Elliotte Rusty Harold is an Adjunct Professor at Polytechnic University
Elliotte Rusty Harold writes the Manging XML Data column for IBM developerWorks
Elliotte Rusty Harold maintains the popular Cafe au Lait and Cafe con Leche web sites
Elliotte Rusty Harold speaks frequently on XML, Java, and Software Testing
XML succeeded, and in ways that weren't expected - at least not by many. Originally it was conceived as a document-oriented technology for robust quality publishing of documents over networks. the original workplan had three pillars - XML syntax, XML link, and XML stylesheets. Schemas were not high on the agenda and XML was not seen as an infrastructure for middleware or glueware. It was expected that at some stage it would be necessary to manage data but there was little activity in this area in 1997. When developing Chemical Markup Language (which must be one of the first published XML applications), I found the lack of datatypes very frustrating!
Well, XML is now a basic infrastructure of much modern information. I doubt that anyone now designs a protocol, or operating system without including XML. Although this list sometimes complains that XML isn't as clean as we would like, it works, and it works pretty well.
--Peter Murray-Rust on the xml-dev mailing list, Thursday, February 7, 2002
Extensible Markup Language
A syntax for documents
A Meta-Markup Language
A Structural and Semantic language, not a formatting language
Not like HTML, troff, LaTeX
Make up the tags you need as you need them
The tags you create can be documented in a schema in any of several schema languages
A meta syntax for domain-specific markup languages like MusicML, MathML, and CML
Describe semantics, not presentation
Element and attribute names reflect the kind of the element
Formatting can be added with a style sheet
<dt>Hot Cop
<dd> by Jacques Morali, Henri Belolo, and Victor Willis
<ul>
<li>Jacques Morali
<li>PolyGram Records
<li>6:20
<li>1978
<li>Village People
</ul>
<?xml version="1.0"?>
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
Documents are composed of elements
An element is delimited by a start-tag and a matching end-tag:
<COMPOSER>Jacques Morali</COMPOSER>
Start-tag <COMPOSER>
Contents "Jacques Morali"
End-tag </COMPOSER>
Elements can contain other elements:
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
Combine with parent elements
The Dumpty-Humpty principle: It is easier to put things together than take them apart
Elements can contain other elements:
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>
<GIVEN>Jacques</GIVEN>
<FAMILY>Morali</FAMILY>
</COMPOSER>
<COMPOSER>
<GIVEN>Henri</GIVEN>
<FAMILY>Belolo</FAMILY>
</COMPOSER>
<COMPOSER>
<GIVEN>Victor</GIVEN>
<FAMILY>Willis</FAMILY>
</COMPOSER>
<PRODUCER>
<GIVEN>Jacques</GIVEN>
<FAMILY>Morali</FAMILY>
</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
Is the length unitary?
A simple and straight-forward language for applying styles like bold and Helvetica to particular XML elements.
Rather than being stored as part of the document itself, all the style information is placed in a separate document called a style sheet.
Partially supported by Firefox, Mozilla, Netscape 6 and later, IE 5.0 and later, and Opera 4.0 and later
SONG {display: block}
TITLE {display: block;
font-family: Helvetica, sans-serif;
font-size: 20pt; font-weight: bold;}
COMPOSER {display: block;
font-family: Times, "Times New Roman", serif;
font-size: 14pt;
font-style: italic;}
ARTIST {display: block;
font-family: Times, "Times New Roman", serif;
font-size: 14pt; font-weight: bold;
font-style: italic;}
PUBLISHER {display: block;
font-family: Times, "Times New Roman", serif;
font-size: 14pt;}
LENGTH {display: block;
font-family: Times, "Times New Roman", serif;
font-size: 14pt;}
YEAR {display: block;
font-family: Times, "Times New Roman", serif;
font-size: 14pt;}<?xml version="1.0"?>
<?xml-stylesheet type="text/css" href="song1.css"?>
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="SONG">
<html>
<body>
<h1>
<xsl:value-of select="TITLE"/>
by the
<xsl:value-of select="ARTIST"/>
</h1>
<ul>
<xsl:apply-templates select="COMPOSER"/>
<li>Publisher: <xsl:value-of select="PUBLISHER"/></li>
<li>Year: <xsl:value-of select="YEAR"/></li>
<li>Producer: <xsl:value-of select="PRODUCER"/></li>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="COMPOSER">
<li>Composer: <xsl:value-of select="."/></li>
</xsl:template>
</xsl:stylesheet>Supported by Firefox, Mozilla, Safari 2, Opera 9, IE
Can use third party tools like Xalan, Saxon, and NXSLT
Let's use xsltproc to apply this stylesheet to compositions.xml:
C:\> xsltproc song.xsl hotcop.xml > hotcop.html
<html>
<body>
<h1>Hot Cop
by the
Village People
</h1>
<ul>
<li>Composer: Jacques Morali</li>
<li>Composer: Henri Belolo</li>
<li>Composer: Victor Willis</li>
<li>Publisher: PolyGram Records</li>
<li>Year: 1978</li>
<li>Producer: Jacques Morali</li>
</ul>
</body>
</html>CSS has broader support.
CSS is simpler.
XSL is much more powerful.
XSL can be used without browser support by transforming to HTML on the server side.
XSL+CSS: best of both worlds
Plain ASCII or UTF-8 text
.xml is customary file extension
application/xml is MIME type
Any plain text editor will work
All XML processors must support it
Supports all languages and scripts XML supports
Broad external tool support; even with non-XML tools
Robust against corruption
Size has nothing to do with it
The minimum syntactic constraints all XML documents must adhere to
If it's not well-formed, it's not XML
Parsers check this automatically
Draconian error handling
Open and close all tags
Empty-element tags end with />
There is a unique root element
Elements may not overlap
Attribute values are quoted
< and & are only used to start tags and entities
Only the five predefined entity references are used
Plus more...
Good:
<p>The quick brown fox jumped over the lazy dog</p>
<li>A very <B>important</B> point</li>
Copyright 1999 Elliotte Rusty Harold<br></br>
Bad:
The quick brown fox jumped over the lazy dog<p>
<li>A very <B>important point
Copyright 1999 Elliotte Rusty Harold<br>
<BR/>, <HR/>, and
<IMG/> instead of
<BR>, <HR>, and
<IMG>
Web browsers deal inconsistently with these
Can use <BR></BR>
<HR></HR>
<IMG></IMG> instead
<BR CLASS="EMPTY"/>
seems to work best.
No semantic meaning
One element completely contains all other elements of the document
This is HTML in HTML files
The XML declaration and xml-stylesheet processing instruction are
not elements
A few processes produce well-balnced trees instead of well-formed documents
If an element contains a start tag for an element, it must also contain the corresponding end tag
Empty elements may appear anywhere
Every non-root element has a parent element
Good:
<A HREF="http://www.cafeconleche.org/">
<DIV ALIGN="CENTER">
<A HREF="http://www.cafeconleche.org/">
<EMBED SRC="minnesotaswale.aif" hidden="hidden">
Bad:
<A HREF=http://www.cafeconleche.org/>
<DIV ALIGN=CENTER>
<EMBED SRC=minnesotaswale.aif hidden=hidden>
<EMBED SRC="minnesotaswale.aif" hidden>
Good:
<H1>O'Reilly & Associates</H1>
Bad:
<H1>O'Reilly & Associates</H1>
Good:
<CODE>for (int i = 0; i <= args.length; i++ ) { </CODE>
Bad:
<CODE>for (int i = 0; i <= args.length; i++ ) { </CODE>
Good:
&
<
>
"
'
Bad:
©
®
&tm;
α
é
etc.
Entity references must end with a semicolon.
< is good
< is bad
Decimal:
| ¡ | ¡ |
| ¢ | ¢ |
| £ | £ |
| ¤ | ¤ |
| ¥ | ¥ |
| ¦ | ¦ |
Hexadecimal
| ¡ | ¡ |
| ¢ | ¢ |
| £ | £ |
| ¤ | ¤ |
| ¥ | ¥ |
| ¦ | ¦ |
Avoid MinML
Avoid GMarkup
Avoid fast "parsers" that skimp on necessary checks (Woodstox)
It's a security issue
To be valid an XML document must be
Well-formed
Must have a DOCTYPE declaration
specifying a
Document Type Definition (DTD)
Must comply with the constraints specified in the DTD
<!ELEMENT SONG (TITLE, COMPOSER+, PRODUCER*, PUBLISHER*,
LENGTH?, YEAR?, ARTIST+)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT ARTIST (#PCDATA)><?xml version="1.0"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>To check validity you pass the document through a validating parser which should report any errors it finds. For example,
$ xmllint --valid --noout invalidhotcop.xml
invalidhotcop.xml:10: element SONG: validity error : Element
SONG content does not follow the DTD, expecting
(TITLE , COMPOSER+ , PRODUCER* , PUBLISHER* , LENGTH? ,
YEAR? , ARTIST+), got (TITLE PRODUCER PUBLISHER LENGTH
YEAR ARTIST )
</SONG>
^
A valid document:
$ xmllint --valid --noout validhotcop.xml $
There are two levels of conformance to XML
Well-formed documents are correct with or without a DTD. They adhere to the basic syntax rules of XML
Valid documents also adhere to the constraints specified in a DTD
All valid documents are well-formed; not all well-formed document are valid.
