString();
}
return fields;
}
}import java.io.*;
import java.text.*;
import java.util.*;
import org.jdom.*;
import org.jdom.output.XMLOutputter;
public class JDOMBattingAverage {
public static void main(String[] args) {
Element root = new Element("players");
try {
FileInputStream fin = new FileInputStream(args[0]);
BufferedReader in
= new BufferedReader(new InputStreamReader(fin));
String playerStats;
// for formatting batting averages
DecimalFormat averages = (DecimalFormat)
NumberFormat.getNumberInstance(Locale.US);
averages.setMaximumFractionDigits(3);
averages.setMinimumFractionDigits(3);
averages.setMinimumIntegerDigits(0);
while ((playerStats = in.readLine()) != null) {
String[] stats = splitLine(playerStats);
String formattedAverage;
try {
int atBats = Integer.parseInt(stats[6]);
int hits = Integer.parseInt(stats[8]);
if (atBats <= 0) formattedAverage = "N/A";
else {
double average = hits / (double) atBats;
formattedAverage = averages.format(average);
}
}
catch (Exception e) {
// skip this player
continue;
}
Element player = new Element("player");
Element first_name = new Element("first_name");
first_name.setText(stats[1]);
player.addContent(first_name);
Element surname = new Element("surname");
surname.setText(stats[0]);
player.addContent(surname);
Element battingAverage = new Element("batting_average");
battingAverage.setText(formattedAverage);
player.addContent(battingAverage);
root.addContent(player);
}
Document doc = new Document(root);
// serialize it into a file
FileOutputStream fout
= new FileOutputStream("battingaverages.xml");
XMLOutputter serializer = new XMLOutputter(" ", true);
serializer.output(doc, fout);
fout.flush();
fout.close();
in.close();
}
catch (IOException e) {
System.err.println(e);
}
catch (ArrayIndexOutOfBoundsException e) {
System.out.println("Usage: java JDOMBattingAverage input_file.tab");
}
}
public static String[] splitLine(String playerStats) {
// count the number of tabs
int numTabs = 0;
for (int i = 0; i < playerStats.length(); i++) {
if (playerStats.charAt(i) == '\t') numTabs++;
}
int numFields = numTabs + 1;
String[] fields = new String[numFields];
int position = 0;
for (int i = 0; i < numFields; i++) {
StringBuffer field = new StringBuffer();
while (position < playerStats.length()
&& playerStats.charAt(position++) != '\t') {
field.append(playerStats.charAt(position-1));
}
fields[i] = field.toString();
}
return fields;
}
}<?xml version="1.0"?>
<players>
<player>
<first_name>Garret </first_name>
<surname>Anderson</surname>
<batting_average>.294</batting_average>
</player>
<player>
<first_name>Justin </first_name>
<surname>Baughman</surname>
<batting_average>.255</batting_average>
</player>
<player>
<first_name>Frank </first_name>
<surname>Bolick</surname>
<batting_average>.156</batting_average>
</player>
<player>
<first_name>Gary </first_name>
<surname>Disarcina</surname>
<batting_average>.287</batting_average>
</player>
<player>
<first_name>Jim </first_name>
<surname>Edmonds</surname>
<batting_average>.307</batting_average>
</player>
<player>
<first_name>Darin </first_name>
<surname>Erstad</surname>
<batting_average>.296</batting_average>
</player>
<player>
<first_name>Carlos </first_name>
<surname>Garcia</surname>
<batting_average>.143</batting_average>
</player>
<player>
<first_name>Troy </first_name>
<surname>Glaus</surname>
<batting_average>.218</batting_average>
</player>
<player>
<first_name>Todd </first_name>
<surname>Greene</surname>
<batting_average>.254</batting_average>
</player>
<player>
<first_name>Eric </first_name>
<surname>Helfand</surname>
<batting_average>N/A</batting_average>
</player>
<player>
<first_name>Dave </first_name>
<surname>Hollins</surname>
<batting_average>.242</batting_average>
</player>
<player>
<first_name>Gregg </first_name>
<surname>Jefferies</surname>
<batting_average>.347</batting_average>
</player>
<player>
<first_name>Mark </first_name>
<surname>Johnson</surname>
<batting_average>.071</batting_average>
</player>
<player>
<first_name>Chad </first_name>
<surname>Kreuter</surname>
<batting_average>.250</batting_average>
</player>
<player>
<first_name>Norberto </first_name>
<surname>Martin</surname>
<batting_average>.215</batting_average>
</player>
<player>
<first_name>Damon </first_name>
<surname>Mashore</surname>
<batting_average>.235</batting_average>
</player>
<player>
<first_name>Ben </first_name>
<surname>Molina</surname>
<batting_average>.000</batting_average>
</player>
<player>
<first_name>Phil </first_name>
<surname>Nevin</surname>
<batting_average>.228</batting_average>
</player>
<player>
<first_name>Charlie </first_name>
<surname>Obrien</surname>
<batting_average>.257</batting_average>
</player>
<player>
<first_name>Orlando </first_name>
<surname>Palmeiro</surname>
<batting_average>.321</batting_average>
</player>
<player>
<first_name>Chris </first_name>
<surname>Pritchett</surname>
<batting_average>.288</batting_average>
</player>
<player>
<first_name>Tim </first_name>
<surname>Salmon</surname>
<batting_average>.300</batting_average>
</player>
<player>
<first_name>Craig </first_name>
<surname>Shipley</surname>
<batting_average>.259</batting_average>
</player>
<player>
<first_name>Randy </first_name>
<surname>Velarde</surname>
<batting_average>.261</batting_average>
</player>
<player>
<first_name>Matt </first_name>
<surname>Walbeck</surname>
<batting_average>.257</batting_average>
</player>
<player>
<first_name>Reggie </first_name>
<surname>Williams</surname>
<batting_average>.361</batting_average>
</player>
</players>
You don't need to worry about well-formedness rules
Very configurable output
You can pick any encoding Java supports.
Validity is not automatically maintained.
The stereotypical "Desperate Perl Hacker" (DPH) is supposed to be able to write an XML parser in a weekend.
The parser does the hard work for you.
Your code reads the document through by hooking up JDOM to the parser.
JDOM can connect to any parser that supports SAX or DOM.
Any SAX or DOM compatible parser including:
Apache XML Project's Xerces Java: http://xml.apache.org/xerces-j/index.html
Oracle's XML Parser for Java: http://technet.oracle.com/tech/xml/parser_java2
Sun's Java API for XML http://java.sun.com/products/xml
Construct an org.jdom.input.SAXBuilder; no parser specific code is needed!
Invoke the builder's build() method to
build a Document object from a
Reader
InputStream
URL
File
String containing a SYSTEM ID
If there's a problem building the document, a JDOMException is thrown
Work with the resulting Document object
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import java.io.IOException;
public class JDOMChecker {
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java JDOMChecker URL1 URL2...");
}
SAXBuilder builder = new SAXBuilder();
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
builder.build(args[i]);
// If no exception is thrown, then there are
// no well-formedness errors.
System.out.println(args[i] + " is well-formed.");
}
// indicates a well-formedness error
catch (JDOMException e) {
System.out.println(args[i] + " is not well-formed.");
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not check " + args[i]);
System.out.println("because " + e.getMessage());
}
}
}
}
% java JDOMChecker shortlogs.xml HelloJDOM.java shortlogs.xml is well formed. HelloJDOM.java is not well formed. The markup in the document preceding the root element must be well-formed.: Error on line 1 of XML document: The markup in the document preceding the root element must be well-formed.
Not all parsers are validating but Xerces-J is.
Validity errors are not fatal; therefore they do not necessarily cause
a JDOMException
However, you can tell the builder you want it to validate by passing
true to its constructor:
SAXBuilder builder = new SAXBuilder(true);
import org.jdom.input.*;
import org.jdom.JDOMException;
import org.xml.sax.*;
import java.io.*;
public class JDOMValidator {
public static void main(String[] args) {
SAXBuilder parser = new SAXBuilder(true);
if (args.length == 0) {
System.out.println("Usage: java JDOMValidator URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.build(args[i]);
// If there are no well-formedness errors,
// then no exception is thrown
System.out.println(args[i] + " is well formed.");
}
catch (JDOMException e) {
System.out.println(args[i] + " is not valid.");
System.out.println(e.getMessage());
}
}
}
}
% java JDOMValidator invalid_fibonacci.xml invalid_fibonacci.xml is not valid. Element type "title" must be declared.: Error on line 8 of XML document: Element type "title" must be declared. % java JDOMValidator validfibonacci.xml validfibonacci.xml is valid.
UserLand's RSS based list of Web logs at http://static.userland.com/weblogMonitor/logs.xml:
<?xml version="1.0"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl></imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description></description>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
Design Decisions
Should we return an array, an Enumeration,
a List, or what?
Perhaps we should use multiple threads?
We can easily find out how many URLs there will be when we start parsing.
Single threaded by nature; no benefit to mutiple threads since no data will be available until the entire document has been read and parsed.
The character data of each url
element needs to be read.
Everything else can be ignored.
The format is very straight-forward so we don't need to traverse the entire tree.
The XML parsing is so straight-forward it can be done inside one method. No extra class is required.
import org.jdom.*;
import org.jdom.input.SAXBuilder;
import java.util.*;
import java.net.*;
public class WeblogsJDOM {
public static String DEFAULT_SYSTEM_ID
= "http://static.userland.com/weblogMonitor/logs.xml";
public static List listChannels() throws JDOMException {
return listChannels(DEFAULT_SYSTEM_ID);
}
public static List listChannels(String systemID)
throws JDOMException, NullPointerException {
if (systemID == null) {
throw new NullPointerException("URL must be non-null");
}
SAXBuilder builder = new SAXBuilder();
// Load the entire document into memory
// from the network or file system
Document doc = builder.build(systemID);
// Descend the tree and find the URLs. It helps that
// the document has a very regular structure.
Element weblogs = doc.getRootElement();
List logs = weblogs.getChildren("log");
Vector urls = new Vector(logs.size());
Iterator iterator = logs.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
Element log = (Element) o;
try {
// This will probably be changed to
// getElement() or getChildElement()
Element url = log.getChild("url");
if (url == null) continue;
String content = url.getTextTrim();
URL u = new URL(content);
urls.addElement(u);
}
catch (MalformedURLException e) {
// bad input data from one third party; just ignore it
}
}
return urls;
}
public static void main(String[] args) {
try {
List urls;
if (args.length > 0) {
urls = listChannels(args[0]);
}
else {
urls = listChannels();
}
Iterator iterator = urls.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
catch (/* Unexpected */ Exception e) {
e.printStackTrace();
}
}
}
% java WeblogsJDOM
http://2020Hindsight.editthispage.com/
http://www.sff.net/people/mitchw/weblog/weblog.htp
http://nate.weblogs.com/
http://plugins.launchpoint.net
http://404.psistorm.net
http://home.att.net/~geek9000
http://daubnet.tzo.com/weblog
several hundred more...
The classes that represent an XML document and its parts
Document
Element
Attribute
Comment
DocType
EntityRef
Text
CDATA
ProcessingInstruction
Verifier
plus assorted exceptions
The root node containing the entire document; not the same as the root element
Contains:
one element
zero or more processing instructions
zero or more comments
zero or one document type declarations
package org.jdom;
public class Document implements Serializable, Cloneable {
protected ContentList content;
protected DocType docType;
public Document()
public Document(Element rootElement, DocType docType)
public Document(Element rootElement)
public Document(List newContent, DocType docType)
public Document(List content)
public boolean hasRootElement()
public Element getRootElement()
public Document setRootElement(Element rootElement)
public Element detachRootElement()
public DocType getDocType()
public Document setDocType(DocType docType)
public Document addContent(ProcessingInstruction pi)
public Document addContent(Comment comment)
public List getContent()
public List getContent(Filter filter)
public Document setContent(List newContent)
public boolean removeContent(ProcessingInstruction pi)
public boolean removeContent(Comment comment)
// Java utility methods
public String toString()
public final boolean equals(Object ob)
public final int hashCode()
public Object clone()
}import org.jdom.Document;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import org.jdom.output.XMLOutputter;
import java.io.IOException;
public class XMLPrinter {
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java XMLPrinter URL1 URL2...");
}
SAXBuilder builder = new SAXBuilder();
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
Document doc = builder.build(args[i]);
System.out.println("*************" + args[i]
+ "*************");
XMLOutputter outputter = new XMLOutputter();
outputter.output(doc, System.out);
}
// indicates a well-formedness or other error
catch (JDOMException e) {
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage());
}
// shouldn't happen because System.out eats exceptions
catch (IOException e) {
System.out.println(e.getMessage());
}
}
}
}% java XMLPrinter shortlogs.xml
*************shortlogs.xml*************
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"><weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl />
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description />
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
Represents a complete element including its start-tag, end-tag, and content
Contains:
Child Elements
Processing Instructions
Comments
Text
CDATA sections
Entity references
JDOM enforces restrictions on element names and possibly values; e.g. name cannot contain start with a digit.
The content is stored as a java.util.List
which contains
One Text object per text node
One Element object per child element
One Comment object per comment
One CDATA object per CDATA section
One ProcessingInstruction object per processing instruction
Use the regular methods of java.util.List to
add, remove, and inspect the contents of an element
Since the methods of java.util.List expect to work
with Object objects, casting back to JDOM types
and String is frequent
Various utility methods mean you don't always have to work with the full list.
Attributes and namespaces are available as separate lists since these are not children.
package org.jdom;
public class Element implements Serializable, Cloneable {
protected String name;
protected transient Namespace namespace;
protected Object parent;
protected AttributeList attributes;
protected transient List additionalNamespaces
protected List content;
protected Element() {}
public Element(String name, Namespace namespace) {}
public Element(String name) {}
public Element(String name, String uri) {}
public Element(String name, String prefix, String uri) {}
public String getName() {}
public Namespace getNamespace() {}
public Namespace getNamespace(String prefix) {}
public String getNamespacePrefix() {}
public String getNamespaceURI() {}
public String getQualifiedName() {}
public Element getParent() {}
protected Element setParent(Element parent) {}
public boolean isRootElement() {}
protected Element setIsRootElement(boolean isRootElement) {}
public Element setChildren(List children)
protected Element setDocument(Document document)
public Element setName(String name)
public Element setNamespace(Namespace namespace)
public Element setText(String text)
public String getText() {}
public String getTextTrim() {}
public String getTextNormalize() {}
public String getChildText(String name) {}
public String getChildTextTrim(String name) {}
public String getChildTextNormalize(String name) {}
public String getChildText(String name, Namespace ns) {}
public String getChildTextTrim(String name, Namespace ns) {}
public String getChildTextNormalize(String name, Namespace ns) {}
public List getChildren() {}
public Element setChildren(List children) {}
public List getChildren(String name) {}
public List getChildren(String name, Namespace ns) {}
public Element getChild(String name, Namespace ns) {}
public Element getChild(String name) {}
public boolean removeChild(String name) {}
public boolean removeChild(String name, Namespace ns) {}
public boolean removeChildren(String name) {}
public boolean removeChildren(String name, Namespace ns) {}
public boolean removeChildren() {}
public List getContent()
public List getContent(Filter filter)
public Element setContent(List newContent)
public Element addContent(String text) {}
public Element addContent(Text text) {}
public Element addContent(Element element) {}
public Element addContent(ProcessingInstruction pi) {}
public Element addContent(EntityRef entity) {}
public Element addContent(Comment comment) {}
public Element addContent(CDATA cdata) {}
public boolean removeContent(Element element) {}
public boolean removeContent(CDATA cdata) {}
public boolean removeContent(ProcessingInstruction pi) {}
public boolean removeContent(EntityRef entity) {}
public boolean removeContent(Comment comment) {}
public Element detach()
public List getAttributes() {}
public Attribute getAttribute(String name) {}
public Attribute getAttribute(String name, Namespace ns) {}
public String getAttributeValue(String name) {}
public String getAttributeValue(String name, Namespace ns) {}
public Element setAttribute(Attribute attribute) {}
public Element setAttributes(List attributes) {}
public boolean removeAttribute(String name) {}
public boolean removeAttribute(String name, Namespace ns) {}
public void addNamespaceDeclaration(Namespace additionalNamespace) {}
public void removeNamespaceDeclaration(Namespace additionalNamespace) {}
public List getAdditionalNamespaces() {}
public Element detach() {}
///////////////////////////////////////
// Basic Utility Methods
///////////////////////////////////////
public final String toString() {}
public final boolean equals(Object ob) {}
public final int hashCode() {}
public final Object clone() {}
}import org.jdom.*;
import org.jdom.input.SAXBuilder;
import java.util.*;
public class XCount {
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java XCount URL1 URL2...");
}
SAXBuilder builder = new SAXBuilder();
System.out.println(
"File\tElements\tAttributes\tComments\tProcessing Instructions\tCharacters");
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
Document doc = builder.build(args[i]);
System.out.print(args[i] + ":\t");
String result = count(doc);
System.out.println(result);
}
// indicates a well-formedness or other error
catch (JDOMException e) {
System.out.println(args[i]
+ " is not a well formed XML document.");
System.out.println(e.getMessage());
}
}
}
private static int numCharacters = 0;
private static int numComments = 0;
private static int numElements = 0;
private static int numAttributes = 0;
private static int numProcessingInstructions = 0;
public static String count(Document doc) {
numCharacters = 0;
numComments = 0;
numElements = 0;
numAttributes = 0;
numProcessingInstructions = 0;
List children = doc.getContent();
Iterator iterator = children.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Element) {
numElements++;
count((Element) o);
}
else if (o instanceof Comment) numComments++;
else if (o instanceof ProcessingInstruction) {
numProcessingInstructions++;
}
}
String result = numElements + "\t" + numAttributes + "\t"
+ numComments + "\t" + numProcessingInstructions + "\t"
+ numCharacters;
return result;
}
public static void count(Element element) {
List attributes = element.getAttributes();
numAttributes += attributes.size();
List children = element.getContent();
Iterator iterator = children.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Element) {
numElements++;
count((Element) o);
}
else if (o instanceof Comment) numComments++;
else if (o instanceof ProcessingInstruction) {
numProcessingInstructions++;
}
else if (o instanceof Text) {
Text t = (Text) o;
String s = t.getText();
numCharacters += s.length();
}
else if (o instanceof CDATA) {
CDATA c = (CDATA) o;
String s = c.getText();
numCharacters += s.length();
}
}
}
}
% java XCount shortlogs.xml hotcop.xml
File Elements Attributes Comments Processing Instructions
Characters
shortlogs.xml: 30 0 0 0 736
hotcop.xml: 11 8 2 1 95
Most attribute work can be done through the
Element class.
