DRAFT,
15. Build on top of structures, not syntax
Entity references, CDATA sections, character references, empty-element tags and the like are just syntax sugar. They make it a little easier to include certain hard-to-type constructs in XML documents. They do not in any way change a document's information content. Many parsers will not even tell you whether such syntax sugar was used or not. Your documents should convey the same meaning if each of these is replaced with an equivalent representation of the same content.
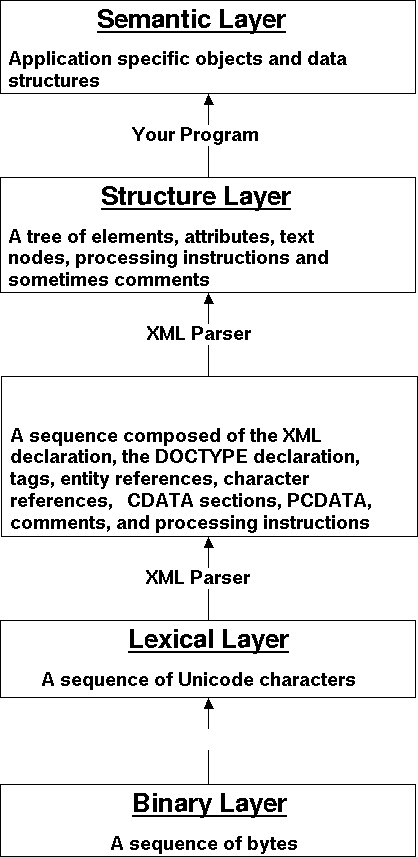
XML processing can be thought of as a five layer stack as shown in Figure 15-1. Each layer of data is processed to generate the successively more abstract, more useful layer that follows it. Binary data is converted into characters. Characters are converted into syntax. Syntax is processed to form structures. Finally structures are interpreted to form semantics. Each layer has its place and each layer is necessary. However, it's important not to mix them. A program processing XML can safely operate on only a single layer. Programs that attempt to operate in multiple layers simultaneously risk corrupting the clean, well-formed nature of XML.
Normally processing begins with binary data that is translated into Unicode text according to a particular encoding. It be necessary to decrypt, decompress, or otherwise transform the binary data before passing it to the parser. It may also be necessary to first strip off and interpret metadata from the binary stream to locate the XML document. For example when reading an XML document from a web server over a socket, you would have to read and remove the HTTP header while storing the information the header contained about the document's content type and encoding. (See Item 45.) Once the beginning of the document has been located, the parser will read ahead far enough to detect the encoding. Once it's confident it knows the encoding, it backs up to the beginning of the document and begins converting bytes into Unicode characters. This may happen before the XML parser begins its work, and is technically not a part of XML, though for convenience most XML parsers at least have options to perform some of this work, especially encoding detection. In Java the APIs for the binary layer are java.io.InputStream and java.io.OutputStream.
The Unicode characters form the lexical layer. In Java the APIs for this layer are java.io.Reader and java.io.Writer. These are not specifically XML APIs because this data is not necessarily XML until well-formedness has been verified. The only well-formedness check that can be performed at this level is verifying that the characters are all legal in an XML document; for example, that there are no vertical tabs or unmatched halves of surrogate pairs in the data stream.
The parser then reads the raw Unicode characters to recognize the low-level syntax of an XML document: tags, text, entity references, CDATA section delimiters, and so forth.1 This is the layer where most of the well-formedness rules defined by XML's BNF grammar are checked. There are very few existing APIs that truly expose the constructs in this layer, partially because it's not always recognized as a separate layer and partially because few programs really need to operate at this level, mostly just source-code-level XML editors. However, a number of APIs have dug holes for themselves by mixing a few pieces of this layer in with the next higher structure layer.
The parser combines these low-level syntax items into higher-level information structures: elements, attributes, text nodes, processing instructions, and so forth. During this process, the parser checks the XML well-formedness constraints that the XML specification calls out separately because they cannot be encoded in the BNF grammar. The most important of these is that each start-tag has a matching end-tag. At this point many of the details about exactly how the information was encoded are deliberately lost. For instance, the parser will merge the text inside a CDATA section with the text outside the CDATA section without in any way noting which characters came from inside and which from outside. Most common XML APIs operate primarily at the structure level. These include SAX, DOM, JDOM, and XOM. Both DOM and SAX parsers can optionally mix in a lot of syntax layer information, but neither is required to support this.