A Document Type Definition (DTD) describes the elements and attributes that may appear in a document
Validation compares a particular document against a DTD
Well-formedness is a prerequisite for validity
A DTD lists the elements, attributes, and entities contained in a document
A DTD defines the relationships between different elements and attributes
A DTD for songs:
<!ELEMENT SONG (TITLE, COMPOSER+, PRODUCER*, PUBLISHER*,
LENGTH?, YEAR?, ARTIST+)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT ARTIST (#PCDATA)>Normally stored in a separate file
<?xml version="1.0"?>
<!DOCTYPE SONG [
<!ELEMENT SONG (TITLE, COMPOSER+, PRODUCER*, PUBLISHER*,
LENGTH?, YEAR?, ARTIST+)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT ARTIST (#PCDATA)>
]>
<SONG>
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<PUBLISHER>PolyGram Records</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>Ensures that data is correct before feeding it into a program
Ensures that a format is followed
Establishes what must be supported
Not all documents need to be valid; sometimes well-formed is enough
DTDs seem as obfuscated as C.
Comments can improve this by giving example elements
Comments are the same as in HTML; e.g. <!-- Comment -->
<!-- e.g. "1999 New York Women Composers",
not "Copyright 1999 New York Women Composers" -->
<!ELEMENT copyright (#PCDATA)>
Validity is optional.
Ask, "Does this document contain the information I need?"
Do not ask, "Does this document not contain anything I don't need?"
Validation can determine which process should handle any given document.
Humans count as processes for this purpose.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="song.css"?>
<!DOCTYPE SONG SYSTEM "intermediate_song.dtd">
<SONG CATEGORY="DISCO" ALBUM="The Best of the Village People">
<TITLE>Hot Cop</TITLE>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<LYRICS_AVAILABLE/>
<SHEET_MUSIC_AVAILABLE />
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<PUBLISHER URL="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST URL="http://www.officialvillagepeople.com/">Village People</ARTIST>
<!-- an empty element -->
<PHOTO SRC="hotcop.jpg" ALT="Victor Willis in Cop Outfit"
WIDTH="100" HEIGHT="200" />
<DESCRIPTION>
<!-- mixed content -->
<PERSON>Victor Willis</PERSON>'s theme song is
one of the lesser known of the <ARTIST>Village People</ARTIST>'s
<IRONIC>hits</IRONIC>, and <OPINION>deservedly so</OPINION>.
It never charted, <!-- need to verify this? -->
but they didn't have enough genuine
hits to fill a Best Of album, <OPINION>so some lesser numbers had
to be <METAPHOR>pulled out of the recycle bin</METAPHOR></OPINION>.
</DESCRIPTION>
</SONG>
<!-- You can tell what album I was
listening to when I wrote this example -->
At the top of the document, you normally find an XML declaration:
<?xml version="1.0" encoding="ISO-8859-1" standalone="yes"?>
version attribute
required
should have the value 1.0
standalone attribute
yes
no
encoding attribute
UTF-8
ISO-8859-1
etc.
Helps identify XML files
Helps humans
Works in non-XML contexts such as text editors and XInclude parse="text"
One caveat: don't include in XHTML
<LYRICS_AVAILABLE />
<SHEET_MUSIC_AVAILABLE />Ends with /> instead of >
<LYRICS_AVAILABLE/> is semantically the same as <LYRICS_AVAILABLE></LYRICS_AVAILABLE>
Just syntax sugar
<SONG CATEGORY="DISCO" ALBUM="The Best of the Village People">
...
<ARTIST URL="http://www.officialvillagepeople.com/">Village People</ARTIST>
<PHOTO SRC="hotcop.jpg" ALT="Victor Willis in Cop Outfit"
WIDTH="100" HEIGHT="200" />name="value" same as in HTML
or name='value' or name = 'value'
Generally used for meta-information
Attribute order is not significant
Attribute values are quoted with either single or double quotes:
Good:
<A HREF="http://www.cafeconleche.org/">
<DIV ALIGN='CENTER'>
<A HREF="http://www.cafeconleche.org/">
<EMBED SRC="minnesotaswale.aif" hidden="true">
Bad:
<A HREF=http://www.cafeconleche.org/>
<DIV ALIGN=CENTER>
<EMBED SRC=minnesotaswale.aif hidden=true>
<EMBED SRC="minnesotaswale.aif" hidden>
Attribute are for meta-data; elements are for data.
Does the reader want to see the information? If yes, use element content; if no, use attributes
Attributes are good for ID numbers, URLs, references, and other information not directly relevant to the reader
Attributes can't hold structure well.
Attributes cannot be duplicated on an element
Elements allow you to include meta-meta-data (information about the information about the information).
Not everyone always agrees on what is and isn't meta-data.
Elements are more extensible in the face of future changes.
<!-- You can tell what album I was
listening to when I wrote this example -->
Essentially the same as in HTML
Comments are for humans, not programs.
Some processes strip comments
Some APIs ignore comments
No JSP, PHP, ASP, script, style, etc. comments
Use processing instruvtions or elements instead
Divided into a target and data for the target
The target must be an XML name
The data can have an effectively arbitrary format
<?robots index="yes" follow="no"?>
<?xml-stylesheet href="pelicans.css" type="text/css"?>
<?php
mysql_connect("database.unc.edu", "clerk", "password");
$result = mysql("CYNW", "SELECT LastName, FirstName FROM Employees
ORDER BY LastName, FirstName");
$i = 0;
while ($i < mysql_numrows ($result)) {
$fields = mysql_fetch_row($result);
echo "<person>$fields[1] $fields[0] </person>\r\n";
$i++;
}
mysql_close();
?>
These are for programs
xml-stylesheet
PHP
robots
<DESCRIPTION>
<PERSON>Victor Willis</PERSON>'s theme song is
one of the lesser known of the
<ARTIST>Village People</ARTIST>'s <IRONIC>hits</IRONIC>,
and <OPINION>deservedly so</OPINION>. It never
charted, <!-- need to verify this? -->
but the group didn't have enough genuine
hits to fill a Best Of album, <OPINION>so some lesser
numbers had to be <METAPHOR>pulled out of the recycle
bin</METAPHOR></OPINION>.
</DESCRIPTION>Element order is significant
White space is significant
Applications may choose to ignore order and white space
Mixed content is not a mistake
Narrative documents exist
Order matters; an XML document is not a table
<!ELEMENT SONG (TITLE, PHOTO?, COMPOSER+, PRODUCER*,
LYRICS_AVAILABLE?, SHEET_MUSIC_AVAILABLE?,
PUBLISHER*, LENGTH?, YEAR?, ARTIST+,
PHOTO?, DESCRIPTION)>
<!ATTLIST SONG CATEGORY (DISCO | POP | ROCK) #REQUIRED
ALBUM CDATA #IMPLIED>
<!ATTLIST ARTIST URL CDATA #IMPLIED>
<!ATTLIST PUBLISHER URL CDATA #IMPLIED>
<!ELEMENT LYRICS_AVAILABLE EMPTY>
<!ELEMENT PHOTO EMPTY>
<!ELEMENT SHEET_MUSIC_AVAILABLE EMPTY>
<!ATTLIST PHOTO SRC CDATA #REQUIRED
ALT CDATA #REQUIRED
WIDTH CDATA #REQUIRED
HEIGHT CDATA #REQUIRED
>
<!ELEMENT ARTIST (#PCDATA)>
<!ELEMENT METAPHOR (#PCDATA)>
<!ELEMENT IRONIC (#PCDATA)>
<!ELEMENT PERSON (#PCDATA)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT COMPOSER (#PCDATA)>
<!ELEMENT PRODUCER (#PCDATA)>
<!ELEMENT PUBLISHER (#PCDATA)>
<!ATTLIST PUBLISHER xlink:type CDATA #IMPLIED
xlink:href CDATA #IMPLIED
>
<!ELEMENT LENGTH (#PCDATA)>
<!-- This should be a four digit year like "1999",
not a two-digit year like "99" -->
<!ELEMENT YEAR (#PCDATA)>
<!ELEMENT OPINION (#PCDATA | METAPHOR)*>
<!ELEMENT DESCRIPTION (#PCDATA | PERSON | IRONIC | OPINION
| METAPHOR | ARTIST | TITLE)*>
Let you mix and match different XML vocabularies
URIs identify elements and attributes that belong to different XML applications
Prefixes can change if the URI stay the same
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<ARTIST>Village People</ARTIST>
</SONG>
To distinguish between elements and attributes from different vocabularies with the same names.
To group all related elements and attributes together so that a parser can easily recognize them.
The XLink specification defines an attribute with the name href.
The XHTML specification also uses href attributes on some elements.
And the XInclude specification uses href attributes.
An XSLT style sheet that will transform XHTML documents containing both Scalable Vector Graphics (SVG) pictures and MathML equations into XSL-Formatting object documents.
The a, title, script,
style and font elements in XHTML and SVG
The table element in XHTML and XSL-FO
The text element in XSLT and SVG
The set element in MathML and SVG
An XSLT stylesheet that transforms a style sheet in an older version of the XSLT specification to a style sheet in a newer version of the XSLT specification.
Namespaces disambiguate elements with the same name from each other by attaching different prefixes to names from different XML applications.
Each prefix is associated with a URI.
Names whose prefixes are associated with the same URI are in the same namespace.
Names whose prefixes are associated with different URIs are in different namespaces.
Elements and attributes that are in namespaces have names that contain exactly one colon. They look like this:
rdf:description
xlink:type
xsl:template
Everything before the colon is called the prefix
Everything after the colon is called the local part.
The complete name including the colon is called the qualified name.
Each prefix in a qualified name is associated with a URI.
For example, all elements in XSLT 1.0 style sheets are associated with the http://www.w3.org/1999/XSL/Transform URI.
The customary prefix xsl is a shorthand for the longer URI
http://www.w3.org/1999/XSL/Transform.