Each attribute is represented as an Attribute object
Each Attribute has:
A local name, a String
A value, a String
A Namespace object (which may be
Namespace.NO_NAMESPACE)
A parent Element object (which may be
null)
A type code such as
Attribute.CDATA_ATTRIBUTE,
Attribute.ID_ATTRIBUTE, or Attribute.UNDECLARED_ATTRIBUTE
)
JDOM enforces restrictions on attribute names and values; e.g. value may not contain < or >
Attributes are stored in a java.util.List
in the Element that contains them
This list only contains Attribute objects.
package org.jdom;
public class Attribute implements Serializable, Cloneable {
protected String name;
protected Namespace namespace;
protected String value;
protected Element parent;
protected Attribute() {}
public Attribute(String name, String value) {}
public Attribute(String name, String value, Namespace namespace) {}
public String getName() {}
public Attribute setName(String name) {}
public String getQualifiedName() {}
public String getNamespacePrefix() {}
public String getNamespaceURI() {}
public Namespace getNamespace() {}
public String getValue() {}
public Attribute setValue(String value) {}
protected Attribute setParent(Element parent) {}
public Attribute detach() {}
/////////////////////////////////////////////////////////////////
// Basic Utility Methods
/////////////////////////////////////////////////////////////////
public final String toString() {}
public final boolean equals(Object ob) {}
public final int hashCode() {}
public final Object clone() {}
/////////////////////////////////////////////////////////////////
// Convenience Methods below here
/////////////////////////////////////////////////////////////////
public int getIntValue() throws DataConversionException {}
public long getLongValue() throws DataConversionException {}
public float getFloatValue() throws DataConversionException {}
public double getDoubleValue() throws DataConversionException {}
public boolean getBooleanValue() throws DataConversionException {}
}import java.io.*;
import java.util.*;
import org.jdom.*;
import org.jdom.input.SAXBuilder;
public class BasicXLinkSpider {
private static SAXBuilder builder = new SAXBuilder();
private static Vector visited = new Vector();
private static int maxDepth = 5;
private static int currentDepth = 0;
public static void listURIs(String systemID) {
currentDepth++;
try {
if (currentDepth < maxDepth) {
Document document = builder.build(systemID);
Vector uris = new Vector();
// search the document for uris,
// store them in vector, and print them
searchForURIs(document.getRootElement(), uris);
Enumeration e = uris.elements();
while (e.hasMoreElements()) {
String uri = (String) e.nextElement();
visited.addElement(uri);
listURIs(uri);
}
}
}
catch (JDOMException ex) {
// couldn't load the document,
// probably not well-formed XML, skip it
}
catch (IOException ex) {
// couldn't load the document,
// probably broken link, skip it
}
finally {
currentDepth--;
System.out.flush();
}
}
private static Namespace xlink
= Namespace.getNamespace("http://www.w3.org/1999/xlink");
// use recursion
public static void searchForURIs(Element element, Vector uris) {
// look for XLinks in this element
String uri = element.getAttributeValue("href", xlink);
if (uri != null && !uri.equals("")
&& !visited.contains(uri) && !uris.contains(uri)) {
System.out.println(uri);
uris.addElement(uri);
}
// process child elements recursively
List children = element.getChildren();
Iterator iterator = children.iterator();
while (iterator.hasNext()) {
searchForURIs((Element) iterator.next(), uris);
}
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java BasicXLinkSpider URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
System.err.println(args[i]);
listURIs(args[i]);
} // end for
} // end main
} // end BasicXLinkSpiderimport java.io.IOException;
import org.jdom.*;
import org.jdom.input.SAXBuilder;
import org.jdom.output.XMLOutputter;
import java.util.*;
public class JDOMIDTagger {
private static int id = 1;
public static void processElement(Element element) {
if (element.getAttribute("ID") == null) {
element.setAttribute(new Attribute("ID", "_" + id));
id = id + 1;
}
// recursion
List children = element.getChildren();
Iterator iterator = children.iterator();
while (iterator.hasNext()) {
processElement((Element) iterator.next());
}
}
public static void main(String[] args) {
SAXBuilder builder = new SAXBuilder();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
Document document = builder.build(args[i]);
processElement(document.getRootElement());
// now we serialize the document...
XMLOutputter serializer = new XMLOutputter();
serializer.output(document, System.out);
System.out.flush();
}
catch (JDOMException e) {
System.err.println(e);
continue;
}
catch (IOException e) {
System.err.println(e);
continue;
}
}
} // end main
}
<?xml version="1.0"?><backslash
xmlns:backslash="http://slashdot.org/backslash.dtd">
<story>
<title>The Onion to buy the New York Times</title>
<url>http://slashdot.org/articles/00/02/19/1128240.shtml</url>
<time>2000-02-19 17:25:15</time>
<author>CmdrTaco</author>
<department>stuff-to-read</department>
<topic>media</topic>
<comments>20</comments>
<section>articles</section>
<image>topicmedia.gif</image>
</story>
<story>
<title>Al Gore's Webmaster Answers Your Questions</title>
<url>http://slashdot.org/interviews/00/02/19/0932207.shtml</url>
<time>2000-02-19 17:00:52</time>
<author>Roblimo</author>
<department>political-process-online</department>
<topic>usa</topic>
<comments>49</comments>
<section>interviews</section>
<image>topicus.gif</image>
</story>
<story>
<title>Open Source Africa</title>
<url>http://slashdot.org/articles/00/02/19/1016216.shtml</url>
<time>2000-02-19 16:05:58</time>
<author>emmett</author>
<department>songs-by-toto</department>
<topic>linux</topic>
<comments>50</comments>
<section>articles</section>
<image>topiclinux.gif</image>
</story>
<story>
<title>Microsoft Funded by NSA, Helps Spy on Win Users?</title>
<url>http://slashdot.org/articles/00/02/19/0750247.shtml</url>
<time>2000-02-19 14:07:04</time>
<author>Roblimo</author>
<department>deep-dark-conspiracy-theories</department>
<topic>microsoft</topic>
<comments>154</comments>
<section>articles</section>
<image>topicms.gif</image>
</story>
<story>
<title>X-Men Trailer Released</title>
<url>http://slashdot.org/articles/00/02/18/0829209.shtml</url>
<time>2000-02-19 13:47:06</time>
<author>emmett</author>
<department>mutant</department>
<topic>movies</topic>
<comments>70</comments>
<section>articles</section>
<image>topicmovies.gif</image>
</story>
<story>
<title>Connell Replies to "Grok" Comments</title>
<url>http://slashdot.org/articles/00/02/18/202240.shtml</url>
<time>2000-02-19 05:01:37</time>
<author>Hemos</author>
<department>replying-to-things</department>
<topic>linux</topic>
<comments>197</comments>
<section>articles</section>
<image>topiclinux.gif</image>
</story>
<story>
<title>etoy.com Returns</title>
<url>http://slashdot.org/yro/00/02/18/1739216.shtml</url>
<time>2000-02-19 02:35:06</time>
<author>nik</author>
<department>NP:-gimme-shelter</department>
<topic>internet</topic>
<comments>77</comments>
<section>yro</section>
<image>topicinternet.jpg</image>
</story>
<story>
<title>New Propaganda Series: Rebirth</title>
<url>http://slashdot.org/articles/00/02/18/205232.shtml</url>
<time>2000-02-19 01:05:26</time>
<author>Hemos</author>
<department>as-pretty-as-always</department>
<topic>graphics</topic>
<comments>120</comments>
<section>articles</section>
<image>topicgraphics3.gif</image>
</story>
<story>
<title>Giving Back</title>
<url>http://slashdot.org/features/00/02/18/1631224.shtml</url>
<time>2000-02-18 22:27:26</time>
<author>emmett</author>
<department>salvation-army</department>
<topic>news</topic>
<comments>122</comments>
<section>features</section>
<image>topicnews.gif</image>
</story>
<story>
<title>Connectix Considering Open Sourcing VGS?</title>
<url>http://slashdot.org/articles/00/02/18/1050225.shtml</url>
<time>2000-02-18 20:46:20</time>
<author>emmett</author>
<department>grain-of-salt</department>
<topic>news</topic>
<comments>93</comments>
<section>articles</section>
<image>topicnews.gif</image>
</story>
</backslash>
<?xml version="1.0" encoding="UTF-8"?>
<backslash ID="_1">
<story ID="_2">
<title ID="_3">The Onion to buy the New York Times</title>
<url ID="_4">http://slashdot.org/articles/00/02/19/1128240.shtml</url>
<time ID="_5">2000-02-19 17:25:15</time>
<author ID="_6">CmdrTaco</author>
<department ID="_7">stuff-to-read</department>
<topic ID="_8">media</topic>
<comments ID="_9">20</comments>
<section ID="_10">articles</section>
<image ID="_11">topicmedia.gif</image>
</story>
<story ID="_12">
<title ID="_13">Al Gore's Webmaster Answers Your Questions</title>
<url ID="_14">http://slashdot.org/interviews/00/02/19/0932207.shtml</url>
<time ID="_15">2000-02-19 17:00:52</time>
<author ID="_16">Roblimo</author>
<department ID="_17">political-process-online</department>
<topic ID="_18">usa</topic>
<comments ID="_19">49</comments>
<section ID="_20">interviews</section>
<image ID="_21">topicus.gif</image>
</story>
<story ID="_22">
<title ID="_23">Open Source Africa</title>
<url ID="_24">http://slashdot.org/articles/00/02/19/1016216.shtml</url>
<time ID="_25">2000-02-19 16:05:58</time>
<author ID="_26">emmett</author>
<department ID="_27">songs-by-toto</department>
<topic ID="_28">linux</topic>
<comments ID="_29">50</comments>
<section ID="_30">articles</section>
<image ID="_31">topiclinux.gif</image>
</story>
<story ID="_32">
<title ID="_33">Microsoft Funded by NSA, Helps Spy on Win Users?</title>
<url ID="_34">http://slashdot.org/articles/00/02/19/0750247.shtml</url>
<time ID="_35">2000-02-19 14:07:04</time>
<author ID="_36">Roblimo</author>
<department ID="_37">deep-dark-conspiracy-theories</department>
<topic ID="_38">microsoft</topic>
<comments ID="_39">154</comments>
<section ID="_40">articles</section>
<image ID="_41">topicms.gif</image>
</story>
<story ID="_42">
<title ID="_43">X-Men Trailer Released</title>
<url ID="_44">http://slashdot.org/articles/00/02/18/0829209.shtml</url>
<time ID="_45">2000-02-19 13:47:06</time>
<author ID="_46">emmett</author>
<department ID="_47">mutant</department>
<topic ID="_48">movies</topic>
<comments ID="_49">70</comments>
<section ID="_50">articles</section>
<image ID="_51">topicmovies.gif</image>
</story>
<story ID="_52">
<title ID="_53">Connell Replies to "Grok" Comments</title>
<url ID="_54">http://slashdot.org/articles/00/02/18/202240.shtml</url>
<time ID="_55">2000-02-19 05:01:37</time>
<author ID="_56">Hemos</author>
<department ID="_57">replying-to-things</department>
<topic ID="_58">linux</topic>
<comments ID="_59">197</comments>
<section ID="_60">articles</section>
<image ID="_61">topiclinux.gif</image>
</story>
<story ID="_62">
<title ID="_63">etoy.com Returns</title>
<url ID="_64">http://slashdot.org/yro/00/02/18/1739216.shtml</url>
<time ID="_65">2000-02-19 02:35:06</time>
<author ID="_66">nik</author>
<department ID="_67">NP:-gimme-shelter</department>
<topic ID="_68">internet</topic>
<comments ID="_69">77</comments>
<section ID="_70">yro</section>
<image ID="_71">topicinternet.jpg</image>
</story>
<story ID="_72">
<title ID="_73">New Propaganda Series: Rebirth</title>
<url ID="_74">http://slashdot.org/articles/00/02/18/205232.shtml</url>
<time ID="_75">2000-02-19 01:05:26</time>
<author ID="_76">Hemos</author>
<department ID="_77">as-pretty-as-always</department>
<topic ID="_78">graphics</topic>
<comments ID="_79">120</comments>
<section ID="_80">articles</section>
<image ID="_81">topicgraphics3.gif</image>
</story>
<story ID="_82">
<title ID="_83">Giving Back</title>
<url ID="_84">http://slashdot.org/features/00/02/18/1631224.shtml</url>
<time ID="_85">2000-02-18 22:27:26</time>
<author ID="_86">emmett</author>
<department ID="_87">salvation-army</department>
<topic ID="_88">news</topic>
<comments ID="_89">122</comments>
<section ID="_90">features</section>
<image ID="_91">topicnews.gif</image>
</story>
<story ID="_92">
<title ID="_93">Connectix Considering Open Sourcing VGS?</title>
<url ID="_94">http://slashdot.org/articles/00/02/18/1050225.shtml</url>
<time ID="_95">2000-02-18 20:46:20</time>
<author ID="_96">emmett</author>
<department ID="_97">grain-of-salt</department>
<topic ID="_98">news</topic>
<comments ID="_99">93</comments>
<section ID="_100">articles</section>
<image ID="_101">topicnews.gif</image>
</story>
</backslash>
Unparsed entities really aren't handled at all.
Most of the time, the parser resolves general entity references and you never see them.
If the parser doesn't resolve a general entity reference,
an EntityRef object will be left in the tree.
When writing, the outputter outputs entity references but not the entity's content.