Finally, the parser passes the information about these high-level structures to the client program that invoked the parser. This client program then acts on these structures to produce semantic objects and data structures that are appropriate for its local process. This is the domain of data binding APIs such as JAXB, Castor and Zeus. These attempt to completely hide the fact that the data came from XML and treat it as some kind of programming object.
Figure 15-1: The 5-layer XML processing model
A clean program that processes XML works exclusively with a single layer. Almost always the appropriate layer to work with is the structure layer. In this layer, a well-designed program exclusively processes the elements, attributes, text, and other post-parse content. It is responsible for transforming from the structure layer to the semantic layer. It does not involve itself with syntactic issues such as whether a dollar sign was typed as $, $, $, $, or even <![CDATA[$]]>. It has even less interest in lexical and binary layer issues such as which character encoding the document uses. The parser handles all of this before the program ever sees the document.
Note
There is perhaps one exception to this rule. Source code level, generic XML editors such as XML Spy, XED, or jEdit do need access to the syntax layer in order to preserve the appearance of the document. For instance, they do not want to change a named entity reference to a numeric character reference or vice versa. They may even allow for partially malformed documents because users may want to type content after start-tags before they type the end-tags. Thus these tools tend to operate on the syntax layer rather than the structure layer. However, XML editors are a very special case in the realm of XML software. The very unusual needs of these tools should not influence the design of other, more conventional applications.
End Note
Particularly common layer-confusions include:
Treating empty-element tags differently from the equivalent start-tag end-tag pairs
Using CDATA sections as pseudo-elements that contain malformed markup
Considering character and entity references as somehow different from their replacement text
Skipping or forbidding the document type declaration
Let's explore some of the problems that commonly arise as a result of these layer confusions.
Developers trained in database theory often latch onto the empty-element tag (e.g. <para/>) as a way of indicating a null value, which they rightly consider to be distinct from 0 or the empty string. From their perspective this makes sense. <para>AA</para> is a para element whose value is the string "AA". <para>A</para> is a para element whose value is the string "A". <para></para> is a para element whose value is the empty string. Finally <para/> is the para element whose value is null.
This is all perfectly sensible, but it does not reflect the way XML parsers actually behave. An XML parser will produce exactly the same data from <para></para> as from <para/>. There is no detectable difference between the two. They both have the same value, and that value is the empty string, not null.
The right way to indicate a null element is by attaching an extra attribute to the element. In particular the W3C XML Schema Language defines an attribute for exactly this purpose, xsi:nil. The customary xsi prefix is mapped to the namespace URL http://www.w3.org/2001/XMLSchema-instance, and as always the prefix can change as long as the URL stays the same. For example, this para element genuinely has a null value:
<para xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:nil="true"/>A schema aware parser may actually report the value of this element as being null. However it's more likely you'll have to explicitly test each empty element for the presence of an xsi:nil attribute. For example, in DOM to convert an Element object known to be empty to a string, you might write code something like this:
String elementText;
String isNil = element.getAttributeNS(
"http://www.w3.org/2001/XMLSchema-instance", nil);
if ("true".equals(isNil)) {
elementText = null;
}
else { // either there is no xsi:nil attribute or its value is false
elementText = "";
}It is an error to set xsi:nil="true" on a non-empty element. However, the difference between two tags and one is not important. This para element is also nil:
<para xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:nil="true"></para>CDATA sections are probably the most frequently abused drugs in the XML pharmacy. The normal reason for this abuse is to embed non-well-formed HTML inside an XML document. For example, the description element in a catalog entry might contain an entire web page for a product:
<Vehicle>
<price>30000</price>
<inStock>4</inStock>
<color>black</color>
<description><![CDATA[
<html>
<title>The G2 SUV</title>
<body>
<img src=g2suv.jpg height=100 width=100>
The G2 Sport Utility Vehicle is one of our best-selling models.
<p>
It's built on a truck base for all the stability of a pickup
driving down a bumpy country road.
<p>
It gets an astonishing eight miles to the liter.
<p>
<hr>
<a href=G3SUV.html>Next Car</a>
</body>
</HTML>
]]></description>
</Vehicle>Given this structure, it's temptingly easy to write code that extracts the contents of the description element and writes the raw text into a file or onto a network socket that expects to receive HTML.