You can't use the URI in the element name directly.
{http://www.w3.org/1999/XSL/Transform}template
Prefixes are bound to namespace URIs by attaching an xmlns:prefix
attribute to the prefixed element or one of its ancestors.
<svg:svg xmlns:svg="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<svg:ellipse rx="110" ry="130" />
<svg:rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg:svg>
Bindings have scope within the element where they're declared.
An SVG processor can recognize all three of these elements as SVG elements because they all have prefixes bound to the particular URI defined by the SVG specification.
<xhtml:html xmlns:xhtml="http://www.w3.org/1999/xhtml"
xmlns:xlink="http://www.w3.org/1999/xlink">
<xhtml:head><xhtml:title>Three Namespaces</xhtml:title></xhtml:head>
<xhtml:body>
<xhtml:h1 align="center">An Ellipse and a Rectangle</xhtml:h1>
<svg:svg xmlns:svg="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<svg:ellipse rx="110" ry="130" />
<svg:rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg:svg>
<xhtml:p xlink:type="simple"
xlink:href="ellipses.html">
More about ellipses
</xhtml:p>
<xhtml:p xlink:type="simple" xlink:href="rectangles.html">
More about rectangles
</xhtml:p>
<xhtml:hr/>
<xhtml:p>Last Modified February 13, 2000</xhtml:p>
</xhtml:body>
</xhtml:html>Indicate that an unprefixed element and all its unprefixed descendant
elements belong to a particular namespace by attaching an xmlns
attribute with no prefix:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:xlink="http://www.w3.org/1999/xlink">
<head><title>Three Namespaces</title></head>
<body>
<h1 align="center">An Ellipse and a Rectangle</h1>
<svg:svg xmlns:svg="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<svg:ellipse rx="110" ry="130" />
<svg:rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg:svg>
<p xlink:type="simple"
xlink:href="ellipses.html">
More about ellipses
</p>
<p xlink:type="simple" xlink:href="rectangles.html">
More about rectangles
</p>
<hr/>
<p>Last Modified February 13, 2000</p>
</body>
</html>Both the html and head elements are in the
http://www.w3.org/1999/xhtml namespace.
Default namespaces apply only to elements, not to attributes.
Thus in the above example the align, rx, ry, x, and y attributes are not in any namespace.
You can change the default namespace within a particular
element by adding an xmlns attribute to the element:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:xlink="http://www.w3.org/1999/xlink">
<head><title>Three Namespaces</title></head>
<body>
<h1 align="center">An Ellipse and a Rectangle</h1>
<svg xmlns="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<ellipse rx="110" ry="130" />
<rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg>
<p xlink:type="simple"
xlink:href="ellipses.html">
More about ellipses
</p>
<p xlink:type="simple" xlink:href="rectangles.html">
More about rectangles
</p>
<hr/>
<p>Last Modified February 13, 2000</p>
</body>
</html>Unprefixed attributes are never in any namespace.
Being an attribute of an element in the http://www.w3.org/1999/xhtml namespace is not sufficient to put the attribute in the http://www.w3.org/1999/xhtml namespace.
The only way an attribute belongs to a namespace is if it has a declared prefix, like xlink:type and xlink:href.
Many XML applications have recommended prefixes. For example, SVG elements often use the prefix svg and Resource Description Framework (RDF) elements often have the prefix rdf. However, these prefixes are simply conventions, and can be changed based on necessity, convenience or whim.
Before a prefix can be used, it must be bound to a URI.
These URIs are standardized, not the prefixes.
The prefix can change as long as the URI stays the same.
Purely formal
Can point somewhere but do not have to
Parsers compare namespace URIs on a character by character basis. These are three different namespaces:
http://www.w3.org/1999/XSL/Transform
http://www.w3.org/1999/XSL/Transform/
http://www.w3.org/1999/XSL/Transform/index.html
DTDs must declare the qualified names
<!ELEMENT svg:text (#PCDATA)>
If the prefix changes, the DTD needs to change too.
Parameter entity references can help when the prefix changes or is removed:
<!ENTITY % mathml-colon ''>
<!ENTITY % mathml-prefix ''>
<!ENTITY % mathml-exp '%mathml-prefix;%mathml-colon;exp' >
<!ENTITY % mathml-abs '%mathml-prefix;%mathml-colon;abs' >
<!ENTITY % mathml-arg '%mathml-prefix;%mathml-colon;arg' >
<!ENTITY % mathml-real '%mathml-prefix;%mathml-colon;real' >
<!ENTITY % mathml-imaginary '%mathml-prefix;%mathml-colon;imaginary' >
DTDs need to declare the xmlns and
xmlns:prefix attributes too:
<!ATTLIST svg xmlns (CDATA)
#FIXED "http://www.w3.org/2000/svg">
<!ATTLIST svg:svg xmlns:svg (CDATA)
#FIXED "http://www.w3.org/2000/svg">
Hexadecimal or Decimal
Does not require DTD to be Read
Works With Schemas
Domain-Specific (Vertical) Markup Languages
Self-Describing Data
Interchange of Data Among Applications
Structured and Integrated Data
Markup language for a vertical market
Non-proprietary format
Don't pay for what you don't use
Much data is lost due to format problems
XML is very simple
XML is self-describing
XML is well documented
<PERSON ID="p1100" SEX="M">
<NAME>
<GIVEN>Judson</GIVEN>
<SURNAME>McDaniel</SURNAME>
</NAME>
<BIRTH>
<DATE>21 Feb 1834</DATE>
</BIRTH>
<DEATH>
<DATE>9 Dec 1905</DATE>
</DEATH>
</PERSON>
E-commerce
Syndication
EAI and EDI
A document can be assembled from multiple physical storage entities
These may be files, database queries, or anything that can be referred to by a URI
Can even include non-XML content
A specific markup language that uses the XML meta-syntax is called an XML application
Different XML applications have their own more constricted syntaxes and vocabularies within the broader XML syntax
Further syntax can be layered on top of this; e.g. data typing through schemas
Web Pages
Mathematical Equations
Music Notation
Vector Graphics
Web Services
and more...
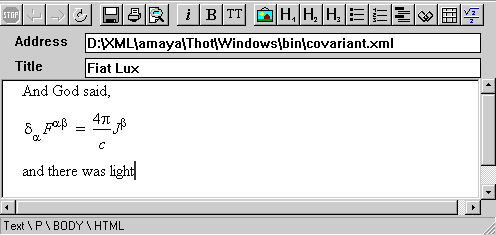
<?xml version="1.0"?>
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"../xhtml1/transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Fiat Lux</title>
</head>
<body>
<p>
And God said,
</p>
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mrow>
<msub>
<mi>δ</mi>
<mi>α</mi>
</msub>
<msup>
<mi>F</mi>
<mi>αβ</mi>
</msup>
<mo>=</mo>
<mfrac>
<mrow>
<mn>4</mn>
<mi>π</mi>
</mrow>
<mi>c</mi>
</mfrac>
<msup>
<mi>J</mi>
<mrow>
<mi>β</mi>
</mrow>
</msup>
</mrow>
</math>
<p>
and there was light.
</p>
</body>
</html>
<?xml version="1.0"?>
<rss version="0.92">
<channel>
<title>Cafe con Leche XML News and Resources</title>
<link>http://www.cafeconleche.org/</link>
<description>Cafe con Leche is the preeminent independent source of XML information on the net. Cafe con Leche is neither beholden to specific companies nor to advertisers. At Cafe con Leche you'll find many resources to help you develop your XML skills here including daily news summaries, examples, book reviews, mailing lists and more.</description>
<language>en-us</language>
<copyright>Copyright 2005 Elliotte Rusty Harold</copyright>
<webMaster>elharo@metalab.unc.edu</webMaster>
<image>
<title>Cafe con Leche</title>
<url>http://www.cafeconleche.org/cup.gif</url>
<link>http://www.cafeconleche.org/</link>
<width>89</width>
<height>67</height>
<description>Cafe con Leche is the preeminent independent source of XML information on the net. Cafe con Leche is neither beholden to specific companies nor to advertisers. At Cafe con Leche you'll find many resources to help you develop your XML skills here including daily news summaries, examples, book reviews, mailing lists and more.</description>
</image>
<item>
<title>IBM developerWorks has published my latest article, Encode your XML documents in UTF-8.
</title>
<description>IBM developerWorks has published my latest article, Encode your XML documents in UTF-8. In this article inspired by Google's Sitemaps service, I explain why I think it's time to stop bothering with other encodings and just choose UTF-8 once and for all.</description>
<link>http://www.cafeconleche.org/#news2005September2</link>
</item>
<item>
<title>The Apache XML Project has released version 2.7.0 of Xerces-C, an open source schema validating XML parser written in reasonably cross-platform C++.