This one is still being thought out.
package org.jdom;
public class EntityRef implements Serializable, Cloneable {
protected String name;
protected String publicID;
protected String systemID;
protected Element parent;
protected Document document;
protected EntityRef() {}
public EntityRef(String name) {}
public EntityRef(String name, String publicID, String systemID) {}
public EntityRef detach() {}
public Document getDocument() {}
public String getName() {}
public Element getParent() {}
public String getPublicID() {}
public String getSystemID() {}
protected EntityRef setParent(Element parent) {}
public EntityRef setName(String newPublicID) {}
public EntityRef setPublicID(String newPublicID) {}
public EntityRef setSystemID(String newSystemID) {}
public Object clone() {}
public final boolean equals(Object o) {}
public final int hashCode() {}
public String toString() {}
}
A Comment object
represents a comment like this example from the XML 1.0 spec:
<!--* N.B. some readers (notably JC) find the following
paragraph awkward and redundant. I agree it's logically redundant:
it *says* it is summarizing the logical implications of
matching the grammar, and that means by definition it's
logically redundant. I don't think it's rhetorically
redundant or unnecessary, though, so I'm keeping it. It
could however use some recasting when the editors are feeling
stronger. -MSM *-->
No children
JDOM checks the content to make sure it's legal (i.e. does not contain a double-hyphen)
package org.jdom;
public class Comment implements Serializable, Cloneable {
protected String text;
protected Comment() {}
public Comment(String text) {}
public String getText() {}
public void setText(String text) {}
public Comment detach() {}
public Document getDocument() {}
protected Comment setDocument(Document document) {}
public Element getParent() {}
protected Comment setParent(Element parent){}
public final String toString() {}
public final boolean equals(Object ob) {}
public final int hashCode() {}
public final Object clone() {}
}
import org.jdom.*;
import org.jdom.input.SAXBuilder;
import java.util.*;
public class CommentReader {
public static void main(String[] args) {
SAXBuilder builder = new SAXBuilder();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
Document doc = builder.build(args[i]);
List content = doc.getContent();
Iterator iterator = content.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Comment) {
Comment c = (Comment) o;
System.out.println(c.getText());
System.out.println();
}
else if (o instanceof Element) {
processElement((Element) o);
}
}
}
catch (JDOMException e) {
System.err.println(e);
e.getCause().printStackTrace();
}
}
} // end main
// note use of recursion
public static void processElement(Element element) {
List content = element.getContent();
Iterator iterator = content.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Comment) {
Comment c = (Comment) o;
System.out.println(c.getText());
System.out.println();
}
else if (o instanceof Element) {
processElement((Element) o);
}
} // end while
}
}
% java CommentReader hotcop.xml
The publisher is actually Polygram but I needed
an example of a general entity reference.
You can tell what album I was
listening to when I wrote this example
Or try http://www.w3.org/TR/1998/REC-xml-19980210.xml for more interesting output.
Represents a processing instruction like
<?robots index="yes" follow="no"?>
No children
Some have pseudo-attributes; some don't:
<?php
mysql_connect("database.unc.edu", "clerk", "password");
$result = mysql("music", "SELECT LastName, FirstName
FROM Employees ORDER BY LastName, FirstName");
$i = 0;
while ($i < mysql_numrows ($result)) {
$fields = mysql_fetch_row($result);
echo "<person>$fields[1] $fields[0] </person>\r\n";
$i++;
}
mysql_close();
?>
A ProcessingInstruction is represented as either
Target and Value
Target and Pseudo-attributes
JDOM checks the contents of each ProcessingInstruction
object for well-formedness
package org.jdom;
public class ProcessingInstruction implements Serializable, Cloneable {
protected String target;
protected String rawData;
protected Map mapData;
protected Element parent;
protected ProcessingInstruction() {}
public ProcessingInstruction(String target, Map data) {}
public ProcessingInstruction(String target, String data) {}
public String getTarget() {}
public String getData() {}
public ProcessingInstruction setData(String data) {}
public ProcessingInstruction setData(Map data) {}
public String getValue(String name) {}
public ProcessingInstruction setValue(String name, String value) {}
public boolean removeValue(String name) {}
public Document getDocument() {}
protected ProcessingInstruction setDocument(Document document) {}
public Element getParent() {}
protected ProcessingInstruction setParent(Element parent){}
public ProcessingInstruction detach()
public final String toString() {}
public final boolean equals(Object ob) {}
public final int hashCode() {}
public final Object clone() {}
}import java.io.*;
import java.util.*;
import org.jdom.*;
import org.jdom.input.SAXBuilder;
public class AdvancedSpider {
private static SAXBuilder builder = new SAXBuilder();
private static Vector visited = new Vector();
private static int maxDepth = 5;
private static int currentDepth = 0;
public static void listURIs(String systemID) {
currentDepth++;
try {
if (currentDepth < maxDepth) {
Document document = builder.build(systemID);
// check to see if we're allowed to spider
boolean index = true;
boolean follow = true;
ProcessingInstruction robots = findRobots(document);
if (robots != null) {
String indexValue = robots.getValue("index");
if (indexValue.equalsIgnoreCase("no")) index = false;
String followValue = robots.getValue("follow");
if (followValue.equalsIgnoreCase("no")) follow = false;
}
Vector uris = new Vector();
// search the document for uris,
// store them in vector, and print them
if (follow) searchForURIs(document.getRootElement(), uris);
Enumeration e = uris.elements();
while (e.hasMoreElements()) {
String uri = (String) e.nextElement();
visited.addElement(uri);
if (index) listURIs(uri);
}
}
}
catch (JDOMException e) {
// couldn't load the document,
// probably not well-formed XML, skip it
}
catch (IOException ex) {
// couldn't load the document,
// probably broken link, skip it
}
finally {
currentDepth--;
System.out.flush();
}
}
private static ProcessingInstruction findRobots(Document doc) {
List content = doc.getContent();
Iterator children = content.iterator();
while (children.hasNext()) {
Object o = children.next();
if (o instanceof Element) return null;
if (o instanceof ProcessingInstruction) {
ProcessingInstruction candidate = (ProcessingInstruction) o;
if (candidate.getTarget().equals("robots")) return candidate;
}
}
return null;
}
private static Namespace xlink
= Namespace.getNamespace("http://www.w3.org/1999/xlink");
// use recursion
public static void searchForURIs(Element element, Vector uris) {
// look for XLinks in this element
String uri = element.getAttributeValue("href", xlink);
if (uri != null && !uri.equals("")
&& !visited.contains(uri) && !uris.contains(uri)) {
System.out.println(uri);
uris.addElement(uri);
}
// process child elements recursively
List children = element.getChildren();
Iterator iterator = children.iterator();
while (iterator.hasNext()) {
searchForURIs((Element) iterator.next(), uris);
}
}
public static void main(String[] args) {
if (args.length == 0) {
System.out.println("Usage: java AdvancedSpider URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
System.err.println(args[i]);
listURIs(args[i]);
} // end for
} // end main
} // end AdvancedSpiderJDOM is fully namespace aware
Namespaces are represented by instances of
the Namespace class rather than by attributes or raw strings
Flyweight design pattern saves memory.
Always ask for elements and attributes by local names and namespace URIs
Elements and attributes that are not in any namespace can be asked for by local name alone
Never identify an element or attribute by qualified name
Mostly for internal parser use
Occasionally useful for tasks like finding out whether a document contains any XLinks
package org.jdom;
public final class Namespace {
public static final Namespace NO_NAMESPACE = new Namespace("", "");
public static final Namespace XML_NAMESPACE =
new Namespace("xml", "http://www.w3.org/XML/1998/namespace");
// factory methods
public static Namespace getNamespace(String prefix, String uri) {}
public static Namespace getNamespace(String uri) {}
// getter methods
public String getPrefix() {}
public String getURI() {}
// utility methods
public boolean equals(Object ob) {}
public String toString() {}
public int hashCode() {}
}
Represents a document type declaration
Has no children
package org.jdom;
public class DocType implements Serializable, Cloneable {
protected String elementName;
protected String publicID;
protected String systemID;
protected Document document;
protected String internalSubset;
protected DocType() {}
public DocType(String elementName, String publicID,
String systemID) {}
public DocType(String elementName, String systemID) {}
public DocType(String elementName) {}
public String getElementName() {}
public DocType setElementName(String elementName) {}
public String getPublicID() {}
public DocType setPublicID(String publicID) {}
public String getSystemID() {}
public DocType setSystemID(String systemID) {}
public Document getDocument() {}
public void setInternalSubset(String newData) {}
protected DocType setDocument(Document document) {}
public String getInternalSubset() {}
public String toString() {}
public final boolean equals(Object o) {}
public final int hashCode() {}
public Object clone() {}
}Verify that a document is correct XHTML
From the XHTML 1.0 spec:
It must validate against one of the three DTDs found in Appendix A.
The root element of the document must be
<html>.
The root element of the document must designate the XHTML namespace using the
xmlnsattribute [XMLNAMES]. The namespace for XHTML is defined to behttp://www.w3.org/1999/xhtml.
There must be a DOCTYPE declaration in the document prior to the root element. The public identifier included in the DOCTYPE declaration must reference one of the three DTDs found in Appendix A using the respective Formal Public Identifier. The system identifier may be changed to reflect local system conventions.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd"> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "DTD/xhtml1-frameset.dtd">
import java.io.*;
import org.jdom.*;
import org.jdom.input.SAXBuilder;
public class JDOMXHTMLValidator {
public static void main(String[] args) {
for (int i = 0; i < args.length; i++) {
validate(args[i]);
}
}
private static SAXBuilder builder = new SAXBuilder(true);
/* ^^^^ */
/* turn on validation */
// not thread safe
public static void validate(String source) {
Document document;
try {
document = builder.build(source);
}
catch (JDOMException e) {
System.out.println("Error: " + e.getMessage());
e.printStackTrace();
return;
}
// If we get this far, then the document is valid XML.
// Check to see whether the document is actually XHTML
DocType doctype = document.getDocType();
if (doctype == null) {
System.out.println("No DOCTYPE");
return;
}
String name = doctype.getElementName();
String systemID = doctype.getSystemID();
String publicID = doctype.getPublicID();
if (!name.equals("html")) {
System.out.println("Incorrect root element name " + name);
}
if (publicID == null
|| (!publicID.equals("-//W3C//DTD XHTML 1.0 Strict//EN")
&& !publicID.equals("-//W3C//DTD XHTML 1.0 Transitional//EN")
&& !publicID.equals("-//W3C//DTD XHTML 1.0 Frameset//EN"))) {
System.out.println(source + " does not seem to use an XHTML 1.0 DTD");
}
// Check the namespace on the root element
Element root = document.getRootElement();
Namespace namespace = root.getNamespace();
String prefix = namespace.getPrefix();
String uri = namespace.getURI();
if (!uri.equals("http://www.w3.org/1999/xhtml")) {
System.out.println(source
+ " does not properly declare the"
+ " http://www.w3.org/1999/xhtml namespace"
+ " on the root element");
}
if (!prefix.equals("")) {
System.out.println(source
+ " does not use the empty prefix for XHTML");
}
}
}% java JDOMXHTMLValidator http://www.w3.org/TR/xhtml1
Error: File "http://www.w3.org/TR/DTD/xhtml1-strict.dtd" not found.: Error on
line -1 of XML document: File "http://www.w3.org/TR/DTD/xhtml1-strict.dtd" not
found.
org.jdom.JDOMException: File "http://www.w3.org/TR/DTD/xhtml1-strict.dtd" not
found.: Error on line -1 of XML document: File
"http://www.w3.org/TR/DTD/xhtml1-strict.dtd" not found.
at org.jdom.input.SAXBuilder.build(SAXBuilder.java:227)
at org.jdom.input.SAXBuilder.build(SAXBuilder.java:359)
at XHTMLValidator.validate(XHTMLValidator.java:25)
at XHTMLValidator.main(XHTMLValidator.java:11)
Root cause: org.jdom.JDOMException: Error on line -1 of XML document: File
"http://www.w3.org/TR/DTD/xhtml1-strict.dtd" not found.
at org.jdom.input.SAXBuilder.build(SAXBuilder.java:228)
at org.jdom.input.SAXBuilder.build(SAXBuilder.java:359)
at XHTMLValidator.validate(XHTMLValidator.java:25)
at XHTMLValidator.main(XHTMLValidator.java:11)
Checks a variety of strings to see if they're legal for particular uses in XML as specified by XML 1.0 and Namespaces in XML.
Mostly for internal parser use
package org.jdom;
public final class Verifier {
public static final String checkElementName(String name) {}
public static final String checkAttributeName(String name) {}
public static final String checkCharacterData(String text) {}
public static final String checkNamespacePrefix(String prefix) {}
public static final String checkNamespaceURI(String uri) {}
public static final String checkProcessingInstructionTarget(String target) {}
public static final String checkCommentData(String data) {}
public static boolean isXMLCharacter(char c) {}
public static boolean isXMLNameCharacter(char c) {}
public static boolean isXMLNameStartCharacter(char c) {}
public static boolean isXMLLetterOrDigit(char c) {}
public static boolean isXMLLetter(char c) {}
public static boolean isXMLCombiningChar(char c) {}
public static boolean isXMLExtender(char c) {}
public static boolean isXMLDigit(char c) {}
public static final String checkNamespaceCollision(
Namespace namespace, Namespace other) {}
public static final String checkNamespaceCollision(
Attribute attribute, Namespace other) {}
public static final String checkNamespaceCollision(
Namespace namespace, Element element) {}
public static final String checkNamespaceCollision(
Namespace namespace, Attribute attribute) {}
public static final String checkNamespaceCollision(
Namespace namespace, List list) {}
}A checked exception so you must catch it
Wraps other exceptions that are thrown during JDOM operations
like SAXException
Root cause of exception (if any) is accessible through
the getCause() method:
public Throwable getCause()
Subclasses:
DataConversionException
IllegalArgumentException subclasses:
IllegalAddException
IllegalDataException
IllegalNameException
IllegalTargetException
package org.jdom;
public class JDOMException extends Exception {
protected Throwable cause;
public JDOMException() {}
public JDOMException(String message) {}
public JDOMException(String message, Throwable rootCause) {}
public String getMessage() {}
public void printStackTrace() {}
public void printStackTrace(PrintStream s) {}
public void printStackTrace(PrintWriter w) {}
public Throwable getCause() {}
}DOMOutputter
SAXOutputter
XMLOutputter
The process of taking an in-memory JDOM Document and converting it
to a stream of characters that can be written onto an output stream
The org.jdom.output.XMLOutputter class
package org.jdom.output;
public class XMLOutputter implements Cloneable {
public XMLOutputter() {}
public XMLOutputter(String indent) {}
public XMLOutputter(String indent, boolean newlines) {}
public XMLOutputter(String indent, boolean newlines, String encoding) {}
public XMLOutputter(XMLOutputter that) {}
public void setLineSeparator(String separator) {}
public void setNewlines(boolean newlines) {}
public void setEncoding(String encoding) {}
public void setOmitEncoding(boolean omitEncoding) {}
public void setOmitDeclaration(boolean omitDeclaration) {}
public void setExpandEmptyElements(boolean expandEmptyElements) {}
public void setIndent(String indent) {}
public void setTrimAllWhite(boolean trimAllWhite) {}
public void setTextTrim(boolean textTrim) {}
public void setTextNormalize(boolean textNormalize)
protected String escapeAttributeEntities(String s) {}
protected String escapeElementEntities(String s) {}
protected void indent(Writer out, int level) throws IOException {}
protected Writer makeWriter(OutputStream out)
throws java.io.UnsupportedEncodingException {}
protected Writer makeWriter(OutputStream out, String encoding)
throws java.io.UnsupportedEncodingException {}
protected XMLOutputter.NamespaceStack createNamespaceStack() {}
public void output(Document doc, OutputStream out) throws IOException {}
public void output(Document doc, Writer writer) throws IOException {}
public void output(Element element, Writer out) throws IOException {}
public void output(Element element, OutputStream out) {}
public void output(CDATA cdata, Writer out) throws IOException {}
public void output(CDATA cdata, OutputStream out) throws IOException {}
public void output(Comment comment, Writer out) throws IOException {}
public void output(Comment comment, OutputStream out) throws IOException {}
public void output(EntityRef entity, Writer out) throws IOException {}
public void output(EntityRef entity, OutputStream out) throws IOException {}
public void output(ProcessingInstruction processingInstruction, Writer out)
throws IOException {}
public void output(ProcessingInstruction processingInstruction, OutputStream out)
throws IOException {}
public void output(Text text, OutputStream out) throws IOException {}
public void output(Text text, Writer out) throws IOException {}
public void outputElementContent(Element element, OutputStream out)
public void outputElementContent(Element element, Writer out)
public String outputString(Document doc) throws IOException {}
public String outputString(Element element) throws IOException {}
public String outputString(CDATA cdata) {}
public String outputString(Comment comment) {}
public String outputString(DocType doctype) {}
public String outputString(EntityRef entity) {}
public String outputString(ProcessingInstruction pi) {}