Even worse is the case where the CDATA section is not the exclusive contents of an element, but is instead one of several children, so that it becomes almost a pseudo-element. For example, imagine that the above catalog entry did not contain a separate description element child, just a CDATA section holding HTML:
<Vehicle>
<price>30000</price>
<inStock>4</inStock>
<color>black</color>
<![CDATA[
<html>
<title>The G2 SUV</title>
<body>
<img src=g2suv.jpg height=100 width=100>
The G2 Sport Utility Vehicle is one of our best-selling models.
<p>
It's built on a truck base for all the stability of a pickup
driving down a bumpy country road.
<p>
It gets an astonshing eight miles to the liter.
<p>
<hr>
<a href=G3SUV.html>Next Car</a>
</body>
</HTML>
]]>
</Vehicle>This sort of structure causes major problems for all sorts of XML tools. It severely limits the validation that can be performed with a DTD or a schema. It is extremely difficult to transform properly with XSLT. DOM parsers may or may not separate out the CDATA sections from the surrounding text, and SAX parsers might not even notice the CDATA sections.
The solution in both cases is simple: make the HTML well-formed and treat it as an html element rather than raw text:
<Vehicle>
<price>30000</price>
<inStock>4</inStock>
<color>black</color>
<html>
<title>The G2 SUV</title>
<body>
<img src="g2suv.jpg" height="100" width="100" />
<p>
The G2 Sport Utility Vehicle is one of our best-selling models.
</p>
<p>
It's built on a truck base for all the stability of a pickup
driving down a bumpy country road.
</p>
<p>
It gets an astonishing eight miles to the gallon.
</p>
<hr />
<a href="G3SUV.html">Next Car</a>
</body>
</html>
</Vehicle>If you want to get the text from the HTML, you'll have to serialize the root html element, just like you'd serialize any other XML element. In DOM3 you can use the DOMWriter class.
The general rule for CDATA sections is that nothing should change if the CDATA section is replaced by its content text with all < and &'s suitably escaped. CDATA sections are meant as a convenience for human authors, especially ones writing books about markup like the one you hold in your hands right now. They are not meant to replace elements for indicating the structure and semantics of content or as a means of hiding malformed markup inside an XML document.
Entity and character references are also often abused. Many XML parser APIs sometimes let you see which entity any given character came from (though not all do, and in SAX and DOM this ability is not implemented by all parsers). However you shouldn't rely on this, and no parsers will tell you whether each character came from raw text or a character reference.
The classic example of what not to do here is mix XML's escaping mechanisms with your application's escaping mechanism. For instance, an application could specify that a string of text beginning with a literal dollar sign ($, Unicode character 36) is a variable reference. For example, this Para element includes a variable reference:
<Para>Hello $name</Para>
This is fine. However, it does require some means to escape the dollar sign when it's used as just a dollar sign. I've occasionally seen applications that attempt to use XML character references for such escaping. For example, this would not be a variable reference:
<Para>Hello $name</Para>
This is a bad design that makes it impossible to parse these documents correctly with standard APIs like SAX and DOM or standard parsers like Crimson and Ælfred because they won't distinguish between a literal $ and $. Instead a custom parser is required. This makes development much harder than it needs to be.
The mistake is tying application level semantics (how to tell what's a variable and what isn't) to syntactic aspects of the document that the parser hides. The correct approach is to define a new escaping mechanism that's visible above the XML parser layer instead of below it. For example, you could declare that all variables begin with a $, whichever way that character was typed. However, a double dollar sign would be converted to a single plain text dollar sign. For example, these Para elements would both contain a variable reference:
<Para>Hello $name</Para> <Para>Hello $name</Para>
However, these two would not:
<Para>Hello $$name</Para> <Para>Hello $$name</Para>
Design your processing software and XML applications so that they only depend on those aspects of XML that parsers reliably report: element boundaries, text content, attribute values, and processing instructions. Do not write markup that depends on syntax that the parser may resolve before reporting to the client application: CDATA sections, entity references, attribute order, character references, comments, whether attributes are defaulted from the DTD or included in the instance document, etc. You may indeed be able to write software that supports such lower level syntax using one particular parser or API. However, you won't be able to validate it with standard schema languages, and I guarantee that you'll confuse document authors who won't always follow your rules. Worst of all, many and perhaps most XML parsers and APIs won't be able to fully process your documents, even if you can. Build applications on top of the structure layer, and let the parser do the hard work of sorting out the syntax.
1In a traditional compiler we'd say this step is performed by the lexer rather than the parser. However, in XML the distinction between lexers and parsers is rarely made, and lexers are not normally available separately from parsers.