</title>
<description>The Apache XML Project has released version 2.7.0 of Xerces-C, an open source schema validating XML parser written in reasonably cross-platform C++. Version 2.7.0 includes a number of small improvements: More...</description>
<link>http://www.cafeconleche.org/#news2005September2</link>
</item>
</channel>
</rss>
Scalable Vector Graphics (SVG)
Adobe SVG Plug-In
Apache Batik
Objects
Tables
XSL: The Extensible Stylesheet Language
XLink: The Extensible Linking Language
Data typing in XML is weak
DTDs use a strange non-XML syntax
Limited compatibility with namespaces
Limited extensibility
Schemas fix all these problems
There are multiple schema languages including:
Rick Jelliffe's Schematron
Murato Makoto's and James Clark's RELAX NG
The W3C XML Schema Language
<?xml version="1.0"?>
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="SONG" type="SongType"/>
<xsd:complexType name="SongType">
<xsd:sequence>
<xsd:element name="TITLE" type="xsd:string"
minOccurs="1" maxOccurs="1"/>
<xsd:element name="COMPOSER" type="xsd:string"
minOccurs="1" maxOccurs="unbounded"/>
<xsd:element name="PRODUCER" type="xsd:string"
minOccurs="0" maxOccurs="unbounded"/>
<xsd:element name="PUBLISHER" type="xsd:string"
minOccurs="0" maxOccurs="1"/>
<xsd:element name="LENGTH" type="xsd:duration"
minOccurs="0" maxOccurs="1"/>
<xsd:element name="YEAR" type="xsd:gYear"
minOccurs="1" maxOccurs="1"/>
<xsd:element name="ARTIST" type="xsd:string"
minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>Any element can be a link
Links can be bi-directional
Links can be separated from the documents they connect
<footnote xlink:type="simple" xlink:href="footnote7.xml">7</footnote>
Microsoft Office 2000
Netscape What's Related
JPEG
MP3
Quicktime
You need a JDK
You need some free class libraries
You need a text editor
You need some data to process
Push: SAX, XNI
Tree: DOM, JDOM, XOM, dom4j, Sparta
Data binding: Castor, Zeus, JAXB
Pull: XMLPULL, StAX, NekoPull
Transform: XSLT, TrAX, XQuery
SAX, the Simple API for XML
SAX1
SAX2
DOM, the Document Object Model
DOM Level 0
DOM Level 1
DOM Level 2
DOM Level 3
JDOM
dom4j
XOM
TrAX
XMLPULL
StAX
Proprietary APIs
Parser specific APIs
Sun's Java API for XML Parsing = SAX1 + DOM1 + a few factory classes
JSR-000031 XML Data Binding Specification from Bluestone, Sun, webMethods et al.
The proposed specification will define an XML data-binding facility for the JavaTM Platform. Such a facility compiles an XML schema into one or more Java classes. These automatically-generated classes handle the translation between XML documents that follow the schema and interrelated instances of the derived classes. They also ensure that the constraints expressed in the schema are maintained as instances of the classes are manipulated.
The Infoset is the unfortunate standard to which those in retreat from the radical and most useful implications of well-formedness have rallied. At its core the Infoset insists that there is 'more' to XML than the straightforward syntax of well-formedness. By imposing its canonical semantics the Infoset obviates the infinite other semantic outcomes which might be elaborated in particular unique circumstances from an instance of well-formed XML 1.0 syntax. The question we should be asking is not whether the Infoset has chosen the correct canonical semantics, but whether the syntactic possibilities of XML 1.0 should be curtailed in this way at all.--Walter Perry on the xml-dev mailing list
Markup includes:
Tags
Entity References
Comments
Processing Instructions
Document Type Declarations
XML Declaration
CDATA Section Delimiters
Character data includes everything else
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/css" href="song.css"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<SONG xmlns="http://www.cafeconleche.org/namespace/song"
xmlns:xlink="http://www.w3.org/1999/xlink">
<TITLE>Hot Cop</TITLE>
<PHOTO
xlink:type="simple" xlink:show="onLoad" xlink:href="hotcop.jpg"
ALT="Victor Willis in Cop Outfit" WIDTH="100" HEIGHT="200"/>
<COMPOSER>Jacques Morali</COMPOSER>
<COMPOSER>Henri Belolo</COMPOSER>
<COMPOSER>Victor Willis</COMPOSER>
<PRODUCER>Jacques Morali</PRODUCER>
<!-- The publisher is actually Polygram but I needed
an example of a general entity reference. -->
<PUBLISHER xlink:type="simple" xlink:href="http://www.amrecords.com/">
A & M Records
</PUBLISHER>
<LENGTH>6:20</LENGTH>
<YEAR>1978</YEAR>
<ARTIST>Village People</ARTIST>
</SONG>
<!-- You can tell what album I was
listening to when I wrote this example -->
An XML document is made up of one or more physical storage units called entities
Entity references:
Parsed internal general entity references like &
Parsed external general entity references
Unparsed external general entity references
External parameter entity references
Internal parameter entity references
Reading an XML document is not the same thing as reading an XML file
The file contains entity references.
The document contains the entities' replacement text.
When you use a parser to read a document you'll get the text including characters like <. You will not see the entity references.
Character data left after entity references are replaced with their text
Given the element
<PUBLISHER>A & M Records</PUBLISHER>
The parsed character data is
A & M Records
Used to include large blocks of text with lots of normally
illegal literal characters like
< and &, typically XML or HTML.
<p>You can use a default <code>xmlns</code>
attribute to avoid having to add the svg prefix to all
your elements:</p>
<![CDATA[
<svg xmlns="http://www.w3.org/2000/svg"
width="12cm" height="10cm">
<ellipse rx="110" ry="130" />
<rect x="4cm" y="1cm" width="3cm" height="6cm" />
</svg>
]]>
CDATA is for human authors, not for programs!
Namespaces were added to XML 1.0 after the fact, but care was taken to ensure backwards compatibility.
An XML 1.0 parser that does not know about namespaces will most likely not have any troubles reading a document that uses namespaces.
A namespace aware parser also checks to see that all prefixes are mapped to URIs. Otherwise it behaves almost exactly like a non-namespace aware parser.
Other software that sits on top of the raw XML parser, an XSLT engine for example, may treat elements differently depending on what namespace they belong to. However, the XML parser itself mostly doesn't care as long as all well-formedness and namespace constraints are met.
A possible exception occurs in the unlikely event that elements with different prefixes belong to the same namespace or elements with the same prefix belong to different namespaces
Many parsers have the option of whether to report namespace violations so that you can turn namespace processing on or off as you see fit.
| Semantics |
| Structure |
| Syntax |
| Lexical |
| Binary |
I have learned to be even more skeptical than before about the slew of APIs doing the rounds in the XML development community. An XML instance is just a documents, guys; you need to understand the document structure and document interchange choreography of your systems. Don't let some API get in the way of your understanding of XML systems at the document level. If you do, you run the risk becoming a slave to the APIs and hitting a wall when the APIs fail you.
--Sean McGrath
Read the rest in ITworld.com - XML IN PRACTICE - APIs Considered Harmful
XML documents are text
Any Writer can produce an XML document
XML documents and APIs are Unicode
Unicode encodings:
UTF-8
UTF-16 big endian
UCS-4 big endian
UTF-16 little endian
UCS-4 little endian
Non-Unicode encodings:
ASCII (subset of UTF-8)
MacRoman
Windows ANSI
Latin 1 through Latin 15
SJIS Japanese
Big-5 Chinese
K0I8R Cyrillic
Many others...
Java's InputStreamReader and OutputStreamWriter
classes are very helpful
URL u = new URL(
"http://www.ascc.net/xml/test/wfdtd/utf-8/application_xml/zh-utf8-8.xml");
InputStream in = u.openStream();
InputStreamReader reader = new InputStreamReader(in, "UTF-8");
int c;
while ((c = in.read()) != -1) System.out.write(c);
import java.math.BigInteger;
import java.io.*;
public class FibonacciText {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("fibonacci.txt");
Writer out = new OutputStreamWriter(fout, "8859_1");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
for (int i = 1; i <= 25; i++) {
out.write(low.toString() + "\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write(high.toString() + "\r\n");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
1
1
2
3
5
8
13
21
34
55
89
144
233
377
610
987
1597
2584
4181
6765
10946
17711
28657
46368
75025
121393
317811
import java.math.BigInteger;
import java.io.*;
public class FibonacciXML {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("fibonacci.xml");
Writer out = new OutputStreamWriter(fout, "UTF-8");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
out.write("<?xml version=\"1.0\"?>\r\n");
out.write("<Fibonacci_Numbers>\r\n");
for (int i = 1; i <= 25; i++) {
out.write(" <fibonacci index=\"" + i + "\">");
out.write(low.toString());
out.write("</fibonacci>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</Fibonacci_Numbers>");
out.close();
}
catch (IOException ex) {
System.err.println(ex);
}
}
}
<?xml version="1.0"?>
<Fibonacci_Numbers>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>import java.math.BigInteger;
import java.io.*;
public class FibonacciApos {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("fibonacci_apos.xml");
Writer out = new OutputStreamWriter(fout);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
out.write("<?xml version='1.0'?>\r\n");
out.write("<Fibonacci_Numbers>\r\n");
for (int i = 1; i <= 25; i++) {
out.write(" <fibonacci index='" + i + "'>");
out.write(low.toString());
out.write("</fibonacci>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</Fibonacci_Numbers>");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
import java.math.BigInteger;
import java.io.*;
public class FibonacciDTD {
public static void main(String[] args) {
try {
OutputStream fout = new FileOutputStream("valid_fibonacci.xml");
Writer out = new OutputStreamWriter(fout, "UTF-8");
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
out.write("<?xml version=\"1.0\"?>\r\n");
out.write("<!DOCTYPE Fibonacci_Numbers [\r\n");
out.write(" <!ELEMENT Fibonacci_Numbers (fibonacci*)>\r\n");
out.write(" <!ELEMENT fibonacci (#PCDATA)>\r\n");
out.write(" <!ATTLIST fibonacci index CDATA #IMPLIED>\r\n");
out.write("]>\r\n");
out.write("<Fibonacci_Numbers>\r\n");
for (int i = 1; i <= 25; i++) {
out.write(" <fibonacci index=\"" + i + "\">");
out.write(low.toString());
out.write("</fibonacci>\r\n");
BigInteger temp = high;
high = high.add(low);
low = temp;
}
out.write("</Fibonacci_Numbers>");
out.close();
}
catch (IOException e) {
System.err.println(e);
}
}
}
<?xml version="1.0"?>
<!DOCTYPE Fibonacci_Numbers [
<!ELEMENT Fibonacci_Numbers (fibonacci*)>
<!ELEMENT fibonacci (#PCDATA)>
<!ATTLIST fibonacci index CDATA #IMPLIED>
]>
<Fibonacci_Numbers>
<fibonacci index="0">0</fibonacci>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
</Fibonacci_Numbers>Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 3-4:
Chapter 3, Writing XML with Java: http://www.cafeconleche.org/books/xmljava/chapters/ch03.html
Chapter 4, Converting Flat Files to XML: http://www.cafeconleche.org/books/xmljava/chapters/ch04.html
For streams and readers and writers:

Java I/O
Elliotte Rusty Harold
O'Reilly & Associates, 1999
ISBN: 1-56592-485-1
Actually, SAX2 has ** MUCH ** better infoset support than DOM does. Yes, I've done the detailed analysis.