public String outputString(Text text) {}
// internal printing methods
protected void printDeclaration(Document doc, Writer out, String encoding)
throws IOException {}
protected void printDocType(DocType docType, Writer out) throws IOException {}
protected void printComment(Comment comment, Writer out, int indentLevel)
throws IOException {}
protected void printProcessingInstruction(ProcessingInstruction pi,
Writer out) throws IOException {}
protected void printCDATA(CDATA cdata, Writer out, int indentLevel)
throws IOException {}
protected void printText(Text text, Writer out) throws IOException {}
protected void printElement(Element element, Writer out,
int indentLevel, NamespaceStack namespaces) throws IOException {}
protected void printString(String s, Writer out) throws IOException {}
protected void printEntity(Entity entity, Writer out) throws IOException {}
protected void printNamespace(Namespace ns, Writer out) throws IOException {}
protected void printAttributes(List attributes, Element parent,
Writer out, NamespaceStack namespaces)
throws IOException {}
public int parseArgs(String[] args, int i) {}
}Configured with three variables passed to the constructor:
indentString added at each level
of output; e.g. two spaces or a tablineSeparatorString to break lines with,
no line breaking is performed if this is null or the empty string
encodingOptions can be set with these 10 methods:
public void setLineSeparator(String separator) {}
public void setNewlines(boolean newlines) {}
public void setEncoding(String encoding) {}
public void setOmitEncoding(boolean omitEncoding) {}
public void setOmitDeclaration(boolean omitDeclaration) {}
public void setExpandEmptyElements(boolean expandEmptyElements) {}
public void setIndent(String indent) {}
public void setTextNormalize(boolean textNormalize)
public void setTrimAllWhite(boolean trimAllWhite) {}
public void setTextTrim(boolean textTrim) {}The output() method writes a Document onto a given
OutputStream:
public void output(Document doc, OutputStream out) throws IOException {}
public void output(Document doc, Writer writer) throws IOException {}There are also output() methods for other JDOM classes:
public void output(Element element, Writer out) throws IOException {}
public void output(Element element, OutputStream out) {}
public void outputElementContent(Element element, Writer out) throws IOException {}
public void outputElementContent(Element element, OutputStream out) throws IOException {}
public void output(CDATA cdata, Writer out) throws IOException {}
public void output(CDATA cdata, OutputStream out) throws IOException {}
public void output(Comment comment, Writer out) throws IOException {}
public void output(Comment comment, OutputStream out) throws IOException {}
public void output(Text text, Writer out) throws IOException {}
public void output(Text text, OutputStream out) throws IOException {}
public void output(Entity entity, Writer out) throws IOException {}
public void output(Entity entity, OutputStream out) throws IOException {}
public void output(ProcessingInstruction processingInstruction, Writer out)
throws IOException {}
public void output(ProcessingInstruction processingInstruction, OutputStream out)
throws IOException {} Use the outputString() methods to
store a document in a string:
public String outputString(Document doc) throws IOException {}
public String outputString(Element element) throws IOException {}
public String outputString(CDATA cdata) {}
public String outputString(Comment comment) {}
public String outputString(DocType doctype) {}
public String outputString(EntityRef entity) {}
public String outputString(ProcessingInstruction pi) {}
public String outputString(Text text) {}Configured by overriding protected methods:
protected void printDeclaration(Document doc, Writer out, String encoding)
throws IOException {}
protected void printDocType(DocType docType, Writer out) throws IOException {}
protected void printComment(Comment comment, Writer out, int indentLevel)
throws IOException {}
protected void printProcessingInstruction(ProcessingInstruction pi,
Writer out, int indentLevel) throws IOException {}
protected void printCDATA(CDATA cdata, Writer out, int indentLevel)
throws IOException {}
protected void printElement(Element element, Writer out,
int indentLevel, NamespaceStack namespaces) throws IOException {}
protected void printString(String s, Writer out) throws IOException {}
protected void printText(Text t, Writer out) throws IOException {}
protected void printEntityRef(EntityRef entity, Writer out) throws IOException {}
protected void printNamespace(Namespace ns, Writer out) throws IOException {}
protected void printAttributes(List attributes, Element parent,
Writer out, NamespaceStack namespaces)
throws IOException {}import org.jdom.*;
import org.jdom.output.XMLOutputter;
import org.jdom.input.SAXBuilder;
import java.io.*;
import java.util.*;
public class JDOMTagStripper extends XMLOutputter {
public JDOMTagStripper() {
super();
}
// Things we won't print at all
protected void printDeclaration(Document doc, Writer out, String encoding) {}
protected void printComment(Comment comment, Writer out, int indentLevel) {}
protected void printDocType(DocType docType, Writer out) {}
protected void printProcessingInstruction(ProcessingInstruction pi,
Writer out) {}
protected void printNamespace(Namespace ns, Writer out) {}
protected void printAttributes(List attributes, Writer out) {}
protected void printElement(Element element, Writer out,
int indentLevel, NamespaceStack namespaces) throws IOException {
List content = element.getContent();
Iterator iterator = content.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
if (o instanceof Text) {
Text t = (Text) o;
out.write(t.getText());
}
else if (o instanceof CDATA) {
CDATA t = (CDATA) o;
out.write(t.getText());
}
else if (o instanceof Element) {
printElement((Element) o, out, indentLevel, namespaces);
}
}
}
// Could easily have put main() method in a separate class
public static void main(String[] args) {
if (args.length == 0) {
System.out.println(
"Usage: java TagStripper URL1 URL2...");
}
JDOMTagStripper stripper = new JDOMTagStripper();
SAXBuilder builder = new SAXBuilder();
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
Document doc = builder.build(args[i]);
stripper.output(doc, System.out);
}
catch (JDOMException e) { // a well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage());
}
catch (IOException e) { // a well-formedness error
System.out.println(e.getMessage());
}
}
}
}
% java TagStripper hotcop.xml
Hot Cop
Jacques Morali
Henri Belolo
Victor Willis
Jacques Morali
A & M Records
6:20
1978
Village People
The process of taking an in-memory JDOM Document and converting it to
an org.w3c.dom.Document object
The org.jdom.output.DOMOutputter class:
package org.jdom.output;
public class DOMOutputter {
// Constructors
public DOMOutputter() {}
public DOMOutputter(String adapterClass) {}
// Outputter methods
public org.w3c.dom.Document output(Document document) throws JDOMException {}
protected org.w3c.dom.Element output(Element element, org.w3c.dom.Document domDoc,
NamespaceStack namespaces) throws JDOMException {}
protected org.w3c.dom.Attr output(Attribute attribute, org.w3c.dom.Document domDoc)
throws JDOMException {}
}The process of taking an in-memory JDOM Document and
walking its tree while firing off SAX events
The org.jdom.output.SAXOutputter class:
package org.jdom.output;
public class SAXOutputter {
public SAXOutputter() {}
public SAXOutputter(ContentHandler contentHandler) {}
public SAXOutputter(ContentHandler contentHandler,
ErrorHandler errorHandler, DTDHandler dtdHandler,
EntityResolver entityResolver) {}
public SAXOutputter(ContentHandler contentHandler,
ErrorHandler errorHandler, DTDHandler dtdHandler,
EntityResolver entityResolver, LexicalHandler lexicalHandler) {}
public void setContentHandler(ContentHandler contentHandler) {}
public ContentHandler getContentHandler() {}
public void setErrorHandler(ErrorHandler errorHandler) {}
public ErrorHandler getErrorHandler() {}
public void setDTDHandler(DTDHandler dtdHandler) {}
public DTDHandler getDTDHandler() {}
public void setEntityResolver(EntityResolver entityResolver) {}
public EntityResolver getEntityResolver() {}
public void setLexicalHandler(LexicalHandler lexicalHandler) {}
public LexicalHandler getLexicalHandler() {}
public void setDeclHandler(DeclHandler declHandler) {}
public DeclHandler getDeclHandler() {}
public void setReportNamespaceDeclarations(boolean declareNamespaces) {}
public void setFeature(String name, boolean value)
throws SAXNotRecognizedException, SAXNotSupportedException {}
public boolean getFeature(String name)
throws SAXNotRecognizedException, SAXNotSupportedException {}
public void setProperty(String name, Object value)
throws SAXNotRecognizedException, SAXNotSupportedException {}
public Object getProperty(String name)
throws SAXNotRecognizedException, SAXNotSupportedException {}
public void output(Document document) throws JDOMException {}
protected XMLReader createParser() throws Exception {}
}Documents larger than available memory
Byte-for-byte faithful round trips
DTDs
Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 14-15
pull parsing is the way to go in the future. The first 3 XML parsers (Lark, NXP, and expat) all were event-driven because... er well that was 1996, can't exactly remember, seemed like a good idea at the time.
--Tim Bray on the xml-dev mailing list, Wednesday, September 18, 2002
Fast
Memory efficient
Streamable
Read-only
XMLPULL
NekoPull
StAX
.Net
Open Source
http://www.xmlpull.org/
Designed for Java 2 Micro Edition (J2ME)
Two implementations:
Enhydra's kXML2: http://www.kxml.org/
Aleksander Slominski's XPP3/MXP1 http://www.extreme.indiana.edu/soap/xpp/mxp1/
![]()
XmlPullParser:XmlPullParserFactory:XmlPullParserXmlPullException:IOException
that might go wrong when parsing an
XML document, particularly well-formedness errors and tokens that don't have the expected typeXmlSerializer:import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PullChecker {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PullChecker url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (parser.next() != XmlPullParser.END_DOCUMENT) {
// reading the document...
}
// If we get here there are no exceptions
System.out.println(args[0] + " is well-formed");
}
catch (XmlPullParserException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
% java PullChecker http://www.rddl.org/ http://www.rddl.org/ is well-formed % java PullChecker http://www.cafeconleche.org/ http://www.cafeconleche.org/ is well-formed % java PullChecker http://www.cafeaulait.org http://www.cafeaulait.org is not well-formed org.xmlpull.v1.XmlPullParserException: attribute value must start with quotation or apostrophe not j (position: TEXT seen ...rogramming, Javabeans, \r\nnetwork programming">\r\n<script language=j... @16:19)
The event codes returned by next()/nextToken()/nextTag()
inform you of what the parser read.
Ten event codes:
XmlPullParser.START_DOCUMENT
XmlPullParser.END_DOCUMENT
XmlPullParser.START_TAG
XmlPullParser.END_TAG
XmlPullParser.TEXT
XmlPullParser.CDSECT
XmlPullParser.ENTITY_REF
XmlPullParser.IGNORABLE_WHITESPACE
XmlPullParser.PROCESSING_INSTRUCTION
XmlPullParser.COMMENT
XmlPullParser.DOCDECL
Depending on what the event is, different methods are available on the XmlPullParser
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class EventLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java EventLister url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
System.out.println("Start tag");
}
else if (event == XmlPullParser.END_TAG) {
System.out.println("End tag");
}
else if (event == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document");
}
else if (event == XmlPullParser.TEXT) {
System.out.println("Text");
}
else if (event == XmlPullParser.CDSECT) {
System.out.println("CDATA Section");
}
else if (event == XmlPullParser.COMMENT) {
System.out.println("Comment");
}
else if (event == XmlPullParser.DOCDECL) {
System.out.println("Document type declaration");
}
else if (event == XmlPullParser.ENTITY_REF) {
System.out.println("Entity Reference");
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
System.out.println("Ignorable white space");
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Processing Instruction");
}
else if (event == XmlPullParser.END_DOCUMENT) {
System.out.println("End Document");
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
~/speaking/oop2003/xmlandjava/examples% java EventLister hotcop.xml Ignorable white space Processing Instruction Ignorable white space Document type declaration Ignorable white space Start tag Text Start tag Text End tag Text Start tag End tag Text Start tag Text End tag Text Start tag Text End tag Text Start tag Text End tag Text Start tag Text End tag Text Comment Text Start tag Text Entity Reference Text End tag Text Start tag Text End tag Text Start tag Text End tag Text Start tag Text End tag Text End tag Ignorable white space Comment Ignorable white space End Document
The getText()
method returns the text of the current event:
public String getText()Exactly what this is depends on the type of the event:
For tags, it's null, unless round-tripping is turned on, in which case it's the complete actual tag.
For entity references, it's the entity replacement text (or null if this is not available).
For text and ignorable white space, it's the actual text.
For CDATA sections, it's the text inside the CDATA section delimiters,
that is, between <![CDATA[ and ]]>.
For start and end document, it's null.
For comments, it's the content of the comment inside the <-- and -->.
For processing instructions, it's the content of the instruction inside the <? and ?>.
For document type declarations, it's the content of the DOCTYPE declaration between <!DOCTYPE and the closing >.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class EventText {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java EventText url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
System.out.println("Start-tag: " + parser.getText()) ;
}
else if (event == XmlPullParser.END_TAG) {
System.out.println("End-tag: " + parser.getText());
}
else if (event == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document: " + parser.getText());
}
else if (event == XmlPullParser.TEXT) {
System.out.println("Text: " + parser.getText());
}
else if (event == XmlPullParser.CDSECT) {
System.out.println("CDATA Section: " + parser.getText());
}
else if (event == XmlPullParser.COMMENT) {
System.out.println("Comment: " + parser.getText());
}
else if (event == XmlPullParser.DOCDECL) {
System.out.println("Document type declaration: " + parser.getText());
}
else if (event == XmlPullParser.ENTITY_REF) {
System.out.println("Entity Reference: " + parser.getText());
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
System.out.println("Ignorable white space: " + parser.getText());
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Processing Instruction: " + parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
System.out.println("End Document: " + parser.getText());
break;
} // end else if
} // end while
} // end try
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Unlike most APIs, XMLPULL can provide the client application with the complete input text. Fully faithful round tripping is possible.
If the event is a tag, then the following methods
in XmlPullParser also work:
public String getName()
public String getNamespace()
public String getPrefix()getName() returns the local (unprefixed) name of the tag
getNamespace() returns the namespace URI, or the empty string
if the tag is not in a namespace
getPrefix() returns the prefix of the tag, or null if the tag does not have a prefix
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class NamePrinter {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NamePrinter url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
System.out.println("Start tag: ");
printEvent(parser);
}
else if (event == XmlPullParser.END_TAG) {
System.out.println("End tag");
printEvent(parser);
}
else if (event == XmlPullParser.START_DOCUMENT) {
System.out.println("Start document");
}
else if (event == XmlPullParser.TEXT) {
System.out.println("Text");
printEvent(parser);
}
else if (event == XmlPullParser.CDSECT) {
System.out.println("CDATA Section");
printEvent(parser);
}
else if (event == XmlPullParser.COMMENT) {
System.out.println("Comment");
printEvent(parser);
}
else if (event == XmlPullParser.DOCDECL) {
System.out.println("Document type declaration");
printEvent(parser);
}
else if (event == XmlPullParser.ENTITY_REF) {
System.out.println("Entity Reference");
printEvent(parser);
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
System.out.println("Ignorable white space");
printEvent(parser);
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Processing Instruction");
printEvent(parser);
}
else if (event == XmlPullParser.END_DOCUMENT) {
System.out.println("End Document");
break;
} // end else if
} // end while
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException ex) {
System.out.println("IOException while parsing " + args[0]);
ex.printStackTrace();
}
}
private static void printEvent(XmlPullParser parser) {
String localName = parser.getName();
String prefix = parser.getPrefix();
String uri = parser.getNamespace();
if (localName != null) System.out.println("\tName: " + localName);
if (prefix != null) System.out.println("\tPrefix: " + prefix);
if (uri != null) System.out.println("\tNamespace URI: " + uri);
System.out.println();
}
}
Like nextToken() except that it only reports:
START_TAG
TEXT
END_TAG
END_DOCUMENT
CDATA sections and entity references are accumulated into the above four types.
Other events are silently skipped
List all the titles in an RSS 0.91 document:
<?xml version="1.0" encoding="iso-8859-1" ?>
<!-- generator="HPE/1.0" -->
<!-- Copyright (C) 2000-2002 News Is Free. Terms Of Service http://www.newsisfree.com/termsofservice.php -->
<rss version="0.91">
<channel>
<title>Ananova: <!-- interrupting comment -->Archeology</title>
<link>http://www.ananova.com/news/index.html?keywords=Archaeology&menu=news.scienceanddiscovery.archaeology</link>
<description>Ananova: News on the move from the leading site for breaking
UK and world news, sport, entertainment, business and weather stories and information.
(By http://www.newsisfree.com/syndicate.php
- FOR PERSONAL AND NON COMMERCIAL USE ONLY!)</description>
<language>en</language>
<webMaster>mkrus@newsisfree.com</webMaster>
<lastBuildDate>11/05/02 22:16 CET</lastBuildDate>
<image>
<link>http://www.newsisfree.com/sources/info/3389/</link>
<url>http://www.newsisfree.com/HPE/Images/button.gif</url>
<title>Powered by News Is Free</title><width>88</width>
<height>31</height>
</image>
<item>
<title>Britain's earliest leprosy victim may have been found</title>
<link>http://www.newsisfree.com/click/-2,9782455,3389/</link>
</item>
<item>
<title>20th anniversary of Mary Rose recovery</title>
<link>http://www.newsisfree.com/click/-2,9773139,3389/</link>
</item>
<item>
<title>'Proof of Jesus' burial box damaged on way to Canada</title>
<link>http://www.newsisfree.com/click/-6,9663454,3389/</link>
</item>
<item>
<title>Remains of four woolly rhinos give new insight into Ice Age</title>
<link>http://www.newsisfree.com/click/-4,9533904,3389/</link>
</item>
<item>
<title>Experts solve crop lines mystery</title>
<link>http://www.newsisfree.com/click/-5,9352720,3389/</link>
</item>
</channel>
</rss>
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class RSSTitles {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java RSSTitles url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
boolean printing = false;
while (true) {
int event = parser.next();
if (event == XmlPullParser.START_TAG) {
String name = parser.getName();
if (name.equals("title")) printing = true;
}
else if (event == XmlPullParser.END_TAG) {
String name = parser.getName();
if (name.equals("title")) printing = false;
}
else if (event == XmlPullParser.TEXT) {
if (printing) System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
} // end else if
} // end while
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException ex) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Print only item titles:
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class BetterRSSLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java BetterRSSLister url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
boolean inItem = false;
boolean inTitle = false;
// Nested elements could be handled by incrementing
// and decrementing an integer instead
// of a simple boolean.
while (true) {
int event = parser.next();
if (event == XmlPullParser.START_TAG) {
String name = parser.getName();
if (name.equals("title")) inTitle = true;
if (name.equals("item")) inItem = true;
}
else if (event == XmlPullParser.END_TAG) {
String name = parser.getName();
if (name.equals("title")) inTitle = false;
if (name.equals("item")) inItem = false;
}
else if (event == XmlPullParser.TEXT) {
if (inTitle && inItem) System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
} // end else if
} // end while
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException ex) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Like next() but also skips text nodes that contain
only white space
It only reports:
START_TAG
END_TAG
Other tokens throw exceptions
Useful for skipping practically ignorable whitespace.
Can only be called after a start-tag event
Reads and returns all text up till end-tag
Returns empty-string for empty-element tag
Throws exception if there are any nested elements/tags
Enables same code to handle
<name></name>, <name/>, and
<name>PCDATA</name>.
These methods are invokable when the event type is START_TAG:
public int getAttributeCount()
public String getAttributeNamespace(int index)
public String getAttributeName(int index)
public String getAttributePrefix(int index)
public String getAttributeType(int index)
public boolean isAttributeDefault(int index)
public String getAttributeValue(int index)
public String getAttributeValue(String namespace, String name)By default, xmlns and xmlns:prefix attributes are reported
If the http://xmlpull.org/v1/doc/features.html#process-namespaces
feature is true, xmlns and xmlns:prefix attributes are not reported
unless http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes is also true.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
import java.util.*;
public class PullSpider {
// Need to keep track of where we've been
// so we don't get stuck in an infinite loop
private List spideredURIs = new Vector();
// This linked list keeps track of where we're going.
// Although the LinkedList class does not guarantee queue like
// access, I always access it in a first-in/first-out fashion.
private LinkedList queue = new LinkedList();
private URL currentURL;
private XmlPullParser parser;
public PullSpider() {
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
this.parser = factory.newPullParser();
}
catch (XmlPullParserException ex) {
throw new RuntimeException("Could not locate a pull parser");
}
}
private void processStartTag() {
String type
= parser.getAttributeValue("http://www.w3.org/1999/xlink", "type");
if (type != null) {
String href
= parser.getAttributeValue("http://www.w3.org/1999/xlink", "href");
if (href != null) {
try {
URL foundURL = new URL(currentURL, href);
if (!spideredURIs.contains(foundURL)) {
queue.addFirst(foundURL);
}
}
catch (MalformedURLException ex) {
// skip it
}
}
}
}
public void spider(URL uri) {
System.out.println("Spidering " + uri);
currentURL = uri;
try {
parser.setInput(this.currentURL.openStream(), null);
spideredURIs.add(currentURL);
for (int event = parser.next(); event != XmlPullParser.END_DOCUMENT; event = parser.next()) {
if (event == XmlPullParser.START_TAG) {
processStartTag();
}
} // end for
while (!queue.isEmpty()) {
URL nextURL = (URL) queue.removeLast();
spider(nextURL);
}
}
catch (Exception ex) {
// skip this document
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.err.println("Usage: java PullSpider url" );
return;
}
PullSpider spider = new PullSpider();
spider.spider(new URL(args[0]));
} // end main
} // end PullSpider
Spidering http://www.rddl.org Visited http://www.rddl.org Spidering http://www.rddl.org/natures Spidering http://www.rddl.org/purposes Visited http://www.rddl.org/purposes Spidering http://www.rddl.org/xrd.css Spidering http://www.rddl.org/rddl-xhtml.dtd Spidering http://www.rddl.org/rddl-qname-1.mod Spidering http://www.rddl.org/rddl-resource-1.mod Spidering http://www.rddl.org/xhtml-arch-1.mod Spidering http://www.rddl.org/xhtml-attribs-1.mod Spidering http://www.rddl.org/xhtml-base-1.mod Spidering http://www.rddl.org/xhtml-basic-form-1.mod Spidering http://www.rddl.org/xhtml-basic-table-1.mod Spidering http://www.rddl.org/xhtml-blkphras-1.mod Spidering http://www.rddl.org/xhtml-blkstruct-1.mod Spidering http://www.rddl.org/xhtml-charent-1.mod Spidering http://www.rddl.org/xhtml-datatypes-1.mod Spidering http://www.rddl.org/xhtml-framework-1.mod Spidering http://www.rddl.org/xhtml-hypertext-1.mod Spidering http://www.rddl.org/xhtml-image-1.mod Spidering http://www.rddl.org/xhtml-inlphras-1.mod Spidering http://www.rddl.org/xhtml-inlstruct-1.mod Spidering http://www.rddl.org/xhtml-lat1.ent Spidering http://www.rddl.org/xhtml-link-1.mod Spidering http://www.rddl.org/xhtml-meta-1.mod Spidering http://www.rddl.org/xhtml-notations-1.mod Spidering http://www.rddl.org/xhtml-object-1.mod Spidering http://www.rddl.org/xhtml-param-1.mod Spidering http://www.rddl.org/xhtml-qname-1.mod Spidering http://www.rddl.org/xhtml-rddl-model-1.mod Spidering http://www.rddl.org/xhtml-special.ent Spidering http://www.rddl.org/xhtml-struct-1.mod Spidering http://www.rddl.org/xhtml-symbol.ent Spidering http://www.rddl.org/xhtml-text-1.mod Spidering http://www.rddl.org/xlink-module-1.mod Spidering http://www.rddl.org/rddl.rdfs Visited http://www.rddl.org/rddl.rdfs Spidering http://www.rddl.org/rddl-integration.rxg Visited http://www.rddl.org/rddl-integration.rxg Spidering http://www.rddl.org/modules/rddl-1.rxm Spidering http://www.rddl.org/modules/xhtml-attribs-1.rxm Spidering http://www.rddl.org/modules/xhtml-base-1.rxm Visited http://www.rddl.org/modules/xhtml-base-1.rxm Spidering http://www.rddl.org/modules/xhtml-basic-form-1.rxm Spidering http://www.rddl.org/modules/xhtml-basic-table-1.rxm Spidering http://www.rddl.org/modules/xhtml-basic10-model-1.rxm Visited http://www.rddl.org/modules/xhtml-basic10-model-1.rxm Spidering http://www.rddl.org/modules/xhtml-basic10.rxm Spidering http://www.rddl.org/modules/xhtml-blkphras-1.rxm Visited http://www.rddl.org/modules/xhtml-blkphras-1.rxm Spidering http://www.rddl.org/modules/xhtml-blkstruct-1.rxm Visited http://www.rddl.org/modules/xhtml-blkstruct-1.rxm Spidering http://www.rddl.org/modules/xhtml-for-rddl.rxm Spidering http://www.rddl.org/modules/xhtml-framework-1.rxm Visited http://www.rddl.org/modules/xhtml-framework-1.rxm Spidering http://www.rddl.org/modules/xhtml-hypertext-1.rxm Spidering http://www.rddl.org/modules/xhtml-image-1.rxm Spidering http://www.rddl.org/modules/xhtml-inlphras-1.rxm Visited http://www.rddl.org/modules/xhtml-inlphras-1.rxm Spidering http://www.rddl.org/modules/xhtml-inlstruct-1.rxm Visited http://www.rddl.org/modules/xhtml-inlstruct-1.rxm Spidering http://www.rddl.org/modules/xhtml-link-1.rxm Spidering http://www.rddl.org/modules/xhtml-list-1.rxm Visited http://www.rddl.org/modules/xhtml-list-1.rxm Spidering http://www.rddl.org/modules/xhtml-meta-1.rxm Visited http://www.rddl.org/modules/xhtml-meta-1.rxm Spidering http://www.rddl.org/modules/xhtml-object-1.rxm Spidering http://www.rddl.org/modules/xhtml-param-1.rxm Spidering http://www.rddl.org/modules/xhtml-text-1.rxm Visited http://www.rddl.org/modules/xhtml-text-1.rxm Spidering http://www.rddl.org/xhtml-rddl.rng Visited http://www.rddl.org/xhtml-rddl.rng Spidering http://www.rddl.org/modules/attribs.rng Visited http://www.rddl.org/modules/attribs.rng Spidering http://www.rddl.org/modules/base.rng Visited http://www.rddl.org/modules/base.rng Spidering http://www.rddl.org/modules/basic-form.rng Visited http://www.rddl.org/modules/basic-form.rng Spidering http://www.rddl.org/modules/basic-table.rng Visited http://www.rddl.org/modules/basic-table.rng Spidering http://www.rddl.org/modules/datatypes.rng Visited http://www.rddl.org/modules/datatypes.rng Spidering http://www.rddl.org/modules/struct.rng Visited http://www.rddl.org/modules/struct.rng Spidering http://www.rddl.org/modules/text.rng Visited http://www.rddl.org/modules/text.rng Spidering http://www.rddl.org/modules/hypertext.rng Visited http://www.rddl.org/modules/hypertext.rng Spidering http://www.rddl.org/modules/list.rng Visited http://www.rddl.org/modules/list.rng Spidering http://www.rddl.org/modules/image.rng Visited http://www.rddl.org/modules/image.rng Spidering http://www.rddl.org/modules/param.rng Visited http://www.rddl.org/modules/param.rng Spidering http://www.rddl.org/modules/object.rng Visited http://www.rddl.org/modules/object.rng Spidering http://www.rddl.org/modules/meta.rng Visited http://www.rddl.org/modules/meta.rng Spidering http://www.rddl.org/modules/link.rng Visited http://www.rddl.org/modules/link.rng Spidering http://www.rddl.org/modules/xlink.rng Visited http://www.rddl.org/modules/xlink.rng Spidering http://www.rddl.org/modules/resource.rng Visited http://www.rddl.org/modules/resource.rng Spidering http://www.rddl.org/rddl.sch Visited http://www.rddl.org/rddl.sch Spidering http://www.rddl.org/rddl-schematron.xsl Visited http://www.rddl.org/rddl-schematron.xsl Spidering http://www.rddl.org/rddl.soc Spidering http://www.rddl.org/xhtml-rddl.trex Visited http://www.rddl.org/xhtml-rddl.trex Spidering http://www.rddl.org/rddl-20010122.zip Spidering http://www.rddl.org/RDDL-JOM.html Visited http://www.rddl.org/RDDL-JOM.html Spidering http://www.rddl.org/rddl.jar Spidering http://www.rddl.org/rddlapi.xsl Visited http://www.rddl.org/rddlapi.xsl Spidering http://www.rddl.org/rddlview.xsl Visited http://www.rddl.org/rddlview.xsl Spidering http://www.rddl.org/rddl2rdf.xsl Visited http://www.rddl.org/rddl2rdf.xsl Spidering http://www.rddl.org/rddl2rss.xsl Visited http://www.rddl.org/rddl2rss.xsl Spidering http://www.injektilo.org/rddl/RDDL.NET.zip Spidering http://www.rddl.org/rddl.htc Spidering http://www.rddl.org/home Visited http://www.rddl.org/home Spidering http://www.w3.org/TR/REC-xml-names Spidering http://www.ietf.org/rfc/rfc2396.txt Spidering http://www.w3.org/tr/xlink Spidering http://www.w3.org/TR/xhtml-basic Visited http://www.w3.org/TR/xhtml-basic Spidering http://www.w3.org/TR/xmlbase/ Spidering http://www.w3.org/tr/xptr Spidering http://www.w3.org/TR/xml-infoset/ Spidering http://www.w3.org/tr/xhtml1 Visited http://www.w3.org/tr/xhtml1 Spidering http://www.w3.org/TR/xlink2rdf/ Spidering http://www.w3.org/TR/xhtml-modularization/ Visited http://www.w3.org/TR/xhtml-modularization/ Spidering http://www.rddl.org/purposes#canonicalization Visited http://www.rddl.org/purposes#canonicalization Spidering http://www.rddl.org/purposes#target Visited http://www.rddl.org/purposes#target Spidering http://www.rddl.org/purposes#target Visited http://www.rddl.org/purposes#target
Unlike SAX, JDOM, and DOM, processing instructions don't really require any special treatment, classes, or methods.
What should happen:
The getName() method returns the target.
The getText() method returns the data.
What does happen:
The getName() method returns null.
The getText() method returns the complete content between the <?
and ?>.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PILister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PILister url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
System.out.println("Target: " + parser.getName());
System.out.println("Data: " + parser.getText());
System.out.println();
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
????
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class CommentPuller {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java CommentPuller url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.COMMENT) {
System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Unlike SAX, JDOM, and DOM, comments don't really require any special treatment, classes, or methods.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class CommentPuller {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java CommentPuller url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.COMMENT) {
System.out.println(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
% java CommentPuller hotcop.xml
The publisher is actually Polygram but I needed
an example of a general entity reference.
You can tell what album I was
listening to when I wrote this example As in SAX, features are boolean; properties have object values.
Features and properties are named by URIs.
All features are false by default.
Properties aren't used much.
public void setFeature(String name, boolean state)
throws XmlPullParserException;
public boolean getFeature(String name);
public void setProperty(String name, Object value)
throws XmlPullParserException;
public Object getProperty(String name);http://xmlpull.org/v1/doc/features.html#process-namespaces
http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes
http://xmlpull.org/v1/doc/features.html#process-docdecl
http://xmlpull.org/v1/doc/features.html#validation
http://xmlpull.org/v1/doc/features.html#names-interned
http://xmlpull.org/v1/doc/features.html#expand-entity-ref
http://xmlpull.org/v1/doc/features.html#xml-roundtrip
http://xmlpull.org/v1/doc/features.html#detect-encoding
http://xmlpull.org/v1/doc/features.html#serializer-attvalue-use-apostrophe
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PullValidator {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PullValidator url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
try {
parser.setFeature(XmlPullParser.FEATURE_VALIDATION, true);
}
catch (XmlPullParserException ex) {
System.err.println("This is not a validating parser");
return;
}
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
for (int event = parser.next();
event != XmlPullParser.END_DOCUMENT ;
event = parser.next()) ;
// If we get here there are no exceptions
System.out.println(args[0] + " is valid");
}
catch (XmlPullParserException ex) {
System.out.println(args[0] + " is not valid");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
<?xml version="1.0" encoding="ISO-8859-1" standalone="no"?>
The value of the version attribute is
available as a String from the
http://xmlpull.org/v1/doc/properties.html#xmldecl-version
property
The value of the standalone attribute is
available as a Boolean from the
http://xmlpull.org/v1/doc/features.html#xmldecl-standalone
property
The actual encoding is returned by the
getInputEncoding() method of
XmlPullParser.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class PullDeclaration {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PullDeclaration url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser parser = factory.newPullParser();
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
for (int event = parser.next();
event != XmlPullParser.START_TAG;
event = parser.next()) ;
String version = (String) parser.getProperty(
"http://xmlpull.org/v1/doc/properties.html#xmldecl-version");
Boolean standalone = (Boolean) parser.getProperty(
"http://xmlpull.org/v1/doc/features.html#xmldecl-standalone");
if (standalone == null) standalone = Boolean.FALSE;
String encoding = parser.getInputEncoding();
System.out.println("version=\"" + version + "\"");
System.out.println("standalone=\"" + standalone + "\"");
System.out.println("encoding=\"" + encoding + "\"");
}
catch (XmlPullParserException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
% java PullDeclaration hotcop.xml version="1.0" standalone="false" encoding="UTF-8"
Namespace support is turned off by default:
By default, xmlns and xmlns:prefix attributes are reported
as regular attributes
Turn on namespace support by setting the http://xmlpull.org/v1/doc/features.html#process-namespaces feature to true
In this case, xmlns and xmlns:prefix attributes are not reported
unless http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes is also set to true.
The require() method asserts that the current event has a certain type, local name,
and namespace URI:
public void require(int type,
String namespaceURI,
String localName)
throws XmlPullParserException,
IOException
If the event does not have the right name and URI,
an XmlPullParserException is thrown.