--David Brownell on the xml-dev mailing list
The stereotypical "Desperate Perl Hacker" (DPH) is supposed to be able to write an XML parser in a weekend.
The parser does the hard work for you.
Your code reads the document through the parser's API.
Public domain, developed on xml-dev mailing list
Maintained by David Megginson
org.xml.sax package
Event based
| Parser | URL | Validating | Namespaces | SAX1 | SAX2 | License |
|---|---|---|---|---|---|---|
| Yuval Oren's Piccolo | http://piccolo.sourceforge.net/ | X | X | X | LGPL | |
| Apache XML Project's Xerces Java | http://xml.apache.org/xerces2-j/index.html | X | X | X | X | Apache Software License, Version 1.1 |
| IBM's XML for Java | http://www.alphaworks.ibm.com/formula/xml | X | X | X | X | Apache Software License, Version 1.1 |
| Ælfred | http://www.gnu.org/software/classpathx/jaxp/jaxp.html | X | X | X | X | GPL with library exception |
| Sun's Crimson | http://xml.apache.org/crimson/ | X | X | X | X | Apache |
| Oracle's XML Parser for Java | http://technet.oracle.com/ | X | X | X | X | free beer |
| Caucho Resin | http://www.caucho.com/products/resin-xml/index.xtp | ? | X | X | X | payware |
| Saxon's AElfred | http://saxon.sourceforge.net/aelfred.html | X | X | X | BSD-ish license |
Java 1.4.x bundle Crimson and Xalan
These are loaded before anything in the CLASSPATH or jre/lib/ext directory
Use jre/lib/endorsed to override (You must create this directory.)
Saxon is incompatible with Ant.
Use the factory method
XMLReaderFactory.createXMLReader()
to retrieve a parser-specific implementation of the
XMLReader interface
Your code registers a ContentHandler with the parser
An InputSource feeds the document into the parser
As the document is read, the parser calls back to the
methods of the ContentHandler to tell it
what it's seeing in the document.
The XMLReaderFactory.createXMLReader() method
instantiates an XMLReader subclass named by
the org.xml.sax.driver system property:
try {
XMLReader parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
System.err.println(e);
}or
System.setProperty("org.xml.sax.driver", "org.apache.xerces.parsers.SAXParser");
try {
XMLReader parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException e) {
System.err.println(e);
}The XMLReaderFactory.createXMLReader(String className) method
instantiates an XMLReader subclass named by
its argument:
try {
XMLReader parser
= XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e) {
System.err.println(e);
}Or you can use the constructor in the package-specific class:
XMLReader parser = new org.apache.xerces.parsers.SAXParser();
Or all three:
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException ex2) {
parser = new org.apache.xerces.parsers.SAXParser();
}
}import org.xml.sax.*;
import org.xml.sax.helpers.*;
import java.io.*;
public class SAX2Checker {
public static void main(String[] args) {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
try {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException ex2) {
System.out.println("Could not locate a parser."
+ "Please set the the org.xml.sax.driver property.");
return;
}
}
if (args.length == 0) {
System.out.println("Usage: java SAX2Checker URL1 URL2...");
}
// start parsing...
for (int i = 0; i < args.length; i++) {
// command line should offer URIs or file names
try {
parser.parse(args[i]);
// If there are no well-formedness errors
// then no exception is thrown
System.out.println(args[i] + " is well formed.");
}
catch (SAXParseException e) { // well-formedness error
System.out.println(args[i] + " is not well formed.");
System.out.println(e.getMessage()
+ " at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) { // some other kind of error
System.out.println(e.getMessage());
}
catch (IOException e) {
System.out.println("Could not check " + args[i]
+ " because of the IOException " + e);
}
}
}
}C:\>java SAX2Checker http://www.cafeconleche.org/
http://www.cafeconleche.org/ is not well formed.
The element type "dt" must be terminated by the
matching end-tag "</dt>".
at line 186, column 5
Under no circumstances, should you ever use javax.xml.parsers.SAXParser
or SAXParserFactory
These classes were designed to fill holes in SAX1. They are unnecessary and actively harmful when working with SAX2.
Use XMLReader
and XMLReaderFactory instead
package org.xml.sax;
public interface ContentHandler {
public void setDocumentLocator(Locator locator);
public void startDocument() throws SAXException;
public void endDocument() throws SAXException;
public void startPrefixMapping(String prefix, String uri)
throws SAXException;
public void endPrefixMapping(String prefix) throws SAXException;
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException;
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException;
public void characters(char[] text, int start, int length)
throws SAXException;
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException;
public void processingInstruction(String target, String data)
throws SAXException;
public void skippedEntity(String name) throws SAXException;
}UserLand's RSS based list of Web logs at http://static.userland.com/weblogMonitor/logs.xml:
<?xml version="1.0"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl></imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description></description>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
Design Decisions
Should we return an array, an Enumeration,
a List, or what?
Perhaps we should use multiple threads?
We do not know how many URLs there will be when we start parsing
so let's use a Vector
Single threaded for simplicity but a real program would use multiple threads
One to load and parse the data
Another thread (probably the main thread) to serve the data
Early data could be provided before the entire document had been read
The character data of each url element needs to be stored.
Everything else can be ignored.
A startElement() with the name
url indicates that we need to start
storing this data.
An endElement() with the name url indicates that we need to stop
storing this data, convert it to a URL and put it in the
Vector
Should we hide the XML parsing inside a non-public class to avoid accidentally calling the methods from unexpected places or threads?
import org.xml.sax.*;
import org.xml.sax.helpers.XMLReaderFactory;
import java.util.*;
import java.io.*;
public class WeblogsSAX {
public static List listChannels()
throws IOException, SAXException {
return listChannels(
"http://static.userland.com/weblogMonitor/logs.xml");
}
public static List listChannels(String uri)
throws IOException, SAXException {
XMLReader parser;
try {
parser = XMLReaderFactory.createXMLReader();
}
catch (SAXException ex) {
parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
}
Vector urls = new Vector(1000);
ContentHandler handler = new URIGrabber(urls);
parser.setContentHandler(handler);
parser.parse(uri);
return urls;
}
public static void main(String[] args) {
try {
List urls;
if (args.length > 0) urls = listChannels(args[0]);
else urls = listChannels();
Iterator iterator = urls.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
catch (IOException e) {
System.err.println(e);
}
catch (SAXParseException e) {
System.err.println(e);
System.err.println("at line " + e.getLineNumber()
+ ", column " + e.getColumnNumber());
}
catch (SAXException e) {
System.err.println(e);
}
catch (/* Unexpected */ Exception e) {
e.printStackTrace();
}
}
}
import org.xml.sax.*;
import java.net.*;
import java.util.Vector;
// conflicts with java.net.ContentHandler
class URIGrabber implements org.xml.sax.ContentHandler {
private Vector urls;
URIGrabber(Vector urls) {
this.urls = urls;
}
// do nothing methods
public void setDocumentLocator(Locator locator) {}
public void startDocument() throws SAXException {}
public void endDocument() throws SAXException {}
public void startPrefixMapping(String prefix, String uri)
throws SAXException {}
public void endPrefixMapping(String prefix) throws SAXException {}
public void skippedEntity(String name) throws SAXException {}
public void ignorableWhitespace(char[] text, int start, int length)
throws SAXException {}
public void processingInstruction(String target, String data)
throws SAXException {}
// Remember, there's no guarantee all the text of the
// url element will be returned in a single call to characters
private StringBuffer urlBuffer;
private boolean collecting = false;
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes atts) throws SAXException {
if (qualifiedName.equals("url")) {
collecting = true;
urlBuffer = new StringBuffer();
}
}
public void characters(char[] text, int start, int length)
throws SAXException {
if (collecting) {
urlBuffer.append(text, start, length);
}
}
public void endElement(String namespaceURI, String localName,
String qualifiedName) throws SAXException {
if (qualifiedName.equals("url")) {
collecting = false;
String url = urlBuffer.toString();
try {
urls.addElement(new URL(url));
}
catch (MalformedURLException e) {
// skip this url
}
}
}
}% java Weblogs shortlogs.xml
http://www.mozillazine.org
http://www.salonherringwiredfool.com/
http://www.slashdot.org/
You do not always have all the information you need at the time of a given callback
You may need to store information in various data structures (stacks, queues,vectors, arrays, etc.) and act on it at a later point
For example the characters() method is not guaranteed
to give you the maximum number of contiguous characters. It may
split a single run of characters over multiple method calls.
Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 6-8:
Chapter 6, SAX: http://www.cafeconleche.org/books/xmljava/chapters/ch06.html
Chapter 7, The XMLReader Interface: http://www.cafeconleche.org/books/xmljava/chapters/ch07.html
Chapter 8, SAX Filters: http://www.cafeconleche.org/books/xmljava/chapters/ch08.html
 XML in a Nutshell, third edition
XML in a Nutshell, third edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2004
ISBN 0-596-00764-7
SAX website: http://www.saxproject.org/
The DOM (like XML) is not a triumph of elegance; it's a triumph of "if we do not hang together, we shall hang separately." At least the Browser Wars were not followed by API Wars. Better a common API that we all love to hate than a bazillion contending APIs that carve the Web up into contending enclaves of True Believers.
--Mike Champion on the xml-dev mailing list, Thursday, September 27, 2001
An XML document can be represented as a tree.
It has a root.
It has nodes.
It is amenable to recursive processing.
Not all applications agree on what the root is.
Not all applications agree on what is and isn't a node.
Defines how XML and HTML documents are represented as objects in programs
Defined in IDL; thus language independent
HTML as well as XML
Writing as well as reading
Covers everything except internal and external DTD subsets
DOM focuses more on the document; SAX focuses more on the parser.
DOM Level 0:
DOM Level 1, a W3C Standard
DOM Level 2, a W3C Standard
DOM Level 3: Several Working Drafts:
Document Object Model (DOM) Level 3 XPath Specification Version 1.0
Document Object Model (DOM) Level 3 Load and Save Specification
Document Object Model (DOM) Level 3 Validation Specification
Document Object Model (DOM) Level 3 Views and Formatting Specification
Document Object Model (DOM) Level 3 Events Specification Version 1.0
Apache XML Project's Xerces Java: http://xml.apache.org/xerces-j/index.html
IBM's XML for Java: http://www.alphaworks.ibm.com/formula/xml
Sun's Java API for XML http://java.sun.com/products/xml
GNU JAXP: http://www.gnu.org/software/classpathx/jaxp/jaxp.html
Eight Modules:
Core: org.w3c.dom *
HTML: org.w3c.dom.html
Views: org.w3c.dom.views
StyleSheets: org.w3c.dom.stylesheets
CSS: org.w3c.dom.css
Events: org.w3c.dom.events *
Traversal: org.w3c.dom.traversal *
Range: org.w3c.dom.range
Only the core and traversal modules really apply to XML. The other six are for HTML.
* indicates Xerces support
Entire document is represented as a tree.
A tree contains nodes.
Some nodes may contain other nodes (depending on node type).
Each document node contains:
zero or one doctype nodes
one root element node
zero or more comment and processing instruction nodes
17 interfaces:
Attr
CDATASection
CharacterData
Comment
Document
DocumentFragment
DocumentType
DOMImplementation
Element
Entity
EntityReference
NamedNodeMap
Node
NodeList
Notation
ProcessingInstruction
Text
plus one exception:
DOMException
Plus a bunch of HTML stuff in org.w3c.dom.html
and other packages
we will ignore
Library specific code creates a parser
The parser parses the document and returns a DOM
org.w3c.dom.Document object.
The entire document is stored in memory.
DOM methods and interfaces are used to extract data from this object
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class DOMParserMaker {
public static void main(String[] args) {
// This is simpler but less flexible than the SAX approach.
// Perhaps a good creational design pattern is needed here?
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document d = parser.getDocument();
// work with the document...
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
}
}javax.xml.parsers.DocumentBuilderFactory.newInstance()
creates a DocumentBuilderFactory
Configure the factory
The factory's newBuilder() method
creates a DocumentBuilder
Configure the builder
The builder parses the document and returns a DOM
org.w3c.dom.Document object.
The entire document is stored in memory.
DOM methods and interfaces are used to extract data from this object
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class JAXPParserMaker {
public static void main(String[] args) {
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
builderFactory.setNamespaceAware(true);
DocumentBuilder parser
= builderFactory.newDocumentBuilder();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
Document d = parser.parse(args[i]);
// work with the document...
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
} // end for
}
catch (ParserConfigurationException e) {
System.err.println("You need to install a JAXP aware parser.");
}
}
}
package org.w3c.dom;
public interface Node {
// NodeType
public static final short ELEMENT_NODE = 1;
public static final short ATTRIBUTE_NODE = 2;
public static final short TEXT_NODE = 3;
public static final short CDATA_SECTION_NODE = 4;
public static final short ENTITY_REFERENCE_NODE = 5;
public static final short ENTITY_NODE = 6;
public static final short PROCESSING_INSTRUCTION_NODE = 7;
public static final short COMMENT_NODE = 8;
public static final short DOCUMENT_NODE = 9;
public static final short DOCUMENT_TYPE_NODE = 10;
public static final short DOCUMENT_FRAGMENT_NODE = 11;
public static final short NOTATION_NODE = 12;
public String getNodeName();
public String getNodeValue() throws DOMException;
public void setNodeValue(String nodeValue) throws DOMException;
public short getNodeType();
public Node getParentNode();
public NodeList getChildNodes();
public Node getFirstChild();
public Node getLastChild();
public Node getPreviousSibling();
public Node getNextSibling();
public NamedNodeMap getAttributes();
public Document getOwnerDocument();
public Node insertBefore(Node newChild, Node refChild) throws DOMException;
public Node replaceChild(Node newChild, Node oldChild) throws DOMException;
public Node removeChild(Node oldChild) throws DOMException;
public Node appendChild(Node newChild) throws DOMException;
public boolean hasChildNodes();
public Node cloneNode(boolean deep);
public void normalize();
public boolean supports(String feature, String version);
public String getNamespaceURI();
public String getPrefix();
public void setPrefix(String prefix) throws DOMException;
public String getLocalName();
}package org.w3c.dom;
public interface NodeList {
public Node item(int index);
public int getLength();
}
Now we're really ready to read a document
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
public class NodeReporter {
public static void main(String[] args) {
try {
DocumentBuilderFactory builderFactory
= DocumentBuilderFactory.newInstance();
DocumentBuilder parser
= builderFactory.newDocumentBuilder();
NodeReporter iterator = new NodeReporter();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
Document doc = parser.parse(args[i]);
iterator.followNode(doc);
}
catch (SAXException ex) {
System.err.println(args[i] + " is not well-formed.");
}
catch (IOException ex) {
System.err.println(ex);
}
}
}
catch (ParserConfigurationException ex) {
System.err.println("You need to install a JAXP aware parser.");
}
} // end main
// note use of recursion
public void followNode(Node node) {
processNode(node);
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
followNode(children.item(i));
}
}
}
public void processNode(Node node) {
String name = node.getNodeName();
String type = getTypeName(node.getNodeType());
System.out.println("Type " + type + ": " + name);
}
public static String getTypeName(int type) {
switch (type) {
case Node.ELEMENT_NODE:
return "Element";
case Node.ATTRIBUTE_NODE:
return "Attribute";
case Node.TEXT_NODE:
return "Text";
case Node.CDATA_SECTION_NODE:
return "CDATA Section";
case Node.ENTITY_REFERENCE_NODE:
return "Entity Reference";
case Node.ENTITY_NODE:
return "Entity";
case Node.PROCESSING_INSTRUCTION_NODE:
return "Processing Instruction";
case Node.COMMENT_NODE :
return "Comment";
case Node.DOCUMENT_NODE:
return "Document";
case Node.DOCUMENT_TYPE_NODE:
return "Document Type Declaration";
case Node.DOCUMENT_FRAGMENT_NODE:
return "Document Fragment";
case Node.NOTATION_NODE:
return "Notation";
default:
return "Unknown Type";
}
}
}% java NodeReporter hotcop.xml Type Document: #document Type Processing Instruction: xml-stylesheet Type Document Type Declaration: SONG Type Element: SONG Type Text: #text Type Element: TITLE Type Text: #text Type Text: #text Type Element: PHOTO Type Text: #text Type Element: COMPOSER Type Text: #text Type Text: #text Type Element: COMPOSER Type Text: #text Type Text: #text Type Element: COMPOSER Type Text: #text Type Text: #text Type Element: PRODUCER Type Text: #text Type Text: #text Type Comment: #comment Type Text: #text Type Element: PUBLISHER Type Text: #text Type Text: #text Type Element: LENGTH Type Text: #text Type Text: #text Type Element: YEAR Type Text: #text Type Text: #text Type Element: ARTIST Type Text: #text Type Text: #text Type Comment: #comment
Attributes are missing from this output. They are not nodes. They are properties of nodes.
| Node Type | Node Value |
|---|---|
| element node | null |
| attribute node | attribute value |
| text node | text of the node |
| CDATA section node | text of the section |
| entity reference node | null |
| entity node | null |
| processing instruction node | content of the processing instruction, not including the target |
| comment node | text of the comment |
| document node | null |
| document type declaration node | null |
| document fragment node | null |
| notation node | null |
The root node representing the entire document; not the same as the root element
Contains:
one element node
zero or more processing instruction nodes
zero or more comment nodes
zero or one document type nodes
package org.w3c.dom;
public interface Document extends Node {
public DocumentType getDoctype();
public DOMImplementation getImplementation();
public Element getDocumentElement();
public NodeList getElementsByTagName(String tagname);
public NodeList getElementsByTagNameNS(String namespaceURI, String localName);
public Element getElementById(String elementId);
// Factory methods
public Element createElement(String tagName) throws DOMException;
public Element createElementNS(String namespaceURI, String qualifiedName) throws DOMException;
public DocumentFragment createDocumentFragment();
public Text createTextNode(String data);
public Comment createComment(String data);
public CDATASection createCDATASection(String data) throws DOMException;
public ProcessingInstruction createProcessingInstruction(String target, String data)
throws DOMException;
public Attr createAttribute(String name) throws DOMException;
public Attr createAttributeNS(String namespaceURI, String qualifiedName) throws DOMException;
public EntityReference createEntityReference(String name) throws DOMException;
public Node importNode(Node importedNode, boolean deep) throws DOMException;
}
UserLand's RSS based list of Web logs at http://static.userland.com/weblogMonitor/logs.xml:
<?xml version="1.0"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization. DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl></imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description></description>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
We can easily find out how many URLs there will be when we finish parsing, since they're all in memory.