You can pass null for the local name or namespace URI, to match any local name/namespace URI..
This is useful for in-process validation.
package org.xmlpull.v1;
public class XmlPullParserFactory {
public static final String PROPERTY_NAME =
"org.xmlpull.v1.XmlPullParserFactory";
public void setFeature(String name, boolean state)
throws XmlPullParserException;
public boolean getFeature (String name);
public void setNamespaceAware(boolean awareness);
public boolean isNamespaceAware();
public void setValidating(boolean validating) ;
public boolean isValidating();
public XmlPullParser newPullParser()
throws XmlPullParserException;
public static XmlPullParserFactory newInstance()
throws XmlPullParserException;
public static XmlPullParserFactory newInstance(String classNames, Class context)
throws XmlPullParserException;
}
package org.xmlpull.v1;
public interface XmlPullParser {
public final static String NO_NAMESPACE = "";
public final static int START_DOCUMENT;
public final static int END_DOCUMENT;
public final static int START_TAG;
public final static int END_TAG;
public final static int TEXT;
public final static int CDSECT;
public final static int ENTITY_REF;
public final static int IGNORABLE_WHITESPACE;
public final static int PROCESSING_INSTRUCTION;
public final static int COMMENT;
public final static int DOCDECL;
public final static String [] TYPES = {
"START_DOCUMENT",
"END_DOCUMENT",
"START_TAG",
"END_TAG",
"TEXT",
"CDSECT",
"ENTITY_REF",
"IGNORABLE_WHITESPACE",
"PROCESSING_INSTRUCTION",
"COMMENT",
"DOCDECL"
};
public final static String FEATURE_PROCESS_NAMESPACES =
"http://xmlpull.org/v1/doc/features.html#process-namespaces";
public final static String FEATURE_REPORT_NAMESPACE_ATTRIBUTES =
"http://xmlpull.org/v1/doc/features.html#report-namespace-prefixes";
public final static String FEATURE_PROCESS_DOCDECL =
"http://xmlpull.org/v1/doc/features.html#process-docdecl";
public final static String FEATURE_VALIDATION =
"http://xmlpull.org/v1/doc/features.html#validation";
public void setFeature(String name, boolean state)
throws XmlPullParserException;
public boolean getFeature(String name);
public void setProperty(String name, Object value)
throws XmlPullParserException;
public Object getProperty(String name);
public void setInput(Reader in) throws XmlPullParserException;
public void setInput(InputStream inputStream, String inputEncoding)
throws XmlPullParserException;
// actual parsing methods
public int getEventType()
throws XmlPullParserException;
public int next()
throws XmlPullParserException, IOException;
public int nextToken()
throws XmlPullParserException, IOException;
// Utility methods
public void require(int type, String namespace, String name)
throws XmlPullParserException, IOException;
public String nextText() throws XmlPullParserException, IOException;
public int nextTag() throws XmlPullParserException, IOException;
public String getInputEncoding();
public void defineEntityReplacementText( String entityName,
String replacementText ) throws XmlPullParserException;
public int getNamespaceCount(int depth)
throws XmlPullParserException;
public String getNamespacePrefix(int position) throws XmlPullParserException;
public String getNamespaceUri(int position) throws XmlPullParserException;
public String getNamespace(String prefix);
public int getDepth();
public String getPositionDescription();
public int getLineNumber();
public int getColumnNumber();
// Text methods
public boolean isWhitespace() throws XmlPullParserException;
public String getText();
public char[] getTextCharacters(int[] holderForStartAndLength);
// Tag methods
public String getNamespace();
public String getName();
public String getPrefix();
public boolean isEmptyElementTag() throws XmlPullParserException;
// Attribute methods
public int getAttributeCount();
public String getAttributeNamespace(int index);
public String getAttributePrefix(int index);
public String getAttributeType(int index);
public boolean isAttributeDefault(int index);
public String getAttributeValue(int index);
public String getAttributeValue(String namespace, String name);
}
package org.xmlpull.v1;
public class XmlPullParserException extends Exception {
public XmlPullParserException(String message);
public XmlPullParserException(String message, Throwable throwble) ;
public XmlPullParserException(String message, int row, int column);
public XmlPullParserException(String message, XmlPullParser parser, Throwable chain);
public Throwable getDetail();
public void printStackTrace();
}
An event based API for creating XML documents
Instances are created by XmlPullParserFactory.newSerializer() factory method:
XmlSerializer serializer = XmlPullParserFactory.newSerializer(System.out);
Still under development
package org.xmlpull.v1;
public interface XmlSerializer {
public void setFeature(String name, boolean state)
throws IllegalArgumentException, IllegalStateException;
public boolean getFeature(String name);
public void setProperty(String name, Object value)
throws IllegalArgumentException, IllegalStateException;
public Object getProperty(String name);
public void setOutput(OutputStream out, String encoding)
throws IOException, IllegalArgumentException, IllegalStateException;
public void setOutput(Writer out)
throws IOException, IllegalArgumentException, IllegalStateException;
public void startDocument(String encoding, Boolean standalone)
throws IOException, IllegalArgumentException, IllegalStateException;
public void endDocument()
throws IOException, IllegalArgumentException, IllegalStateException;
public void setPrefix(String prefix, String namespace)
throws IOException, IllegalArgumentException, IllegalStateException;
public String getPrefix(String namespace, boolean generatePrefix)
throws IllegalArgumentException;
public int getDepth();
public String getNamespace();
public String getName();
public XmlSerializer startTag(String namespace, String name)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer attribute(String namespace, String name, String value)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer endTag(String namespace, String name)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer text(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public XmlSerializer text(char [] buf, int start, int len)
throws IOException, IllegalArgumentException, IllegalStateException;
public void cdsect(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void entityRef(String text) throws IOException,
IllegalArgumentException, IllegalStateException;
public void processingInstruction(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void comment(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void docdecl(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void ignorableWhitespace(String text)
throws IOException, IllegalArgumentException, IllegalStateException;
public void flush() throws IOException;
}
Goal: Convert a RDDL document to pure XHTML.
RDDL is
just an XHTML Basic document in which there's one extra element:
rddl:resource
which can appear anywhere a p
element can appear, and can contain anything a
div element can contain.
The customary rddl prefix is mapped to the
http://www.rddl.org/ namespace URL:
<rddl:resource id="rec-xhtml"
xlink:title="W3C REC XHTML"
xlink:role="http://www.w3.org/1999/xhtml"
xlink:arcrole="http://www.rddl.org/purposes#reference"
xlink:href="http://www.w3.org/tr/xhtml1"
>
<li><a href="http://www.w3.org/tr/xhtml1">W3C XHTML 1.0</a></li>
</rddl:resource>The program needs to throw away the
<rddl:resource> start-tag and </rddl:resource>
end-tag while leaving everything else intact.
import org.xmlpull.v1.*;
import java.net.*;
import java.io.*;
public class RDDLStripper {
public final static String RDDL_NS = "http://www.rddl.org/";
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java RDDLStripper url" );
return;
}
try {
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
factory.setNamespaceAware(true);
XmlPullParser parser = factory.newPullParser();
XmlSerializer serializer = factory.newSerializer();
serializer.setOutput(System.out, "ISO-8859-1");
InputStream in;
try {
URL u = new URL(args[0]);
in = u.openStream();
}
catch (MalformedURLException ex) {
// Maybe it's a file name
in = new FileInputStream(args[0]);
}
parser.setInput(in, null);
while (true) {
int event = parser.nextToken();
if (event == XmlPullParser.START_TAG) {
String namespaceURI = parser.getNamespace();
if (!namespaceURI.equals(RDDL_NS)) {
String prefix = parser.getPrefix();
if (prefix == null) prefix = "";
if (namespaceURI != null) {
serializer.setPrefix(prefix, namespaceURI);
}
serializer.startTag(namespaceURI, parser.getName());
// add attributes
for (int i = 0; i < parser.getAttributeCount(); i++) {
serializer.attribute(
parser.getAttributeNamespace(i),
parser.getAttributeName(i),
parser.getAttributeValue(i)
);
// How to define attribute prefixes????
}
}
}
else if (event == XmlPullParser.END_TAG) {
String namespaceURI = parser.getNamespace();
if (!namespaceURI.equals(RDDL_NS)) {
serializer.endTag(namespaceURI, parser.getName());
}
}
else if (event == XmlPullParser.TEXT) {
serializer.text(parser.getText());
}
else if (event == XmlPullParser.CDSECT) {
serializer.cdsect(parser.getText());
}
else if (event == XmlPullParser.COMMENT) {
serializer.comment(parser.getText());
}
else if (event == XmlPullParser.DOCDECL) {
serializer.docdecl(parser.getText());
}
else if (event == XmlPullParser.ENTITY_REF) {
serializer.entityRef(parser.getName());
}
else if (event == XmlPullParser.IGNORABLE_WHITESPACE) {
serializer.ignorableWhitespace(parser.getText());
}
else if (event == XmlPullParser.PROCESSING_INSTRUCTION) {
serializer.processingInstruction(parser.getText());
}
else if (event == XmlPullParser.TEXT) {
serializer.text(parser.getText());
}
else if (event == XmlPullParser.END_DOCUMENT) {
serializer.flush();
break;
}
}
}
catch (XmlPullParserException ex) {
System.out.println(ex);
}
catch (IOException e) {
System.out.println("IOException while parsing " + args[0]);
}
}
}
Makes certain kinds of programs really easy:
Filter out certain kinds of nodes
Filter out certain tags
Convert processing instructions to elements
Comment reader
Change names of elements
Add attributes to elements
Changes have to be local to be easy:
Start-tag changes based on name, namespace, and attributes
End-tag changes based on name and namespace
Event changes based on that event only
No direct filtering support
I don't know whether these programs are realistic patterns or just common tutorial examples
Too few classes; on the flip side too much is forced into the
XmlPullParser class.
Does not take advantage of polymorphism
Int type codes
Namespace support is turned off by default
DOCTYPE is sporadic and unreliable; may be getting better
Part of Andy Clark's CyberNeko Tools for the Xerces Native Interface (XNI):
NekoPull was invented for two reasons: to fix the inadequacies the author sees in other pull-parsing designs; and to add native pull-parsing capability to Xerces2.
Not yet true pull parsing; layered on top of a push parser
Apache license
Not round trippable
Uses Event Classes instead of int type constants
The base class is XMLEvent:
package org.cyberneko.pull;
public class XMLEvent {
public static final short DOCUMENT = 0;
public static final short ELEMENT = 1;
public static final short CHARACTERS = 2;
public static final short PREFIX_MAPPING = 3;
public static final short GENERAL_ENTITY = 4;
public static final short COMMENT = 5;
public static final short PROCESSING_INSTRUCTION = 6;
public static final short CDATA = 7;
public static final short TEXT_DECL = 8;
public static final short DOCTYPE_DECL = 9;
public final short type;
public Augmentations augs;
public XMLEvent next;
public XMLEvent(short type);
}
BoundedEvent have beginnings and ends:
CDATAEvent
DocumentEvent
ElementEvent
GeneralEntityEvent
PrefixMappingEvent
CharactersEvent
CommentEvent
DoctypeDeclEvent
ProcessingInstructionEvent
TextDeclEvent
XMLPullParser class represents the parser
Loaded by a subclass constructor:
XMLPullParser parser = new org.cyberneko.pull.parsers.Xerces2();
The document is read from an
org.apache.xerces.xni.parser.XMLInputSource:
XMLInputSource source = new XMLInputSource(publicID, systemID, baseSystemID);
parser.setInputSource(source);The parser's nextEvent() method returns the next XMLEvent:
public XMLEvent nextEvent() throws XNIException, IOException
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoChecker {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoChecker url" );
return;
}
try {
XMLPullParser parser = new Xerces2();;
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
// read entire document
while (parser.nextEvent() != null) ;
// If we get here there are no exceptions
System.out.println(args[0] + " is well-formed");
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0]
+ " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoLister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();;
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
switch (event.type) {
case XMLEvent.ELEMENT:
System.out.println("Element");
break;
case XMLEvent.DOCUMENT:
System.out.println("Document");
break;
case XMLEvent.CHARACTERS:
System.out.println("Characters");
break;
case XMLEvent.PREFIX_MAPPING:
System.out.println("Prefix mapping");
break;
case XMLEvent.GENERAL_ENTITY:
System.out.println("General Entity");
break;
case XMLEvent.PROCESSING_INSTRUCTION:
System.out.println("Processing instruction");
break;
case XMLEvent.CDATA:
System.out.println("CDATA section");
break;
case XMLEvent.TEXT_DECL:
System.out.println("Text declaration");
break;
case XMLEvent.DOCTYPE_DECL:
System.out.println("Document type declaration");
break;
default:
System.out.println("Unexpected event");
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an " + ex.getClass().getName());
ex.printStackTrace();
}
}
}
Bounded events have both starts and ends, with various other events in the middle:
CDATAEvent
DocumentEvent
ElementEvent
GeneralEntityEvent
PrefixMappingEvent
The public start field is true if this event is the start of the element/document/entity/etc.
The public start field is false if this event is the end of the element/document/entity/etc.
package org.cyberneko.pull.event;
public abstract class BoundedEvent extends XMLEvent {
public boolean start;
protected BoundedEvent(short type);
}
The name is an org.apache.xerces.xni.QName:
Empty elements have both a start and an end event; however,
the boolean empty field is set to true
The attributes are reported as
an org.apache.xerces.xni.Attributes object:
package org.cyberneko.pull.event;
public class ElementEvent extends BoundedEvent {
public QName element;
public XMLAttributes attributes;
public boolean empty;
public ElementEvent();
}
Used for element and attribute names
package org.apache.xerces.xni;
public class QName implements Cloneable {
public String prefix;
public String localpart;
public String rawname;
public String uri;
public QName();
public QName(String prefix, String localpart, String rawname, String uri);
public QName(QName qname);
public void setValues(QName qname);
public void setValues(String prefix, String localpart, String rawname, String uri);
public void clear();
public Object clone();
public int hashCode();
public boolean equals(Object object);
public String toString();
}
The org.apache.xerces.xni.XMLString contains the text
Not necessarily maximum number of characters (like SAX)
The boolean
ignorable field is true if this is ignorable white space.
package org.cyberneko.pull.event;
public class CharactersEvent extends XMLEvent {
public XMLString text;
public boolean ignorable;
public CharactersEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoRSSLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoRSSLister url");
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
boolean inTitle = false
while ((event = parser.nextEvent()) != null) {
switch (event.type) {
case XMLEvent.ELEMENT:
ElementEvent element = (ElementEvent) event;
String name = element.QName.localpart;
if (name.equals("title") && element.QName.uri == null) {
if (element.start) inTitle = true;
else inTitle = false;
}
break;
case XMLEvent.CHARACTERS:
if (inTitle) {
CharactersEvent text = (CharactersEvent) event;
System.out.println(text.text);
}
break;
case XMLEvent.CDATA:
if (inTitle) {
CDATAEvent text = (CDATAEvent) event;
System.out.println(text.text);
}
break;
default:
// do nothing
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
An org.apache.xerces.xni.XMLAttributes object
is set as the value of the attributes field of each
start ElementEvent object.
package org.apache.xerces.xni;
public interface XMLAttributes {
public int getLength();
public int getIndex(String qualifiedName);
public int getIndex(String uri, String localPart);
public void setName(int index, QName name);
public void getName(int index, QName name);
public String getPrefix(int index);
public String getURI(int index);
public String getLocalName(int index);
public String getQName(int index);
public void setValue(int index, String value);
public String getValue(int index);
public String getValue(String qualifiedName);
public String getValue(String uri, String localName);
public void setNonNormalizedValue(int index, String value);
public String getNonNormalizedValue(int index);
public void setType(int index, String type);
public String getType(int index);
public String getType(String qualifiedName);
public String getType(String uri, String localName);
public void setSpecified(int index, boolean specified);
public boolean isSpecified(int index);
public int addAttribute(QName name, String type, String value);
public void removeAllAttributes();
public void removeAttributeAt(int index);
public Augmentations getAugmentations (int attributeIndex);
public Augmentations getAugmentations (String uri, String localPart);
public Augmentations getAugmentations(String qualifiedName);
}
import org.apache.xerces.xni.*;
import org.apache.xerces.xni.parser.XMLInputSource;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.net.*;
import java.io.*;
import java.util.*;
public class NekoSpider {
// Need to keep track of where we've been
// so we don't get stuck in an infinite loop
private List spideredURIs = new Vector();
// This linked list keeps track of where we're going.
// Although the LinkedList class does not guarantee queue like
// access, I always access it in a first-in/first-out fashion.
private LinkedList queue = new LinkedList();
private URL currentURL;
private XMLPullParser parser;
public NekoSpider() {
this.parser = new Xerces2();
}
private void processStartTag(ElementEvent element) {
XMLAttributes attributes = element.attributes;
String type = attributes.getValue("http://www.w3.org/1999/xlink", "type");
if (type != null) {
String href = attributes.getValue("http://www.w3.org/1999/xlink", "href");
if (href != null) {
try {
URL foundURL = new URL(currentURL, href);
if (!spideredURIs.contains(foundURL)) {
queue.addFirst(foundURL);
}
}
catch (MalformedURLException ex) {
// skip it
}
}
}
}
public void spider(URL uri) {
System.out.println("Spidering " + uri);
try {
XMLInputSource source
= new XMLInputSource(null, uri.toExternalForm(), null);
parser.setInputSource(source);
spideredURIs.add(uri);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.ELEMENT) {
ElementEvent element = (ElementEvent) event;
if (element.start) processStartTag(element);
}
} // end for
while (!queue.isEmpty()) {
URL nextURL = (URL) queue.removeLast();
spider(nextURL);
}
}
catch (Exception ex) {
// skip this document
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.err.println("Usage: java NekoSpider url" );
return;
}
NekoSpider spider = new NekoSpider();
spider.spider(new URL(args[0]));
} // end main
} // end NekoSpider
The public locator field contains an
org.apache.xerces.xni.XMLLocator object for reporting positions within the document.
The public encoding field contains the actual encoding of
the document.
package org.cyberneko.pull.event;
public class DocumentEvent extends BoundedEvent {
public XMLLocator locator;
public String encoding;
public DocumentEvent();
}
The public target field contains a
String object for the processing instruction's target.
The public data field contains a
String object for the processing instruction's data.
package org.cyberneko.pull.event;
public class ProcessingInstructionEvent extends XMLEvent {
public String target;
public XMLString data;
public ProcessingInstructionEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoPILister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoPILister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.PROCESSING_INSTRUCTION) {
ProcessingInstructionEvent instruction
= (ProcessingInstructionEvent) event;
System.out.println("Target: " + instruction.target);
System.out.println("Data: " + instruction.data);
System.out.println();
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
The public
text field is an org.apache.xerces.xni.XMLString containing the content
of the comment.
package org.cyberneko.pull.event;
public class CommentEvent extends XMLEvent {
public XMLString text;
public CommentEvent();
} // class CommentEvent
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class NekoCommentReader {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java NekoCommentReader url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.COMMENT) {
CommentEvent comment = (CommentEvent) event;
System.out.println(comment.text);
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
Used for both text declarations and XML declarations.
The public boolean
xmldecl field determines which; true for an XML declaration,
false for a text declaration
package org.cyberneko.pull.event;
public class TextDeclEvent extends XMLEvent {
public boolean xmldecl;
public String version;
public String encoding;
public String standalone;
public TextDeclEvent();
}
Starts or ends a namespace prefix mapping
The default namespace has an empty string for a prefix
package org.cyberneko.pull.event;
public class PrefixMappingEvent extends BoundedEvent {
public String prefix;
public String uri;
public PrefixMappingEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class PrefixLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java PrefixLister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.PREFIX_MAPPING) {
PrefixMappingEvent mapping = (PrefixMappingEvent) event;
System.out.println("Prefix: " + mapping.prefix);
System.out.println("URI: " + mapping.uri);
System.out.println();
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
Reports the beginning or end of a non-predefined general entity
package org.cyberneko.pull.event;
public class GeneralEntityEvent extends BoundedEvent {
public String name;
public String publicId;
public String baseSystemId;
public String literalSystemId;
public String expandedSystemId;
public String encoding;
public GeneralEntityEvent();
}
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.XNIException;
import org.cyberneko.pull.*;
import org.cyberneko.pull.event.*;
import org.cyberneko.pull.parsers.Xerces2;
import java.io.IOException;
public class EntityLister {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Usage: java EntityLister url" );
return;
}
try {
XMLPullParser parser = new Xerces2();
XMLInputSource source = new XMLInputSource(null, args[0], null);
parser.setInputSource(source);
XMLEvent event;
while ((event = parser.nextEvent()) != null) {
if (event.type == XMLEvent.GENERAL_ENTITY) {
GeneralEntityEvent entity = (GeneralEntityEvent) event;
if (entity.start) {
System.out.println("Name: " + entity.name);
System.out.println("Public ID: " + entity.pubid);
System.out.println("Base System ID: " + entity.basesysid);
System.out.println("Literal System ID: " + entity.literalsysid);
System.out.println("Expanded System ID: " + entity.expandedsysid);
System.out.println("Encoding: " + entity.encoding);
System.out.println();
}
}
}
}
catch (XNIException ex) {
System.out.println(args[0] + " is not well-formed");
System.out.println(ex);
}
catch (IOException ex) {
System.out.println(args[0] + " could not be checked due to an "
+ ex.getClass().getName());
ex.printStackTrace();
}
}
}
package org.cyberneko.pull;
public interface XMLPullParser
extends XMLEventIterator, XMLComponentManager {
public void setInputSource(XMLInputSource inputSource)
throws XMLConfigurationException, IOException;
public void cleanup();
public void setErrorHandler(XMLErrorHandler errorHandler);
public XMLErrorHandler getErrorHandler();
public void setEntityResolver(XMLEntityResolver entityResolver);
public XMLEntityResolver getEntityResolver();
public void setLocale(Locale locale) throws XNIException;
public Locale getLocale();
public boolean getFeature(String featureId)
throws XMLConfigurationException;
public void setFeature(String featureId, boolean state)
throws XMLConfigurationException;
public void setProperty(String propertyId, Object value)
throws XMLConfigurationException;
public Object getProperty(String propertyId)
throws XMLConfigurationException;
public XMLEvent nextEvent() throws XNIException, IOException;
}
Streaming API for XML
javax.xml.stream.
JSR-173, proposed by BEA Systems:
Two recently proposed JSRs, JAXB and JAX-RPC, highlight the need for an XML Streaming API. Both data binding and remote procedure calling (RPC) require processing of XML as a stream of events, where the current context of the XML defines subsequent processing of the XML. A streaming API makes this type of code much more natural to write than SAX, and much more efficient than DOM.
Goals:
Develop APIs and conventions that allow a user to programmatically pull parse events from an XML input stream.
Develop APIs that allow a user to write events to an XML output stream.
Develop a set of objects and interfaces that encapsulate the information contained in an XML stream.
The specification should be easy to use, efficient, and not require a grammar. It should include support for namespaces, and associated XML constructs. The specification will make reasonable efforts to define APIs that are "pluggable".
Expert Group:
Christopher Fry BEA Systems
James Clark
Stefan Haustein
Aleksander Slominski
James Strachan
K Karun, Oracle Corporation
Gregory Messner, The Breeze Factor
Anil Vijendran, Sun Microsystems
This presentation: http://www.cafeconleche.org/slides/oop2003/xmlandjava
The XMLPULL API: http://www.xml.com/pub/a/2002/08/14/xmlpull.html
A new XML Object Model
The Transformations API for XSLT
A Java API for performing XSLT and (theoretically) other transforms.
Sufficiently parser-independent that it can work with many different XSLT processors including Xalan and SAXON.
Sufficiently model-independent that it can transform to and from XML streams, SAX event sequences, and DOM and JDOM trees.
Standard part of JAXP, bundled with Java 1.4 and later.
Most current XSLT processors written in Java support TrAX including Xalan-J 2.x, jd.xslt, LotusXSL, and Saxon. The specific implementation included with Java 1.4.0 is Xalan-J 2.2D10.
There are four main classes and interfaces in TrAX,
all in the javax.xml.transforms package:
Transformer
The class that represents the style sheet.
It transforms a Source into a
Result.
TransformerFactory
A factory class that
reads a stylesheet to produce a new
Transformer.
Source
The interface that represents the input XML document to be
transformed, whether presented as a DOM tree, an
InputStream, or a SAX event sequence.
Result
The interface that represents the XML document produced by the
transformation, whether generated as a DOM tree, an
OutputStream, or a SAX event sequence.
Load the TransformerFactory
with the static TransformerFactory.newInstance()
factory method.
Form a Source object from the XSLT stylesheet.
Pass this Source object
to the factory’s newTransformer()
factory method to build a Transformer
object.
Build a Source object
from the input XML document you wish to transform.
Build a Result object
for the target of the transformation.
Pass both the source and the result to
the Transformer
object’s transform() method.
Steps four through six can be repeated for as many different
input documents as you want. You can reuse the same
Transformer object repeatedly in
series, though you can’t use it in multiple threads in
parallel.
try {
TransformerFactory xformFactory = TransformerFactory.newInstance();
Source xsl = new StreamSource("stylesheet.xsl");
Transformer stylesheet = xformFactory.newTransformer(xsl);
Source request = new StreamSource(in);
Result response = new StreamResult(out);
stylesheet.transform(request, response);
}
catch (TransformerException e) {
System.err.println(e);
}Neither
TransformerFactory nor
Transformer is guaranteed to be
thread-safe.
Simplest solution is just to give each separate thread
its own TransformerFactory and
Transformer objects.
The Templates class represents a
parsed stylesheet. It creates new
Transformer objects on demand very quickly.
Templates is thread-safe.
TransformerFactory xformFactory = TransformerFactory.newInstance();
Source xsl = new StreamSource("stylesheet.xsl");
Templates templates = xformFactory.newTemplates(xsl);
...
while (true) {
InputStream in = getNextDocument();
OutputStream out = getNextTarget();
Source request = new StreamSource(in);
Result response = new StreamResult(out);
Transformer transformer = templates.newTransformer();
transformer.transform(request, response);
}
The
javax.xml.transform.TransformerFactory Java system property
determines which
XSLT engine TrAX uses.
Its value is the fully qualified name of the
implementation of the abstract
javax.xml.transform.TransformerFactory
class. Possible values of this property include:
Saxon 6.x: com.icl.saxon.TransformerFactoryImpl
Saxon 7.x: net.sf.saxon.TransformerFactoryImpl
Xalan:
org.apache.xalan.processor.TransformerFactoryImpl
jd.xslt:
jd.xml.xslt.trax.TransformerFactoryImpl
Oracle:
oracle.xml.jaxp.JXSAXTransformerFactory
This property can be set in all the usual ways a Java system property can be set. TrAX picks from them in this order:
System.setProperty( "javax.xml.transform.TransformerFactory",
"
classname")
The value specified at the command line using the
-Djavax.xml.transform.TransformerFactory=
option to the java interpreter
classname
The class named in the lib/jaxp.properties properties file
in the JRE directory, in a line like this one:
javax.xml.transform.TransformerFactory=classname
The class named in the
META-INF/services/javax.xml.transform.TransformerFactory file
in the JAR archives available to the runtime
Finally, if all of the above options fail,
TransformerFactory.newInstance()
returns a default implementation. In Sun’s JDK 1.4, this is
Xalan 2.2d10.
public abstract Source getAssociatedStylesheet(Source xmlDocument, String media, String title, String charset)
throws TransformerConfigurationException;
This method reads the XML document indicated by the first argument, and looks in its prolog for the stylesheet that matches the criteria given in the other three arguments.
If any of these are null, it ignores that criterion.
Loads the stylesheet matching
the criteria into a JAXP
Source object and returns it.
Use the TransformerFactory.newTransformer()
object to convert this Source into a
Transformer object.
Throws a TransformerConfigurationException
if there is no
xml-stylesheet processing instruction
pointing to an XSLT stylesheet
matching the specified criteria.
// The InputStream in contains the XML document to be transformed
try {
Source inputDocument = new StreamSource(in);
TransformerFactory xformFactory = TransformerFactory.newInstance();
Source xsl = xformFactory.getAssociatedStyleSheet(inputDocument, "print", null, null);
Transformer stylesheet = xformFactory.newTransformer(xsl);
Result outputDocument = new StreamResult(out);
stylesheet.transform(inputDocument, outputDocument);
}
catch (TransformerConfigurationException e) {
System.err.println("Problem with the xml-stylesheet processing instruction");
}
catch (TransformerException e) {
System.err.println("Problem with the stylesheet");
}Indicate what the processor supports
Defined features:
StreamSource.FEATURE:
http://javax.xml.transform.stream.StreamSource/feature
StreamResult.FEATURE:
http://javax.xml.transform.stream.StreamResult/feature
DOMSource.FEATURE:
http://javax.xml.transform.dom.DOMSource/feature
DOMResult.FEATURE:
http://javax.xml.transform.dom.DOMResult/feature
SAXSource.FEATURE:
http://javax.xml.transform.dom.SAXSource/feature
SAXResult.FEATURE:
http://javax.xml.transform.dom.SAXResult/feature
SAXTransformerFactory.FEATURE:
http://javax.xml.transform.sax.SAXTransformerFactory/feature
SAXTransformerFactory.FEATURE_XMLFILTER:
http://javax.xml.transform.sax.SAXTransformerFactory/feature/xmlfilter
The boolean values of these features for the current XSLT engine can be tested with
the getFeature() method in the TransformerFactory class:
public abstract boolean getFeature(String name);
import javax.xml.transform.*;
import javax.xml.transform.dom.*;
import javax.xml.transform.stream.*;
import javax.xml.transform.sax.*;
public class TrAXFeatureTester {
public static void main(String[] args) {
TransformerFactory xformFactory = TransformerFactory.newInstance();
String name = xformFactory.getClass().getName();
if (xformFactory.getFeature(DOMResult.FEATURE)) {
System.out.println(name + " supports DOM output.");
}
else {
System.out.println(name + " does not support DOM output.");
}
if (xformFactory.getFeature(DOMSource.FEATURE)) {
System.out.println(name + " supports DOM input.");
}
else {
System.out.println(name + " does not support DOM input.");
}
if (xformFactory.getFeature(SAXResult.FEATURE)) {
System.out.println(name + " supports SAX output.");
}
else {
System.out.println(name + " does not support SAX output.");
}
if (xformFactory.getFeature(SAXSource.FEATURE)) {
System.out.println(name + " supports SAX input.");
}
else {
System.out.println(name + " does not support SAX input.");
}
if (xformFactory.getFeature(StreamResult.FEATURE)) {
System.out.println(name + " supports stream output.");
}
else {
System.out.println(name + " does not support stream output.");
}
if (xformFactory.getFeature(StreamSource.FEATURE)) {
System.out.println(name + " supports stream input.");
}
else {
System.out.println(name + " does not support stream input.");
}
if (xformFactory.getFeature(SAXTransformerFactory.FEATURE)) {
System.out.println(name + " returns SAXTransformerFactory "
+ "objects from TransformerFactory.newInstance().");
}
else {
System.out.println(name
+ " does not use SAXTransformerFactory.");
}
if (xformFactory.getFeature(SAXTransformerFactory.FEATURE_XMLFILTER)) {
System.out.println(
name + " supports the newXMLFilter() methods.");
}
else {
System.out.println(
name + " does not support the newXMLFilter() methods.");
}
}
}Here’s the results of running this program against Saxon 6.5.1:
C:\XMLJAVA>java -Djavax.xml.transform.TransformerFactory=com.icl.saxon.TransformerFactoryImpl TrAXFeatureTester com.icl.saxon.TransformerFactoryImpl supports DOM output. com.icl.saxon.TransformerFactoryImpl supports DOM input. com.icl.saxon.TransformerFactoryImpl supports SAX output. com.icl.saxon.TransformerFactoryImpl supports SAX input. com.icl.saxon.TransformerFactoryImpl supports stream output. com.icl.saxon.TransformerFactoryImpl supports stream input. com.icl.saxon.TransformerFactoryImpl returns SAXTransformerFactory objects from TransformerFactory.newInstance(). com.icl.saxon.TransformerFactoryImpl supports the newXMLFilter() methods.
Some XSLT processors provide non-standard, custom attributes that control their behavior. Like features, these are also named via URIs. For example, Xalan-J 2.3 defines these three attributes:
http://apache.org/xalan/features/optimizeBy default, Xalan rewrites stylesheets in an attempt to optimize them (similar to the behavior of an optimizing compiler for Java or other languages). This can confuse tools that need direct access to the stylesheet such as XSLT profilers and debuggers. If you’re using such a tool with Xalan, you should set this attribute to false.
http://apache.org/xalan/features/incrementalSetting this feature to true allows Xalan to begin producing output before it has finished processing the entire input document. This may cause problems if an error is detected late in the process, but it shouldn’t be a big problem in fully debugged and tested environments.
http://apache.org/xalan/features/source_locationSetting this to true tells Xalan to provide a
JAXP SourceLocator
a program can use to determine the location (line numbers, column
numbers,
system IDs, and public IDs) of individual nodes during the
transform.