Single threaded by nature; no benefit to multiple threads since no data will be available until the entire document has been read and parsed.
The character data of each url
element needs to be read.
Everything else can be ignored.
The getElementsByTagName() method in
Document gives us a quick list of all the
url
elements.
The XML parsing is so straight-forward it can be done inside one method. No extra class is required.
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import java.io.IOException;
import java.util.*;
import java.net.*;
public class WeblogsDOM {
public static String DEFAULT_URL
= "http://static.userland.com/weblogMonitor/logs.xml";
public static List listChannels() throws DOMException {
return listChannels(DEFAULT_URL);
}
public static List listChannels(String uri) throws DOMException {
if (uri == null) {
throw new NullPointerException("URL must be non-null");
}
org.apache.xerces.parsers.DOMParser parser
= new org.apache.xerces.parsers.DOMParser();
Vector urls = null;
try {
// Read the entire document into memory
parser.parse(uri);
Document doc = parser.getDocument();
NodeList logs = doc.getElementsByTagName("url");
urls = new Vector(logs.getLength());
for (int i = 0; i < logs.getLength(); i++) {
try {
Node element = logs.item(i);
Node text = element.getFirstChild();
String content = text.getNodeValue();
URL u = new URL(content);
urls.addElement(u);
}
catch (MalformedURLException e) {
// bad input data from one third party; just ignore it
}
}
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
return urls;
}
public static void main(String[] args) {
try {
List urls;
if (args.length > 0) {
try {
URL url = new URL(args[0]);
urls = listChannels(args[0]);
}
catch (MalformedURLException e) {
System.err.println("Usage: java WeblogsDOM url");
return;
}
}
else {
urls = listChannels();
}
Iterator iterator = urls.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
catch (/* Unexpected */ Exception e) {
e.printStackTrace();
}
} // end main
}% java WeblogsDOM
http://2020Hindsight.editthispage.com/
http://www.sff.net/people/mitchw/weblog/weblog.htp
http://nate.weblogs.com/
http://plugins.launchpoint.net
http://404.psistorm.net
http://home.att.net/~geek9000
http://daubnet.tzo.com/weblog
several hundred more...
Represents a complete element including its start-tag, end-tag, and content
Contains:
Element nodes
ProcessingInstruction nodes
Comment nodes
Text nodes
CDATASection nodes
EntityReference nodes
package org.w3c.dom;
public interface Element extends Node {
public String getTagName();
public NodeList getElementsByTagName(String name);
public NodeList getElementsByTagNameNS(String namespaceURI,
String localName);
public String getAttribute(String name);
public String getAttributeNS(String namespaceURI,
String localName);
public void setAttribute(String name, String value)
throws DOMException;
public void setAttributeNS(String namespaceURI,
String qualifiedName, String value) throws DOMException;
public void removeAttribute(String name) throws DOMException;
public void removeAttributeNS(String namespaceURI,
String localName) throws DOMException;
public Attr getAttributeNode(String name);
public Attr getAttributeNodeNS(String namespaceURI, String localName);
public Attr setAttributeNode(Attr newAttr) throws DOMException;
public Attr setAttributeNodeNS(Attr newAttr) throws DOMException;
public Attr removeAttributeNode(Attr oldAttr) throws DOMException;
}
import org.apache.xerces.parsers.DOMParser;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.IOException;
import org.apache.xml.serialize.*;
public class IDTagger {
int id = 1;
public void processNode(Node node) {
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element element = (Element) node;
String currentID = element.getAttribute("ID");
if (currentID == null || currentID.equals("")) {
element.setAttribute("ID", "_" + id);
id = id + 1;
}
}
}
// note use of recursion
public void followNode(Node node) {
processNode(node);
if (node.hasChildNodes()) {
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
followNode(children.item(i));
}
}
}
public static void main(String[] args) {
DOMParser parser = new DOMParser();
IDTagger iterator = new IDTagger();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document document = parser.getDocument();
iterator.followNode(document);
// now we serialize the document...
OutputFormat format = new OutputFormat(document);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(document);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE SONG SYSTEM "song.dtd">
<?xml-stylesheet type="text/css" href="song.css"?><!-- This should be a four digit year like "1999",
not a two-digit year like "99" --><SONG xmlns="http://www.cafeconleche.org/namespace/song" ID="_1" xmlns:xlink="http://www.w3.org/1999/xlink"> <TITLE ID="_2">Hot Cop</TITLE> <PHOTO ALT="Victor Willis in Cop Outfit" HEIGHT="200" ID="_3" WIDTH="100" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="hotcop.jpg" xlink:show="onLoad" xlink:type="simple"/> <COMPOSER ID="_4">Jacques Morali</COMPOSER> <COMPOSER ID="_5">Henri Belolo</COMPOSER> <COMPOSER ID="_6">Victor Willis</COMPOSER> <PRODUCER ID="_7">Jacques Morali</PRODUCER> <!-- The publisher is actually Polygram but I needed
an example of a general entity reference. --> <PUBLISHER ID="_8" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="http://www.amrecords.com/" xlink:type="simple"> A & M Records </PUBLISHER> <LENGTH ID="_9">6:20</LENGTH> <YEAR ID="_10">1978</YEAR> <ARTIST ID="_11">Village People</ARTIST> </SONG><!-- You can tell what album I was
listening to when I wrote this example -->DOM is for both input and output
New documents are created with a parser-specific API or JAXP
A serializer + output format converts the DOM to a byte stream
Creates new Document objects
Creates new DocType objects
Tests features supported by this implementation
package org.w3c.dom;
public interface DOMImplementation {
public boolean hasFeature(String feature, String version)
public DocumentType createDocumentType(String qualifiedName,
String publicID, String systemID, String internalSubset)
public Document createDocument(String namespaceURI,
String qualifiedName, DocumentType doctype)
throws DOMException
}
The Xerces-specific class that implements DOMImplementation
package org.apache.xerces.dom;
public class DOMImplementationImpl implements DOMImplementation {
public boolean hasFeature(String feature, String version)
public static DOMImplementation getDOMImplementation()
public DocumentType createDocumentType(String qualifiedName,
String publicID, String systemID, String internalSubset)
public Document createDocument(String namespaceURI,
String qualifiedName, DocumentType doctype)
throws DOMException
}
import java.math.BigInteger;
import java.io.*;
import org.w3c.dom.*;
import org.apache.xerces.dom.*;
public class FibonacciDOM {
public static void main(String[] args) {
try {
DOMImplementation impl
= DOMImplementationImpl.getDOMImplementation();
Document fibonacci
= impl.createDocument(null, "Fibonacci_Numbers", null);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
Element root = fibonacci.getDocumentElement();
for (int i = 1; i <= 25; i++) {
Element number = fibonacci.createElement("fibonacci");
number.setAttribute("index", Integer.toString(i));
Text text = fibonacci.createTextNode(low.toString());
number.appendChild(text);
root.appendChild(number);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
// Now the document has been created and exists in memory
}
catch (DOMException e) {
e.printStackTrace();
}
}
}
import java.math.BigInteger;
import java.io.*;
import org.w3c.dom.*;
import javax.xml.parsers.*;
public class FibonacciJAXP {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory
= DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
DOMImplementation impl = builder.getDOMImplementation();
Document fibonacci
= impl.createDocument(null, "Fibonacci_Numbers", null);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
Element root = fibonacci.getDocumentElement();
for (int i = 1; i <= 25; i++) {
Element number = fibonacci.createElement("fibonacci");
number.setAttribute("index", Integer.toString(i));
Text text = fibonacci.createTextNode(low.toString());
number.appendChild(text);
root.appendChild(number);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
// Now the document has been created and exists in memory
}
catch (DOMException e) {
e.printStackTrace();
}
catch (ParserConfigurationException e) {
System.err.println("You need to install a JAXP aware DOM implementation.");
}
}
}
The process of taking an in-memory DOM tree and converting it to a stream of characters that can be written onto an output stream
Not a standard part of DOM Level 2
The public interface DOMSerializer public interface Serializer public abstract class BaseMarkupSerializer
extends Object
implements DocumentHandler, org.xml.sax.misc.LexicalHandler, DTDHandler,
org.xml.sax.misc.DeclHandler, DOMSerializer, Serializer public class HTMLSerializer
extends BaseMarkupSerializer public final class TextSerializer
extends BaseMarkupSerializer public final class XHTMLSerializer