However, it engenders a substantial performance hit
so it’s turned off by default.
Other processors define their own attributes. Although TrAX is designed as a generic API, it does let you access such custom features with these two methods:
public abstract
void setAttribute(String name Object
value) throws
IllegalArgumentException;public abstract Object
getAttribute(String name)
throws IllegalArgumentException;For example, this code tries to turn on incremental output:
TransformerFactory xformFactory
= TransformerFactory.newInstance();
try {
xformFactory.setAttribute(
"http://apache.org/xalan/features/incremental", Boolean.TRUE);
}
catch (IllegalArgumentException e) {
// This XSLT processor does not support the
// http://apache.org/xalan/features/incremental attribute,
// but we can still use the processor anyway
}package javax.xml.transform;
public interface URIResolver {
public Source resolve(String href, String base)
throws TransformerException;
}
The resolve() method should return
a Source object if it successfully resolves the URL.
Otherwise it should return null to indicate that the default
URL resolution mechanism should be used.
A URIResolver class
import javax.xml.transform.*;
import javax.xml.transform.stream.StreamSource;
import java.util.zip.GZIPInputStream;
import java.net.URL;
import java.io.InputStream;
public class GZipURIResolver implements URIResolver {
public Source resolve(String href, String base) {
try {
href = href + ".gz";
URL context = new URL(base);
URL u = new URL(context, href);
InputStream in = u.openStream();
GZIPInputStream gin = new GZIPInputStream(in);
return new StreamSource(gin, u.toString());
}
catch (Exception e) {
// If anything goes wrong, just return null and let
// the default resolver try.
}
return null;
}
}
The following two methods in
TransformerFactory
set and get the URIResolver
that Transformer objects created by
this factory will use to resolve URIs:
public
abstract void setURIResolver(URIResolver resolver);public abstract URIResolver getURIResolver();For example,
URIResolver resolver = new GZipURIResolver(); factory.setURIResolver(resolver);
XSLT transformations can fail for any of several reasons, including:
The stylesheet is syntactically incorrect.
The source document is malformed.
Some external resource the processor needs to load,
such as a document referenced by the
document() function
or the .class
file that implements an extension function,
is not available.
By default, any such problems are reported by printing them on
System.err. However, you can provide
more sophisticated error handling, reporting, and logging by
implementing the ErrorListener
interface.
package javax.xml.transform;
public interface ErrorListener {
public void warning(TransformerException exception)
throws TransformerException;
public void error(TransformerException exception)
throws TransformerException;
public void fatalError(TransformerException exception)
throws TransformerException;
}
import javax.xml.transform.*;
import java.util.logging.*;
public class LoggingErrorListener implements ErrorListener {
private Logger logger;
public LoggingErrorListener(Logger logger) {
this.logger = logger;
}
public void warning(TransformerException exception) {
logger.log(Level.WARNING, exception.getMessage(), exception);
// Don't throw an exception and stop the processor
// just for a warning; but do log the problem
}
public void error(TransformerException exception)
throws TransformerException {
logger.log(Level.SEVERE, exception.getMessage(), exception);
// XSLT is not as draconian as XML. There are numerous errors
// which the processor may but does not have to recover from;
// e.g. multiple templates that match a node with the same
// priority. I do not want to allow that so I throw this
// exception here.
throw exception;
}
public void fatalError(TransformerException exception)
throws TransformerException {
logger.log(Level.SEVERE, exception.getMessage(), exception);
// This is an error which the processor cannot recover from;
// e.g. a malformed stylesheet or input document
// so I must throw this exception here.
throw exception;
}
}
The following two methods appear in both
TransformerFactory and
Transformer. They
enable you to set and get the ErrorListener
that the object will report problems to:
public abstract void setErrorListener(ErrorListener listener)
throws IllegalArgumentException;public abstract ErrorListener getErrorListener();
An ErrorListener registered
with a Transformer will report errors
with the transformation.
An ErrorListener registered
with a TransformerFactory will report errors
with the factory’s attempts to create new
Transformer objects. For example,
this code fragment installs separate
LoggingErrorListeners on the
TransformerFactory and the
Transformer object it creates that
will record messages in two different logs.
TransformerFactory factory = TransformerFactory.newInstance();
Logger factoryLogger
= Logger.getLogger("com.macfaq.trax.factory");
ErrorListener factoryListener
= new LoggingErrorListener(factoryLogger);
factory.setErrorListener(factoryListener);
Source source = new StreamSource("FibonacciXMLRPC.xsl");
Transformer stylesheet = factory.newTransformer(source);
Logger transformerLogger
= Logger.getLogger("com.macfaq.trax.transformer");
ErrorListener transformerListener
= new LoggingErrorListener(transformerLogger);
stylesheet.setErrorListener(transformerListener);
Top-level xsl:param and
xsl:variable elements
both define variables by
binding a name to a value. This variable can be dereferenced
elsewhere in the stylesheet using the form
$.
Once set, the value of an XSLT variable is fixed and cannot
be changed. However if the variable is defined with a
top-level namexsl:param element instead of an
xsl:variable element, then the default value
can be changed before the transformation begins.
For example, the DocBook XSL stylesheets have a number of parameters that set various formatting options. I use these settings:
<xsl:param name="fop.extensions">1</xsl:param> <xsl:param name="page.width.portrait">7.375in</xsl:param> <xsl:param name="page.height.portrait">9.25in</xsl:param> <xsl:param name="page.margin.top">0.5in</xsl:param> <xsl:param name="page.margin.bottom">0.5in</xsl:param> <xsl:param name="region.before.extent">0.5in</xsl:param> <xsl:param name="body.margin.top">0.5in</xsl:param> <xsl:param name="page.margin.outer">1.0in</xsl:param> <xsl:param name="page.margin.inner">1.0in</xsl:param> <xsl:param name="body.font.family">Times</xsl:param> <xsl:param name="variablelist.as.blocks" select="1"/> <xsl:param name="generate.section.toc.level" select="1"/> <xsl:param name="generate.component.toc" select="0"/>
The initial (and thus final) value of any parameter can be
changed inside your Java code using these three methods of
the
Transformer class:
public abstract void setParameter(String name, Object value);public abstract Object getParameter(String name);public abstract void clearParameters();
The setParameter() method provides a
value for a parameter that overrides any value used in the
stylesheet itself. The processor is responsible for
converting the Java object type passed to a reasonable XSLT
equivalent. This should work well enough for
String,
Integer,
Double, and
Boolean as well as DOM types like
Node and
NodeList. However, I
wouldn’t rely on it for anything more complex like a
File or a
Frame.
The getParameter() method returns
the value of a parameter previously set by Java. It will not
return any value from the stylesheet itself, even if it has
not been overridden by the Java code. Finally, the
clearParameters() method eliminates
all Java mappings of parameters so that those variables are
returned to whatever value is specified in the stylesheet.
For example, in Java the above list of parameters for the
DocBook stylesheets could be set with a JAXP Transformer
object like this:
transformer.setParameter("fop.extensions", "1");
transformer.setParameter("page.width.portrait", "7.375in");
transformer.setParameter("page.height.portrait", "9.25in");
transformer.setParameter("page.margin.top", "0.5in");
transformer.setParameter("region.before.extent", "0.5in");
transformer.setParameter("body.margin.top", "0.5in");
transformer.setParameter("page.margin.bottom", "0.5in");
transformer.setParameter("page.margin.outer", "1.0in");
transformer.setParameter("page.margin.inner", "1.0in");
transformer.setParameter("body.font.family", "Times");
transformer.setParameter("variablelist.as.blocks", "1");
transformer.setParameter("generate.section.toc.level", "1");
transformer.setParameter("generate.component.toc", "0");
Here I used strings for all the values.
However, in a few cases I could have used a
Number of some kind instead.
The
xsl:output instruction controls the details
of serialization. For example, it can specify
XML, HTML, or plain text output.
It can specify the encoding of the output, what the document type declaration
points to, whether the elements should be indented, what the value of the standalone declaration
is, where CDATA sections should be used, and more.
For example, adding this xsl:output element
to a stylesheet would produce plain text output instead of
XML:
<xsl:output method="text" encoding="US-ASCII" media-type="text/plain" />
This xsl:output element asks for
pretty-printed
XML:
<xsl:output method="xml" encoding="UTF-16" indent="yes" media-type="text/xml" standalone="yes" />
In all, there are ten attributes of the
xsl:output element that control
serialization of the result tree:
method="xml | html | text"
The output method. xml is the default.
html uses classic
HTML syntax such as <hr> instead of
<hr />. text outputs plain
text but no markup.
version="1.0"
The version number used in the XML declaration.
Currently, this should always have the value
1.0.
encoding="UTF-8 | UTF-16 | ISO-8859-1 | …"The encoding used for the output and in the encoding declaration of the output document.
omit-xml-declaration="yes | no"
yes if the XML declaration should be omitted,
no
otherwise. (i.e. no if the XML declaration should be included,
yes if it shouldn’t be.) The default is no.
standalone="yes | no"
The value of the standalone attribute for the XML declaration; either
yes or no
doctype-public="public ID"
The public identifier used in the
DOCTYPE declaration
doctype-system="URI"
The URL used as a system identifier in the
DOCTYPE declaration
cdata-section-elements="element_name_1 element_name_2 …"A white space separated list of the qualified names of the elements’ whose content should be output as a CDATA section
indent="yes | no"
yes if extra white space should be added
to pretty-print the result, no
otherwise. The default is no.
media-type="text/xml | text/html | text/plain | application/xml… "The MIME media type of the output such as text/html, application/xml, or application/xml+svg
You can also control these output properties from inside your
Java programs using these four methods in the
Transformer class.:
public abstract void setOutputProperties(Properties
outputFormat)
throws IllegalArgumentException;
public abstract Properties getOutputProperties();public abstract void setOutputProperty(String name, String value)
throws IllegalArgumentException;public abstract String getOutputProperty(String name);
The keys and values for these properties are simply the string names established by the XSLT 1.0 specification.
The
javax.xml.transform.OutputKeys class
provides
named constants for all the property names:
package javax.xml.transform;
public class OutputKeys {
private OutputKeys() {}
public static final String METHOD = "method";
public static final String VERSION = "version";
public static final String ENCODING = "encoding";
public static final String OMIT_XML_DECLARATION
= "omit-xml-declaration";
public static final String STANDALONE = "standalone";
public static final String DOCTYPE_PUBLIC = "doctype-public";
public static final String DOCTYPE_SYSTEM = "doctype-system";
public static final String CDATA_SECTION_ELEMENTS
= "cdata-section-elements";
public static final String INDENT = "indent";
public static final String MEDIA_TYPE = "media-type";
}For example:
transformer.setOutputProperty(OutputKeys.METHOD, "xml"); transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-16"); transformer.setOutputProperty(OutputKeys.INDENT, "yes"); transformer.setOutputProperty(OutputKeys.MEDIA_TYPE, "text/xml"); transformer.setOutputProperty(OutputKeys.STANDALONE, "yes");
In the event of a conflict between what the Java code
requests with output properties
requests and what the stylesheet requests with an
xsl:output element, the ones specified
in the Java code take precedence.
The Source
and Result interfaces abstract
out the API dependent details of exactly how an XML document
is represented. You can construct sources from DOM
nodes, SAX event sequences, and raw streams.
You can target the result of a transform at
a DOM Node,
a SAX ContentHandler,
or a stream-based target such as an
OutputStream,
Writer,
File, or String.
Other models may also provide their own implementations of
these interfaces. For instance, JDOM has an
org.jdom.transform package that includes a
JDOMSource and
JDOMResult class.
In fact, these different models have very little in common, other than that
they all hold an XML document.
Consequently, the Source
and Result interfaces don’t
themselves provide a lot of the functionality you need, just
methods to get the system and public ID of the document.
Everything else is deferred to the implementations.
package javax.xml.transform.dom;
public class DOMSource implements Source {
public static final String FEATURE =
"http://javax.xml.transform.dom.DOMSource/feature";
public DOMSource() {}
public DOMSource(Node node);
public DOMSource(Node node, String systemID);
public void setNode(Node node);
public Node getNode();
public void setSystemId(String baseID);
public String getSystemId();
}
In theory, you should be able to convert any DOM Node
object into a DOMSource and transform
it. In practice, only transforming
document nodes is truly reliable. (It’s not even clear that
the XSLT processing model applies to anything that isn’t a
complete document.)
In my tests, Xalan-J could transform all the nodes I threw
at it. However, Saxon could only transform
Document objects
and Element
objects that were part of a document tree.
package javax.xml.transform.dom;
public class DOMResult implements Result {
public static final String FEATURE =
"http://javax.xml.transform.dom.DOMResult/feature";
public DOMResult();
public DOMResult(Node node);
public DOMResult(Node node, String systemID);
public void setNode(Node node);
public Node getNode();
public void setSystemId(String systemId);
public String getSystemId();
}
If you specify a Node for the
result, either via the constructor or
by calling setNode(), then the
output of the transform will be appended to that
node’s children. Otherwise, the transform output will
be appended to a new
Document or
DocumentFragment
Node. The getNode()
method returns this Node.
package javax.xml.transform.sax;
public class SAXSource implements Source {
public static final String FEATURE =
"http://javax.xml.transform.sax.SAXSource/feature";
public SAXSource();
public SAXSource(XMLReader reader, InputSource inputSource);
public SAXSource(InputSource inputSource);
public void setXMLReader(XMLReader reader);
public XMLReader getXMLReader();
public void setInputSource(InputSource inputSource);
public InputSource getInputSource();
public void setSystemId(String systemID);
public String getSystemId();
public static InputSource sourceToInputSource(Source source);
}
package javax.xml.transform.sax; public class SAXResult implements Result public static final String FEATURE = "http://javax.xml.transform.sax.SAXResult/feature"; public SAXResult(); public SAXResult(ContentHandler handler); public void setHandler(ContentHandler handler); public ContentHandler getHandler(); public void setLexicalHandler(LexicalHandler handler); public LexicalHandler getLexicalHandler(); public void setSystemId(String systemId); public String getSystemId(); }
The StreamSource and
StreamResult classes are used as
sources and targets for transforms from sequences of bytes and characters.
This includes
streams, readers, writers, strings, and files.
What unifies these is that none of them know they contain
an XML document.
Indeed, on input they may not always contain an XML document.
If so, an exception will be thrown as soon as you attempt
to build a Transformer or
a Templates object from
the
StreamSource.
package javax.xml.transform.stream;
public class StreamSource implements Source {
public static final String FEATURE =
"http://javax.xml.transform.stream.StreamSource/feature";
public StreamSource();
public StreamSource(InputStream inputStream);
public StreamSource(InputStream inputStream, String systemID);
public StreamSource(Reader reader);
public StreamSource(Reader reader, String systemID);
public StreamSource(String systemID);
public StreamSource(File f);
public void setInputStream(InputStream inputStream);
public InputStream getInputStream();
public void setReader(Reader reader);
public Reader getReader();
public void setPublicId(String publicID);
public String getPublicId();
public void setSystemId(String systemID);
public String getSystemId();
public void setSystemId(File f);
}
You should not specify both
an InputStream and a
Reader. If you do, which one the processor reads from
is implementation dependent.
If neither an InputStream nor a
Reader is available, then the
processor will attempt to open a connection to the URI
specified by the system ID.
You should set the system ID even if you do specify an
InputStream or a
Reader because this will be needed to
resolve relative URLs that appear inside the stylesheet and
input document.
package javax.xml.transform.stream;
public class StreamResult implements Result
public static final String FEATURE =
"http://javax.xml.transform.stream.StreamResult/feature";
public StreamResult() {}
public StreamResult(OutputStream outputStream);
public StreamResult(Writer writer);
public StreamResult(String systemID);
public StreamResult(File f);
public void setOutputStream(OutputStream outputStream);
public OutputStream getOutputStream();
public void setWriter(Writer writer);
public Writer getWriter();
public void setSystemId(String systemID);
public void setSystemId(File f);
public String getSystemId();
}
You should specify the system ID URL and one of the
other identifiers (File,
OutputStream, Writer,
or String.)
If you specify more than one possible target,
which one the processor
chooses
is implementation dependent.
Elliotte Rusty Harold
Addison Wesley, 2002
Chapter 17
This presentation: http://www.cafeconleche.org/slides/oop2003/xmlandjava
 Processing XML with Java
Processing XML with Java
Elliotte Rusty Harold
Addison-Wesley, 2002
ISBN 0-201-77186-1
XML in a Nutshell, 2nd Edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2002
ISBN 0-596-00292-0