extends HTMLSerializer public final class XMLSerializer
extends BaseMarkupSerializerorg.apache.xml.serialize package:
import java.math.BigInteger;
import java.io.*;
import org.w3c.dom.*;
import org.apache.xerces.dom.*;
import org.apache.xml.serialize.*;
public class FibonacciDOMSerializer {
public static void main(String[] args) {
try {
DOMImplementation impl
= DOMImplementationImpl.getDOMImplementation();
Document fibonacci
= impl.createDocument(null, "Fibonacci_Numbers", null);
BigInteger low = BigInteger.ONE;
BigInteger high = BigInteger.ONE;
Element root = fibonacci.getDocumentElement();
for (int i = 1; i <= 25; i++) {
Element number = fibonacci.createElement("fibonacci");
number.setAttribute("index", Integer.toString(i));
Text text = fibonacci.createTextNode(low.toString());
number.appendChild(text);
root.appendChild(number);
BigInteger temp = high;
high = high.add(low);
low = temp;
}
try {
// Now that the document is created we need to *serialize* it
OutputFormat format = new OutputFormat(fibonacci);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(fibonacci);
}
catch (IOException e) {
System.err.println(e);
}
}
catch (DOMException e) {
e.printStackTrace();
}
}
}
<?xml version="1.0" encoding="UTF-8"?>
<Fibonacci_Numbers><fibonacci index="0">0</fibonacci><fibonacci index="1">1</fibonacci><fibonacci index="2">1</fibonacci><fibonacci index="3">2</fibonacci><fibonacci index="4">3</fibonacci><fibonacci index="5">5</fibonacci><fibonacci index="6">8</fibonacci><fibonacci index="7">13</fibonacci><fibonacci index="8">21</fibonacci><fibonacci index="9">34</fibonacci><fibonacci index="10">55</fibonacci><fibonacci index="11">89</fibonacci><fibonacci index="12">144</fibonacci><fibonacci index="13">233</fibonacci><fibonacci index="14">377</fibonacci><fibonacci index="15">610</fibonacci><fibonacci index="16">987</fibonacci><fibonacci index="17">1597</fibonacci><fibonacci index="18">2584</fibonacci><fibonacci index="19">4181</fibonacci><fibonacci index="20">6765</fibonacci><fibonacci index="21">10946</fibonacci><fibonacci index="22">17711</fibonacci><fibonacci index="23">28657</fibonacci><fibonacci index="24">46368</fibonacci><fibonacci index="25">75025</fibonacci></Fibonacci_Numbers>package org.apache.xml.serialize;
public class OutputFormat extends Object {
public OutputFormat()
public OutputFormat(String method,
String encoding, boolean indenting)
public OutputFormat(Document doc)
public OutputFormat(Document doc,
String encoding, boolean indenting)
public String getMethod()
public void setMethod(String method)
public String getVersion()
public void setVersion(String version)
public int getIndent()
public boolean getIndenting()
public void setIndent(int indent)
public void setIndenting(boolean on)
public String getEncoding()
public void setEncoding(String encoding)
public String getMediaType()
public void setMediaType(String mediaType)
public void setDoctype(String publicID, String systemID)
public String getDoctypePublic()
public String getDoctypeSystem()
public boolean getOmitXMLDeclaration()
public void setOmitXMLDeclaration(boolean omit)
public boolean getStandalone()
public void setStandalone(boolean standalone)
public String[] getCDataElements()
public boolean isCDataElement(String tagName)
public void setCDataElements(String[] cdataElements)
public String[] getNonEscapingElements()
public boolean isNonEscapingElement(String tagName)
public void setNonEscapingElements(String[] nonEscapingElements)
public String getLineSeparator()
public void setLineSeparator(String lineSeparator)
public boolean getPreserveSpace()
public void setPreserveSpace(boolean preserve)
public int getLineWidth()
public void setLineWidth(int lineWidth)
public char getLastPrintable()
public static String whichMethod(Document doc)
public static String whichDoctypePublic(Document doc)
public static String whichDoctypeSystem(Document doc)
public static String whichMediaType(String method)
}Latin-1 encoding
Indentation
Word wrapping
Document type declaration
try {
// Now that the document is created we need to *serialize* it
OutputFormat format = new OutputFormat(fibonacci, "8859_1", true);
format.setLineSeparator("\r\n");
format.setLineWidth(72);
format.setDoctype(null, "fibonacci.dtd");
XMLSerializer serializer = new XMLSerializer(System.out, format);
serializer.serialize(root);
}
catch (IOException ex) {
System.err.println(ex);
}Question: Why won't this let us add an xml-stylesheet directive?
<?xml version="1.0" encoding="8859_1"?>
<!DOCTYPE Fibonacci_Numbers SYSTEM "fibonacci.dtd">
<Fibonacci_Numbers>
<fibonacci index="0">0</fibonacci>
<fibonacci index="1">1</fibonacci>
<fibonacci index="2">1</fibonacci>
<fibonacci index="3">2</fibonacci>
<fibonacci index="4">3</fibonacci>
<fibonacci index="5">5</fibonacci>
<fibonacci index="6">8</fibonacci>
<fibonacci index="7">13</fibonacci>
<fibonacci index="8">21</fibonacci>
<fibonacci index="9">34</fibonacci>
<fibonacci index="10">55</fibonacci>
<fibonacci index="11">89</fibonacci>
<fibonacci index="12">144</fibonacci>
<fibonacci index="13">233</fibonacci>
<fibonacci index="14">377</fibonacci>
<fibonacci index="15">610</fibonacci>
<fibonacci index="16">987</fibonacci>
<fibonacci index="17">1597</fibonacci>
<fibonacci index="18">2584</fibonacci>
<fibonacci index="19">4181</fibonacci>
<fibonacci index="20">6765</fibonacci>
<fibonacci index="21">10946</fibonacci>
<fibonacci index="22">17711</fibonacci>
<fibonacci index="23">28657</fibonacci>
<fibonacci index="24">46368</fibonacci>
<fibonacci index="25">75025</fibonacci>
</Fibonacci_Numbers>
import org.apache.xerces.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.*;
import java.io.*;
import org.apache.xerces.dom.*;
import org.apache.xml.serialize.*;
public class DOMPrettyPrinter {
public static void main(String[] args) {
DOMParser parser = new DOMParser();
for (int i = 0; i < args.length; i++) {
try {
// Read the entire document into memory
parser.parse(args[i]);
Document document = parser.getDocument();
OutputFormat format
= new OutputFormat(document, "UTF-8", true);
format.setLineSeparator("\r\n");
format.setIndenting(true);
format.setIndent(2);
format.setLineWidth(72);
format.setPreserveSpace(false);
XMLSerializer serializer
= new XMLSerializer(System.out, format);
serializer.serialize(document);
}
catch (SAXException e) {
System.err.println(e);
}
catch (IOException e) {
System.err.println(e);
}
}
} // end main
}<?xml version="1.0" encoding="UTF-8"?>
<!-- <!DOCTYPE foo SYSTEM "http://msdn.microsoft.com/xml/general/htmlentities.dtd"> -->
<weblogs>
<log>
<name>MozillaZine</name>
<url>http://www.mozillazine.org</url>
<changesUrl>http://www.mozillazine.org/contents.rdf</changesUrl>
<ownerName>Jason Kersey</ownerName>
<ownerEmail>kerz@en.com</ownerEmail>
<description>THE source for news on the Mozilla Organization.
DevChats, Reviews, Chats, Builds, Demos, Screenshots, and more.</description>
<imageUrl/>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/kerz@en.com.gif</adImageUrl>
</log>
<log>
<name>SalonHerringWiredFool</name>
<url>http://www.salonherringwiredfool.com/</url>
<ownerName>Some Random Herring</ownerName>
<ownerEmail>salonfool@wiredherring.com</ownerEmail>
<description/>
</log>
<log>
<name>Scripting News</name>
<url>http://www.scripting.com/</url>
<ownerName>Dave Winer</ownerName>
<ownerEmail>dave@userland.com</ownerEmail>
<description>News and commentary from the cross-platform scripting community.</description>
<imageUrl>http://www.scripting.com/gifs/tinyScriptingNews.gif</imageUrl>
<adImageUrl>http://static.userland.com/weblogMonitor/ads/dave@userland.com.gif</adImageUrl>
</log>
<log>
<name>SlashDot.Org</name>
<url>http://www.slashdot.org/</url>
<ownerName>Simply a friend</ownerName>
<ownerEmail>afriendofweblogs@weblogs.com</ownerEmail>
<description>News for Nerds, Stuff that Matters.</description>
</log>
</weblogs>
Using the DOM to write documents automatically maintains well-formedness constraints
Validity is not automatically maintained.
This presentation: http://www.cafeconleche.org/slides/sd2005west/saxdom
Elliotte Rusty Harold
Addison Wesley, 2002
Chapters 9-13:
Chapter 9, The Document Object Model: http://www.cafeconleche.org/books/xmljava/chapters/ch09.html
Chapter 10, Creating New XML Documents with DOM: http://www.cafeconleche.org/books/xmljava/chapters/ch10.html
Chapter 11, The Document Object Model Core: http://www.cafeconleche.org/books/xmljava/chapters/ch11.html
Chapter 12, The DOM Traversal Module: http://www.cafeconleche.org/books/xmljava/chapters/ch12.html
Chapter 13, Output from DOM: http://www.cafeconleche.org/books/xmljava/chapters/ch13.html
XML in a Nutshell, third edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2004
ISBN 0-596-00764-7
DOM Level 2 Core Specification: http://www.w3.org/TR/DOM-Level-2-Core/
DOM Level 2 Traversal and Range Specification: http://www.w3.org/TR/DOM-Level-2-Traversal-Range/
This presentation: http://www.cafeconleche.org/slides/sd2005west/xmlfundamentals
XML in a Nutshell, third edition
Elliotte Rusty Harold and W. Scott Means
O'Reilly & Associates, 2004
ISBN 0-596-00764-7
 XML 1.1 Bible
XML 1.1 Bible
Elliotte Rusty Harold
Wiley, 2004
ISBN 0-7645-4986-3
